






 本文探讨了在使用Python模拟豆瓣登录过程中遇到的参数错误、乱码问题及登录页面定位问题,通过调整headers中的Accept-Encoding和Host字段,解析了如何正确发送FormData请求并获取预期页面内容。
本文探讨了在使用Python模拟豆瓣登录过程中遇到的参数错误、乱码问题及登录页面定位问题,通过调整headers中的Accept-Encoding和Host字段,解析了如何正确发送FormData请求并获取预期页面内容。
豆瓣登录页面

开发者模式下,输入账号和密码,点击登录豆瓣,可得到一个post请求的网址,如图:
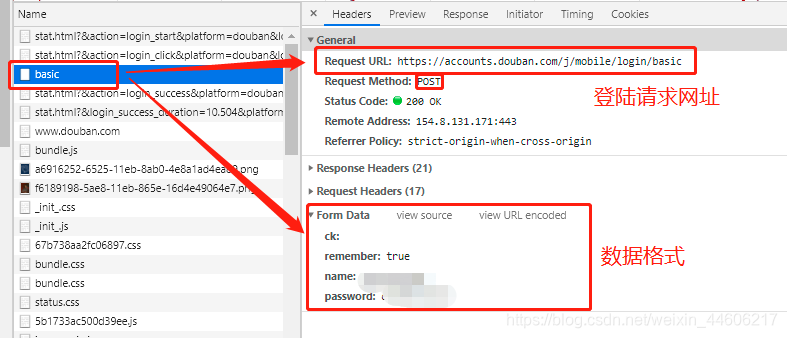
登录请求网址:https://accounts.douban.com/j/mobile/login/basic
post请求数据格式即为 Form Data
模拟登录代码如下:
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36",
}
login_url = 'https://accounts.douban.com/j/mobile/login/basic'
data = {
'ck':'',
'remember':'true',
'name':'账号',
'password':'密码'
}
session = requests.Session()
login_res = session.post(login_url,data=data,headers=headers)
# 登录后要请求的网址
url = 'https://www.douban.com/group/search?cat=1013&q=找房'
# 利用登录后的session请求网址
res = session.get(url, headers=headers)
print('res:',res.text)此时可成功得到数据。
遇到的问题及解决办法:
1:代码请求login_url时出现“参数错误”,但postman请求可正常返回数据。
解决方法:代码中尝试补全headers。
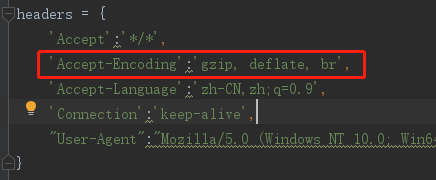
2:补全headers后,得到的数据是乱码。
解决方法:查看headers中是否含有 Accept-Encoding 字段,将此字段注释或删除。
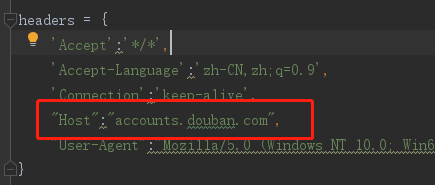
3:请求得到的页面是首页,非自己请求的页面。
解决方法:查看headers中是否含有 Host 字段,将此字段注释或删除。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









