







预定类
以餐厅(预定座位)为例子讲解
管理类解题步骤
- Clarify
- What
- 桌子的规格有什么不一样?
- 吧台里party有什么区别?
- How
- 怎么样收费?
- 是否支持预约?暂时不支持
- 是否支持外卖?如果支持,每个order就要区分一下是Dine-in还是Dine-out。暂时不支持
- What
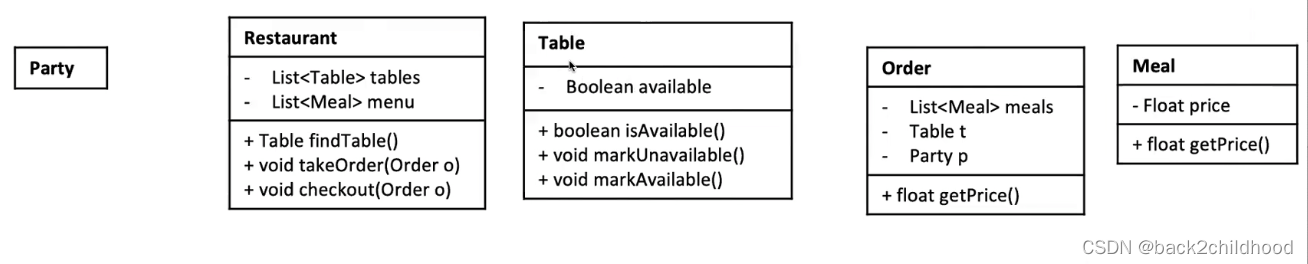
- Core Object
- 列出core object
Party->Restaurant->Table->Order->Meal - 考虑object之间的对应关系
将Table与Meal的对应关系存放在Order中

- 列出core object
- Use Case:以餐厅为主体进行思考
- Find table
- Take Order
- Checkout
- Class
- Find table
- Restaurant find an available table, an change the table to be unavailable
- 此处支持拼桌吗?不支持,因为table是boolean类型,只能标志两种状态。可以在party中加入
int size,并将table改为int类型,当被party占用了就减去party的大小
- Take Order
- Restaurant takes an order
- Checkout
- Restaurant checks out a table/order, mark the table available again
- calculate order price
- Find table
将管理类修改为预定类
思路
- What
- 考虑预定的东西。比如预定餐厅,要考虑预定的座位/人数
- Use Case:主要有以下三个情况:Search / Select / Cancel
- 流程
Search criteria --input–> Search() --return–> List<Result> ----> Select() --result–> Receipt
- 流程
修改
- search criteria
- 人数:假设无拼桌,桌子一样大,不会有超过桌子大小的人数
- 日期:是否允许预定多日后的?允许
- 时间:是否所有时间都允许预定?24/7
- select
- 可以预定:直接进入confirm阶段
- 不能预定:Throw exception / Show message
Pair<Table, Timeslot> findTableForReservation(Time slot) throws NoTableForReservationExceptionvoid confirmReservation(Pair<Table, Timeslot> reservation)
- cancel
- restaurant takes a cancel reservation request, and ask the table to free that timeslot.
结果
Table和Party为静态属性,Order为动态属性

其他问题
- how to know if a table is open for reservation for a timesslot?
预定时参数不写时间点timeSlot,而改为时间段timePeriod
LRU Cache
最近最少使用到的(least recently used),缓存每次都淘汰最早一次使用的记录。

使用hash表保证O(1)的时间复杂度内就能访问到该元素,使用双向链表维护他们最早使用的元素,保证每次弹出时都是队头或队尾的元素。















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









