







Long-Short Temporal Co-Teaching for Weakly Supervised Video Anomaly Detection 论文阅读
文章信息:

发表于:ICME 2023(CCF B会)
原文链接:https://arxiv.org/pdf/2303.18044.pdf
源码:https://github.com/shengyangsun/LSTC_VAD
Abstract
弱监督视频异常检测(WSVAD)是一个具有挑战性的问题,旨在仅利用视频级别的标注来学习VAD模型。在这项工作中,我们提出了一种长短时序协同教学(LSTC)方法来解决WS-VAD问题。它构建了两个基于管状体的时空transformer
网络,分别从短期和长期视频剪辑中进行学习。每个网络都根据基于多实例学习(MIL)的排序损失进行训练,当剪辑级别的伪标签可用时,还会使用交叉熵损失。采用协同教学策略来训练这两个网络。也就是说,从每个网络生成的剪辑级别伪标签被用来在下一轮训练中监督另一个网络,两个网络交替迭代地学习。我们提出的方法能够更好地处理持续时间不同的异常以及微妙的异常。在三个公共数据集上进行的大量实验表明,我们的方法优于最先进的WS-VAD方法。代码可在https://github.com/shengyangsun/LSTC VAD获取。
I. INTRODUCTION
视频异常检测(VAD)旨在检测视频中的异常事件。这项任务因在安全监控、事故预测和证据调查等方面的重要性而引起了广泛的研究兴趣。大多数先前的研究集中于单类别分类范式,即仅使用正常视频学习VAD模型,并将那些偏离正常模式的视频识别为异常。然而,由于现实场景的复杂性和多样性,不可能考虑所有正常模式,因此这些方法容易产生误报警情。最近,弱监督视频异常检测(WSVAD)也受到了关注。它从带有视频级别标签的正常和异常视频中学习。开发的WS-VAD方法在轻量级标注负担的成本下表现出比无监督对应方法更优异的性能。
然而,有两个关键问题需要得到有效解决,以实现精确的WS-VAD。
1)如何利用视频级别标签来识别异常视频中可能被正常剪辑淹没的异常事件?
2)如何全面捕捉对于区分异常事件至关重要的空间和时间上下文?
为了解决第一个问题,已经开发了各种方法,包括基于多实例学习(MIL)的技术[3]、伪标签与标签噪声减少[6]或自训练[4]、[5]技术。
对于第二个问题,常用的方法包括预训练的时空特征编码器,如C3D [7]和I3D [8]。此外,空间-时间双分支网络[9]、连续采样策略[4]和自注意力或变换器技术[5]、[10]已进一步应用于捕捉长距离依赖关系。
在这项工作中,我们提出了一种新的WS-VAD方法,独特地解决了上述问题。我们的方法受到以下异常事件中观察到的特征的启发:
1)异常事件的持续时间变化很大,可能持续一个或多个连续的剪辑。
2)异常事件可能仅在许多监控视频的部分区域中占据很小的比例。
因此,我们选择管状体(管是一个剪辑区域)作为令牌,并构建两个空间-时间变换网络,分别为短期和长期剪辑序列回归异常分数。每个网络生成的伪标签进一步用于在下一轮训练中监督另一个网络。
我们的方法与其他方法的区别在于以下几个方面:
- 我们构建基于管状体的时空transformer网络来彻底挖掘空间和时间上下文。尽管管状体在最近的视频transformer中变得普遍[21],[22],但大多数WS-VAD方法[3]–[5],[10]仍然利用剪辑级别的特征进行异常检测。与它们相比,基于管状体的方法可以以更精细的粒度捕捉特征,从而更精确地检测到微妙的异常。
- 我们采用协同教学策略交替迭代地训练短期和长期网络。这两个网络可以明确地从持续时间不同的异常事件中学习。此外,与最近WS-VAD方法[4],[5]中使用的自训练策略相比,我们的协同教学策略可以更好地应对伪标签中的大量噪声,并进一步提升两个网络的性能。
- 对三个公共数据集进行的实验表明,所提出的方法优于最先进的WSVAD方法。可视化结果显示,通过协同教学学习的短期和长期网络比独立的网络更准确地聚焦于异常区域。
II. RELATED WORK
A. Weakly Supervised Video Anomaly Detection
弱监督视频异常检测依赖于视频级别标签来学习VAD模型。先前研究的一个研究方向将这项任务规定为多实例学习(MIL)问题。除了MIL排名损失外,还提出了各种正则化损失。例如,Sultani等人[3]施加了稀疏性和平滑性约束,Zhang等人[11]定义了内部袋损失,Wan等人[12]设计了一个动态MIL损失以及一个中心损失来规范学习的特征空间。与此同时,另一个研究方向将WS-VAD形式化为一个监督学习任务,直接将视频级别标签作为剪辑级别的伪标签。为了减轻异常视频中包含的标签噪声,Zhong等人[6]提出了一个图卷积网络,而Zaheer等人[13]定义了一个基于聚类的损失。
最近,几项最先进的研究作品[4],[5]将这两个研究方向结合起来。它们首先基于MIL框架构建了一个VAD模型,以生成剪辑级别的伪标签,然后使用生成的标签来监督VAD模型的后续训练。通过自训练策略,噪声伪标签和VAD模型交替迭代地被精炼。然而,简单地利用伪标签并不是对于具有各种持续时间异常的数据集(如UCF-Crime)的高效策略。因此,我们提出了一种协同教学策略,交替学习两个VAD模型,通过这种方式,噪声伪标签可以更有效地清除,并且两个模型的判别能力得到了显著提升。
B. Self-training and Co-training Strategies
最近,自训练策略已经被应用于无监督[14],[15]和弱监督[4],[5]的VAD任务中。它在伪标签步骤和VAD模型训练步骤之间交替进行,以迭代地提升模型的性能。在自训练中,只维护一个单一模型,这可能会导致在具有不同持续时间异常的大规模数据集上性能下降。相比之下,共同训练,也称为协同教学[16],是一种新的学习范式,同时训练两个模型,并让它们相互教导。由于不同的学习和样本选择偏差,共同训练的模型对严重的标签噪声更具鲁棒性。共同教学策略最近已经应用于无监督的人员重新识别[17],[18],物体检测[19]和其他视觉任务中。在这项工作中,我们将共同教学策略引入到WS-VAD中,通过这种方式,短期网络和长期网络可以相互学习。
C. Spatial-Temporal Contexts in WS-VAD
在VAD中,利用空间和时间上下文的信息对于算法的性能起着重要作用。许多WS-VAD方法通过预训练的时空特征提取器(如C3D [7]和I3D [8])来同时利用这两种信息。此外,一些方法还进一步捕捉了长程时间依赖关系,例如,Tian等人[10]使用了时间扩张卷积,Li等人[5]采用了基于transformer的多序列学习技术。此外,还探索了长程空间和时间依赖性的协同作用,例如,Purwanto等人[20]使用了自注意力和条件随机场,而Wu等人[9]提出了一个时空双分支网络架构。然而,所有以上的先前工作都没有同时考虑到精细的空间特征和长程时间依赖性。在本工作中,我们构建了两个基于管状体的时空变换网络,分别从短期和长期剪辑中进行学习,并采用了共同教学策略来增强两个网络。通过这种方式,我们可以捕捉到精细的特征以及空间和长程时间依赖性。
III. THE PROPOSED METHOD
图1呈现了所提出的方法的概述。在本节中,我们首先介绍基于transformer的短期或长期网络架构,然后介绍训练损失和协同教学策略。

图1. 所提出方法的概述。它采用协同教学策略交替训练短期网络和长期网络。每个网络以短期或长期剪辑作为输入。输入剪辑首先被分割成管状体(以4个管为例),并通过预训练的特征提取器进行令牌化。嵌入的令牌进一步输入到由多个transformer层和一个回归层组成的时空变换网络中,以预测异常得分。由一个网络预测的得分生成的伪标签用于监督另一个网络。
A. Transformer-based VAD Network
为了挖掘精细的特征并捕捉长程依赖关系,我们构建了基于管状体的时空Transformer作为我们的VAD网络架构。它首先嵌入管状体令牌,然后将这些令牌通过多个Transformer层和一个回归层,以预测所有输入剪辑的异常得分。
Tubelet Embedding.
Tubelet Embedding(管子嵌入)。让我们考虑一个尺寸为 F × H × W F\times H\times W F×H×W 的剪辑,其中 F F F 是连续帧的数量, H H H 和 W W W 分别是每帧的高度和宽度。我们将剪辑分割成非重叠的管子,如图 [ 1 ] \color{red}{[1]} [1]所示。每个管子是尺寸为 F × H t × W t F\times H_t\times W_t F×Ht×Wt 的,因此得到 N t = ⌊ H H t ⌋ ⋅ ⌊ W W t ⌋ N_t=\lfloor\frac H{H_t}\rfloor\cdot\lfloor\frac W{W_t}\rfloor Nt=⌊HtH⌋⋅⌊WtW⌋ 个管子。我们将每个管子输入到预先训练好的特征编码器(如C3D或I3D)中,以提取一个 d d d 维特征 f ∈ R d \mathbf{f}\in\mathbb{R}^d f∈Rd,该特征被视为后续Transformer层的一个标记。与先前的WS-VAD方法中使用的剪辑级标记不同[4],[5],[10],管子以更细粒度捕获空间上下文,有利于检测微妙的异常。同时,与最近视频transformers中将每个管子线性投影为 1D 标记的标记方式相比[21],由C3D或I3D提取的管子特征可以注入归纳偏差,有助于训练Transformer网络。
Transformer Architecture.
Transformer架构。我们基于Transformer的VAD网络接受
C
C
C个连续的视频片段作为输入。这些片段被上述提到的方法进行标记,以得到一个令牌序列。然后,一个维度为
z
c
l
s
∈
R
d
\mathbf{z}_{cls}\in\mathbb{R}^d
zcls∈Rd的特殊令牌被添加到序列的开头,形成Transformer的输入。换句话说,输入序列为:
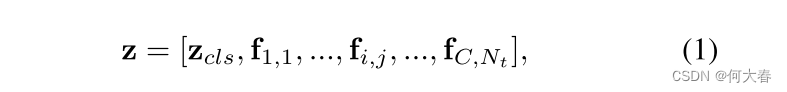
其中
f
i
,
j
\mathbf{f}_{i,j}
fi,j表示第i个片段中的第j个令牌。
输入序列通过由L个Transformer层和一个异常回归层组成的Transformer网络。每个Transformer层由多头自注意力(MSA)和前馈网络(FFN)模块组成,分别由缩放点积注意力和一个具有ReLU的2层MLP实现。第l层的计算如下:
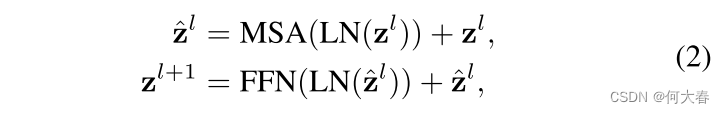
其中LN表示层归一化。最后,异常回归器由一个具有ReLU和Sigmoid激活函数的3层MLP实现,它接收最后一个Transformer层的输出
z
c
l
s
L
\mathbf{z}_{cls}^L
zclsL,用于预测所有剪辑的异常分数
s
∈
(
0
,
1
)
s\in(0,1)
s∈(0,1)。考虑到编码空间和时间位置信息是有益的,我们在MSA中的每个头部的自注意力计算中包含3D相对位置偏差,如[22]中所示。即,

其中,
Q
,
K
,
V
∈
R
C
⋅
N
t
×
d
\mathbf{Q},\mathbf{K},\mathbf{V}\in\mathbb{R}^{C\cdot N_t\times d}
Q,K,V∈RC⋅Nt×d 分别表示查询、键和值矩阵,
C
⋅
N
t
C\cdot N_t
C⋅Nt 是标记的数量,
B
∈
R
C
2
×
N
t
×
N
t
\mathbf{B}\in\mathbb{R}^{C^2\times N_t\times N_t}
B∈RC2×Nt×Nt 是用于位置编码的三维相对位置偏置。
B. Training Losses of the VAD Network
我们采用MIL(多实例学习)排名损失来训练VAD网络。此外,由于我们的工作采用了共同教学来训练两个VAD模型,其中一个产生伪标签以在下一轮训练中监督另一个,因此当伪标签可用时,我们还采用了交叉熵损失。MIL排名损失。 MIL排名损失在先前的方法中被广泛采用,将WSVAD(视频异常检测)制定为多实例学习问题。具体而言,它考虑了一个视频集合 V = { V i } i = 1 N \mathcal{V}=\{V_{i}\}_{i=1}^{N} V={Vi}i=1N,以及一个视频级别标签集 Y = { Y i ∈ { 0 , 1 } } i = 1 N \mathcal{Y}=\{Y_i\in\{0,1\}\}_{i=1}^N Y={Yi∈{0,1}}i=1N,指示视频是否异常( Y i = 1 Y_i=1 Yi=1)或正常( Y i = 0 Y_i=0 Yi=0)。每个视频 V i V_i Vi包含 N i N_i Ni个片段,每个片段有 F F F帧。基于MIL的表述将每个视频视为一个包(bag),将每个片段视为一个实例。因此,异常视频是一个正袋 B a = { c j a } j = 1 N i \mathcal{B}^a=\{c_j^a\}_{j=1}^{N_i} Ba={cja}j=1Ni,其中至少包含一个异常片段,而正常视频是一个负袋 B n = { c j n } j = 1 N i \mathcal{B}^n=\{c_j^n\}_{j=1}^{N_i} Bn={cjn}j=1Ni,其中没有异常实例。
在[4],[5]的基础上,我们采用连续采样策略和基于铰链的MIL排名损失来训练我们的VAD网络。从每个视频中均匀采样 K K K个子集的片段,每个子集包含 C C C个连续的片段,其中 C C C是输入到VAD网络中的片段数。对于每个子集 k k k,我们的网络预测一个异常分数 s k s_k sk。基于MIL的方法假设来自正袋的子集的最高异常分数高于来自负袋的最高异常分数,即 max 1 ≤ k ≤ K s k a > max 1 ≤ k ≤ K s k n \begin{aligned}\max_{\begin{array}{c}1\le k\le K\\\end{array}}s_k^a&>\max_{\begin{array}{c}1\le k\le K\\\end{array}}s_k^n\\\end{aligned} 1≤k≤Kmaxska>1≤k≤Kmaxskn。然后,给定一个正袋和一个负袋,我们使用稀疏正则化来定义损失函数,如下所示:

其中 ( ⋅ ) + (\cdot)_+ (⋅)+表示 m a x ( 0 , ⋅ ) max(0,\cdot) max(0,⋅)。第一项是为了保持正负子集之间的间隔 τ \tau τ,第二项是为了规范化只有少数子集包含异常。 α \alpha α是一个用于平衡两项的超参数。
Cross Entropy Loss.当剪辑级别的伪标签可用时(生成伪标签的方式将在图III-C中介绍),我们将WS-VAD视为监督学习问题,并采用常用的交叉熵损失进行学习。给定剪辑
c
i
c_i
ci的预测异常分数
s
i
s_i
si及其伪标签
y
~
i
\tilde{y}_i
y~i,损失定义如下:
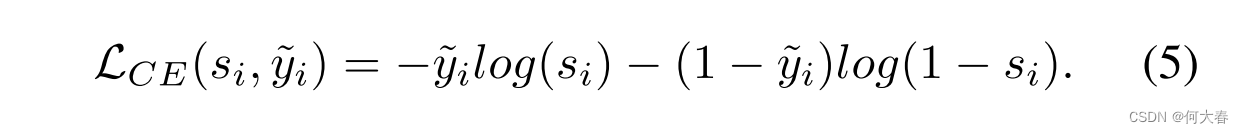
C. Long-Short Temporal Co-teaching
为了处理异常事件持续时间的差异,我们构建了一个短期网络(STN)和一个长期网络(LTN)进行学习。前者将一系列短剪辑作为输入,而后者则输入一个长剪辑序列。这两个网络通过协同教学策略进行交替训练。在第一轮中,由于没有剪辑级别的伪标签可用,STN模型最初使用MIL损失
L
M
I
L
\mathcal{L}_{MIL}
LMIL进行训练。随后,一旦一个网络训练完成,我们根据其预测的异常分数生成伪标签,方法如下:

其中,
μ
\mu
μ是一个阈值,
Y
i
Y_i
Yi表示剪辑
i
i
i的视频级别标签。然后,另一个网络采用伪标签进行监督,并使用以下损失进行训练:

其中β是用于平衡两个损失的超参数。
D. Inference
在测试过程中,我们只需选择在训练集上表现更好的模型作为推理的最终模型。
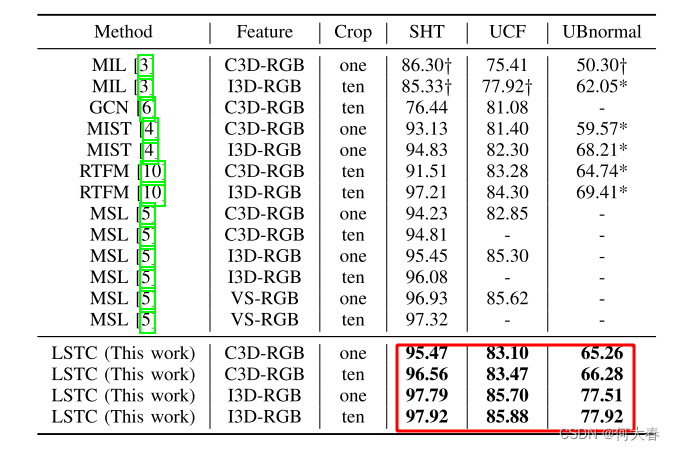
IV. EXPERIMENTS
V. CONCLUSION
在这项工作中,我们提出了一种长短时序共教(LSTC)方法来解决WS-VAD问题。它构建了两个基于管状体的时空Transformer网络,分别从短期和长期视频片段中学习。这两个模型通过共教策略交替训练和迭代。受益于基于管状体的Transformer架构和长短时序协同策略,所提出的方法能够更好地处理细微异常和持续时间变化的异常。实验证明,我们的方法表现优于最先进的方法。
阅读总结
个人感觉没啥太大的亮点,就两个不同的输入长度融合,加上对单个网络的输入还做了一个输入视频的切分。粒度相对来说高一点。















 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









