







1.基础性知识介绍
1.1 损失函数
-
梯度下降算法和正规方程都是作为优化算法,来对损失函数进行优化的(获取损失函数最小值)
- 损失函数:损失函数即为真实值与预测值之间的误差大小,通过梯度下降算法来对损失函数进行优化,使得损失结果变得最小
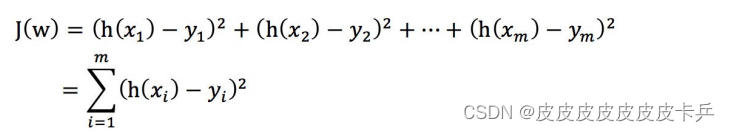
如上图所示,即为最小二差法就是用来估计线性回归的损失函数。
1.2 梯度下降算法介绍
梯度下降法的基本思想可以类⽐为⼀个下⼭的过程【这种理解是很形象的】。
假设这样⼀个场景:⼀个⼈被困在⼭上,需要从⼭上下来(i.e. 找到⼭的最低点,也就是⼭⾕)。但此时⼭上的浓雾很⼤,导致可视度很低。因此,下⼭的路径就⽆法确定,他必须利⽤⾃⼰周围的信息去找到下⼭的路径。这个时候,他就可以利⽤梯度下降算法来帮助⾃⼰下⼭。
具体来说就是,以他当前的所处的位置为基准,寻找这个位置最陡峭的地⽅,然后朝着⼭的⾼度下降的地⽅⾛【函数的斜率】,然后每⾛⼀段距离【斜率*步长】,都复采⽤同⼀个⽅法,最后就能成功的抵达⼭⾕。
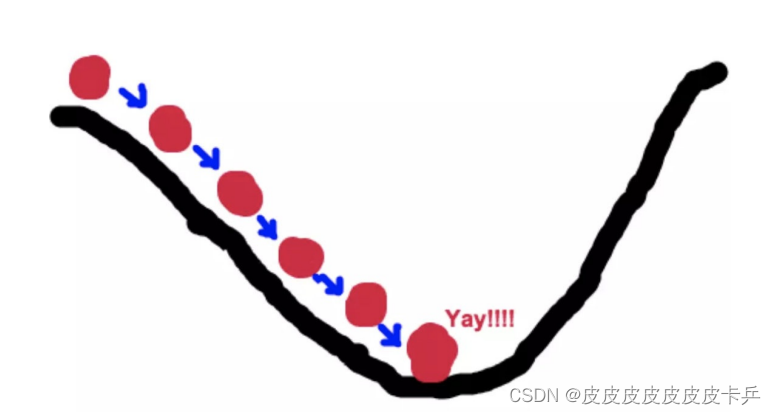
梯度下降的基本过程就和下⼭的场景很类似。⾸先,我们有⼀个可微分的函数。这个函数就代表着⼀座⼭。我们的⽬标就是找到这个函数的最⼩值,也就是⼭底。
1.3 多参数函数举例


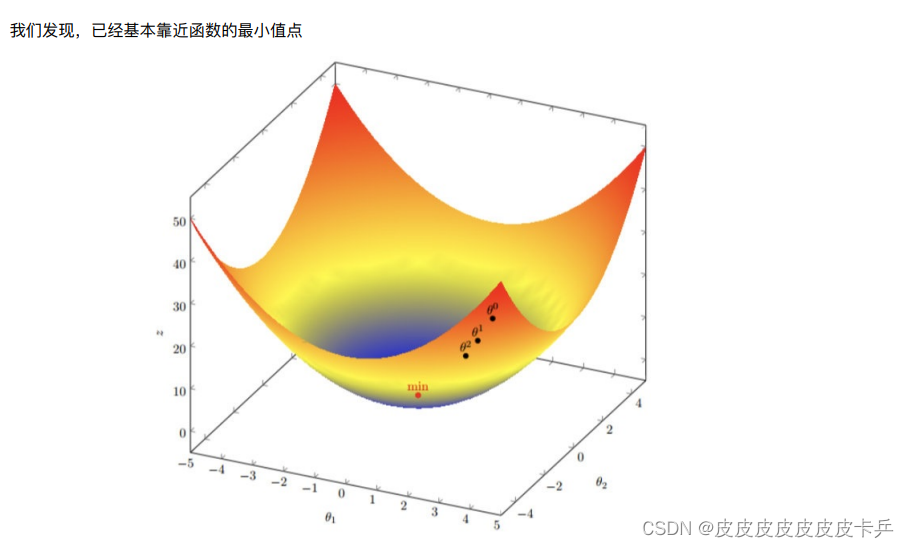
- 梯度是微积分中⼀个很重要的概念
- 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率;
- 在多变量函数中,梯度是⼀个向量,向量有⽅向,梯度的⽅向就指出了函数在给定点的上升最快的⽅向;
我们需要到达⼭底,就需要在每⼀步观测到此时最陡峭的地⽅,梯度就恰巧告诉了我们这个⽅向。梯度的⽅向是函数在给定点上升最快的⽅向,那么梯度的反⽅向就是函数在给定点下降最快的⽅向,这正是我们所需要的。
2. 梯度下降算法具体实现
2.1 算法公式
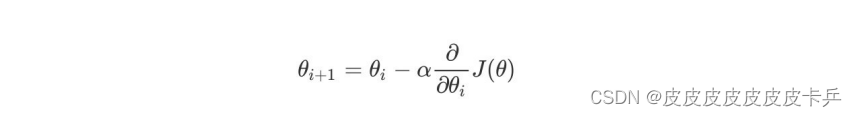
其中, θi代表损失函数此时的损失函数参数(要求的就是他的最小值),α在梯度下降算法中被称作为学习率或者步⻓,意味着我们可以通过α来控制每⼀步⾛的距离,后面的是求出下一步的前进方向
2.2 算法推倒流程
-
先决条件: 确认优化模型的假设函数和损失函数。

-
算法相关参数初始化
- 主要是初始化θ , θ …, θ ,算法终⽌距离ε以及步⻓α 。在没有任何先验知识的时候,我喜欢将所有的θ 初始化为0, 将步⻓初始化为1。在调优的时候再 优化。
-
算法过程

2.3 补充说明
梯度前加负号:
梯度前加⼀个负号,就意味着朝着梯度相反的⽅向前进!我们在前⽂提到,梯度的⽅向实际就是函数在此点上升最快的⽅向!⽽我们需要朝着下降最快的⽅向⾛,⾃然就是负的梯度的⽅向,所以此处需要加上负号
实际上整个过程就是通过初始参数-梯度乘以补偿达到损失函数最小值是的模型参数的过程
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











