







MULTI-SCALE CONTINUITY-AWARE REFINEMENT NETWORK FOR WEAKLY SUPERVISED VIDEO ANOMALY DETECTION 论文阅读
文章信息:

发表于:ICME 2022
原文链接:https://ieeexplore.ieee.org/document/9860012
ABSTRACT
在许多先前的工作中,弱监督视频异常检测被制定为多实例学习(MIL)问题,这将视频表示为多个实例的集合。然而,大多数基于MIL的框架仅关注于从给定的实例中识别异常事件,而不考虑事件的连续性。由于异常事件在真实世界的视频中往往更具连续性,因此本文提出了一种多尺度连续性感知精化网络(MCR)。它利用多尺度连续性的特性,通过引入实例的差异化上下文信息来精化异常分数。同时,设计了多尺度注意力来产生视频级别的权重,以选择适当的尺度并融合不同尺度上的所有分数。MCR的实验结果显示,在两个公共数据集上取得了显著的改进,特别是在ShanghaiTech数据集上获得了94.92%的帧级AUC。
1. INTRODUCTION
由于监控领域的广泛应用,视频异常检测一直是计算机视觉中一个潜在的研究方向。视频异常检测的目标是识别异常事件发生的时间窗口。然而,与图像分类任务不同,获取视频中大规模的帧级注释可能更加困难和昂贵。由于大多数监控视频都是正常的,一些先前的工作将异常检测视为无监督学习任务。它们通过专门使用正常视频训练单类分类器来解决问题。无监督方法旨在在训练阶段学习正常事件的一般模式,并在测试阶段将那些未见过的模式识别为异常。然而,在这种范式下,覆盖训练集中的所有正常事件是不现实的,而那些从未出现在训练集中的正常事件可能会在这种情况下产生误报。
因此,一些研究人员采用了二分类范式,将视频异常检测视为一个弱监督问题。在训练阶段,具有正常或异常视频级标签注释的样本被输入到网络中。Sultani等人将弱监督视频异常检测(WS-VAD)构建为一个多实例学习(MIL)任务。每个视频被视为一个袋子(异常:正例,正常:负例),并被划分为固定数量的段作为实例。他们使用多层感知器(MLP)为实例生成异常分数,并提出了一个排名损失函数,以扩大正负袋子中两个最高得分实例之间的距离。在他们的工作发表后,许多基于MIL框架的VS-VAD方法,如[1][7][8][9],主要是基于MIL框架。
Zhang等人[7]进一步引入了内部袋间分数差规则;AR-Net[8]在MIL学习框架下取得了更好的性能,因为他们的工作引入了一种k-max选择方法,取代了以前工作[6][7]中的最大选择。此外,他们引入了动态MIL损失(如图1中的LDMIL),以最大化类间距离。为了加强视频的时间特征的表示,在RTFM[1]中,提出了MTN来捕获实例之间的时间维度上的局部依赖性和全局依赖性。
然而,大多数现有方法并没有充分利用视频异常的一个重要先验知识,即在视频中异常事件往往持续一段时间。尽管实例代表视频中连续帧的一段剪辑,但通常它并不是异常事件的最小时间单位,如图2所示。直观地说,引入多个相邻实例的时间连续性有助于识别异常。但这也带来了另一个挑战,即在视频长度变化的同时确定异常事件的适当持续时间是困难的。
为了解决上述问题,本文提出了一种多尺度连续性感知细化网络(MCR),以强化WS-VAD任务对异常连续性的关注。在我们的工作中,应用了一个名为多尺度连续性模块的新模块,用于提取不同时间尺度下实例的连续性,如图1所示。此外,为了更好地整合不同尺度的信息,设计了一个多尺度注意力模块。在这个模块中,生成了特定的权重因子,用于对复杂视频场景进行加权和选择合适的时间尺度。

图1. 与传统方法相比的不同异常分数处理过程。彩色圆圈中的数字代表片段的异常分数。
2. METHODOLOGY
给定一个视频训练集,其中包含视频标记样本
V
=
{
(
v
i
,
y
i
)
}
i
=
1
N
V=\{(v_i,y_i)\}_{i=1}^N
V={(vi,yi)}i=1N,其中
N
N
N是训练阶段视频的数量,
y
i
∈
{
0
,
1
}
y_i\in\{0,1\}
yi∈{0,1}表示视频级别的标签注释,指示
v
i
v_i
vi是正常视频(
y
i
=
0
y_i=0
yi=0)。单个视频
v
i
v_i
vi会被划分为
k
i
k_i
ki个片段。为了实现区分正常片段和异常片段的目标,需要计算片段的异常得分向量,可以表示为:

其中,
S
i
S_{i}
Si是
v
i
v_{i}
vi的异常得分向量,
s
i
,
j
s_{i,j}
si,j是
S
i
S_{i}
Si中第
j
j
j个片段的异常得分。
我们工作的总体框架如图3所示。我们提出了一个新的多尺度连续性模块,用于生成窗口得分,其中包含不同尺度实例连续信息,同时另一个多尺度注意力模块用于选择适当的尺度进行异常得分评估。

2.1. Conventional procedures
传统WS-VAD的关键组件包括特征提取器和异常分数生成器,如图3左侧所示。特征提取器的输入剪辑通常由16个连续帧组成,而在WS-VAD中,经常使用在Kinetics[11]上预训练的Inflated 3D(I3D)[11]。时空特征
F
F
F 可以表示为:

其中,
f
i
,
j
f_{i,j}
fi,j是
v
i
v_i
vi中第
j
j
j个剪辑的时空特征,
F
i
∈
R
k
i
×
D
F_i \in \mathbb{R}^{k_i \times D}
Fi∈Rki×D,其中
D
D
D是特征的维度。
特征集
F
i
F_i
Fi然后被送入一个全连接(FC)层,以获取用于异常分数生成的增强表示
F
^
i
\hat{F}_i
F^i。值得注意的是,该层的输出维度与输入维度
D
D
D相同。在FC层之后采用ReLU作为激活函数,以避免过拟合,我们在训练阶段还采用了Dropout。然后
F
^
i
\hat{F}_i
F^i可以被视为:

其中,
D
(
⋅
)
\mathcal{D}(\cdot)
D(⋅)表示Dropout,
W
1
W_{1}
W1和
b
1
b_{1}
b1是FC层的参数。
然后,
F
^
i
\hat{F}_{i}
F^i被送入一个回归层生成基本异常分数
S
˙
i
\dot{S}_{i}
S˙i,如下所示:
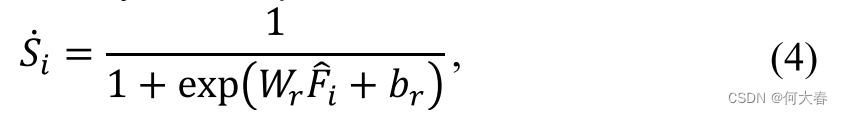
其中,
W
r
W_r
Wr和
b
r
b_r
br是回归层的参数。
2.2. Multi-scale Continuity-aware Refinement Network
基本异常得分 S ˙ i \dot{S}_i S˙i 在先前的工作中直接用于定位异常片段。然而,由于该得分是单独生成的,没有考虑其对应实例的上下文,因此缺乏视频的连续性信息。由于连续性是异常事件的最重要特征之一,所提出的MCR网络旨在通过引入实例的时间连续性来优化基本异常得分 S ˙ i \dot{S}_i S˙i。因此,利用多尺度连续性模块来提取各种时间尺度上的异常连续性。此外,多尺度注意力被应用于更好地整合不同尺度的信息,以增强所提出的MCR网络的稳健性。
2.2.1. Multi-scale Continuity
为了根据基本异常得分
S
˙
i
\dot{S}_i
S˙i 引入异常事件的时间连续性,采用了移动平均方法在不同尺度上生成窗口得分向量。如图3所示,池化运算符用于对第j个片段执行多尺度移动平均运算,以获得新的平滑得分
s
~
i
,
j
(
w
)
\tilde{s}_{i,j}^{(w)}
s~i,j(w)。
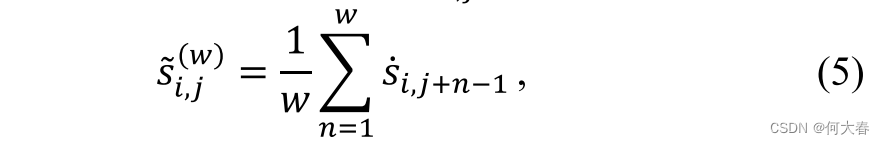
其中,w 是移动平均的窗口大小。与 RTFM [1] 相比,移动平均可以捕获实例的局部依赖关系,而不引入任何额外的模型参数。
值得注意的是,每个视频中的剪辑数量 k i k_i ki 不一致。此外,不同类型的异常事件持续时间也差异很大。因此,显然固定的时间尺度不合适。在提出的 MCR 网络中,使用不同的窗口大小生成一组候选分数向量,而在下一节将选择最合适的分数。具有 N N N 种不同尺度的平滑分数集合 ( w 1 , . . . , w n , . . . , w N ) (w_1,...,w_n,...,w_N) (w1,...,wn,...,wN) 被定义为 S ~ i = { s ~ i , j ( w 1 ) , . . . , s ~ i , j ( w n ) , . . . , s ~ i , j ( w N ) } \tilde{S}_i=\left\{\tilde{s}_{i,j}^{(w_1)},...,\tilde{s}_{i,j}^{(w_n)},...,\tilde{s}_{i,j}^{(w_N)}\right\} S~i={s~i,j(w1),...,s~i,j(wn),...,s~i,j(wN)}。
2.2.2. Multi-scale Attention
为了从候选分数集合 S ~ i \tilde{S}_i S~i 中选择合适的尺度,引入了类似注意力的模块,根据每个视频的增强特征 F ^ i \hat{F}_i F^i 对不同尺度赋予适当的权重。
由于每个视频的片段数 k i k_i ki 不同,因此采用自适应挤压步骤来合并连续片段的特征,如图3所示。在此之后,特征 F ^ i ∈ R k i × D \hat{F}_i\in\mathbb{R}^{k_i\times D} F^i∈Rki×D 可以转换为 F ~ i ∈ R K × D \tilde{F}_i\in\mathbb{R}^{K\times D} F~i∈RK×D,其中 K K K 是一个超参数,我们的实验中设置为32。另一个全连接层接受 F ~ i \tilde{F}_i F~i 作为输入,随后是一个 SoftMax 层作为激活函数。通过这个过程,可以获得每个尺度的视频级权重因子,这表示对应平滑分数 s ~ i , j ( w n ) \tilde{s}_{i,j}^{(w_n)} s~i,j(wn) 的重要性。然后,这个权重因子向量 P i P_i Pi 可以形式化如下:

其中 p i ∈ [ 0 , 1 ] , W 2 ∈ R D × N , b 2 ∈ R 1 × N , N p_i\in[0,1],\quad W_2\in\mathbb{R}^{D\times N},\quad b_2\in\mathbb{R}^{1\times N},\quad N pi∈[0,1],W2∈RD×N,b2∈R1×N,N 表示权重因子的数量,与尺度的数量相同。在我们的实验中,它被设置为3。通过将平滑的多尺度异常分数 S ~ i \tilde{S}_i S~i 与权重 P i P_i Pi 相乘,可以表示第 i i i 个视频中第 j j j 个片段的最终异常分数 s i , j s_{i,j} si,j 如下:
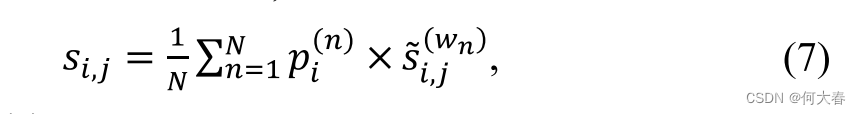
其中,
p
i
(
n
)
p_i^{(n)}
pi(n) 是权重因子
P
i
P_i
Pi 中的第
n
n
n 个常数,
s
~
i
,
j
(
w
n
)
\tilde{s}_{i,j}^{(w_n)}
s~i,j(wn) 是得分列表
S
~
i
\tilde{S}_i
S~i 中第
n
n
n 个尺度的分数向量。为了简单起见,
S
i
=
{
s
i
,
j
}
j
=
1
k
i
S_i=\{s_{i,j}\}_{j=1}^{k_i}
Si={si,j}j=1ki 是第
i
i
i 个视频的得分向量。
2.3. Optimization
在提出的 MCR 网络中,采用了动态多实例学习(DMIL)损失和中心损失,这在先前的工作中表现良好。通过提出的多尺度连续性感知异常得分
s
i
,
j
s_{i,j}
si,j,DMIL 损失能够增大异常和正常实例之间的类间距离,表示如下:

其中,
y
i
y_i
yi 是
v
i
v_i
vi 的视频级标签。
相应地,这里应用的中心损失可以有效地减少类内距离,其表达式为:
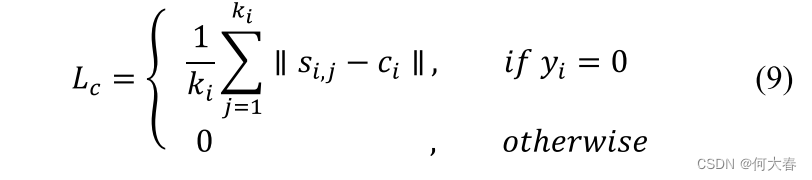

其中
c
i
c_i
ci是第
j
j
j个异常分数向量
s
i
s_i
si的中心。然后,总损失函数可以表示如下:

根据先前的WS-VAD框架,例如AR-Net[8],在随后的实验中,
λ
\lambda
λ被设定为20,以保持两个损失之间的平衡。
3. EXPERIMENTS
3.1. Datasets and metrics
UCF-Crime [6] 是一个大规模的监控视频数据集。它包含了13种异常行为,共有1900个长时间未修剪的视频。在训练阶段提供了1610个带有视频级别注释的视频,而其他290个带有帧级别注释的视频则用作测试视频。
ShanghaiTech [2] 是一个来自校园视频监控的中等规模数据集。我们遵循了钟等人的步骤,训练集包括了175个正常视频和63个异常视频,而测试集分别包括了155个正常视频和44个异常视频。
按照先前工作的协议,帧级接收者操作特征(ROC)下面积(AUC)被用作两个数据集的评估指标。更高的AUC表示更好的性能。为了评估我们提出的网络的鲁棒性,普通视频上的虚警率(FAR)被视为另一个重要的指标。较低的普通视频虚警率表示异常检测方法的鲁棒性更强。
3.2. Implementation details
我们提出的MCR网络采用端到端的范式进行训练,使用Adam优化器[13],权重衰减率为0.0005,批量大小为60,包括30个正常视频和30个异常视频。学习率设置为0.0001,分别用于ShanghaiTech [2]和UCF-Crime [6]。与AR-Net [8]一样,我们使用I3DConv作为特征表示,结合了RGB帧和基于TV-L1算法[14]生成的光流帧。我们在第一个FC层后采用了Dropout [15],丢失率为0.7。通过自适应池化将视频的不同片段长度固定为32。在我们的实验中,权重因子𝛼的数量设置为3,这意味着我们还应用了三个不同的核大小来汇总基本的异常分数。我们使用1D平均池化运算符实现移动平均,池化的核大小分别为3、5、7,填充分别为1、2、3。
3.3. Comparisons with other methods
我们提出的方法在ShanghaiTech [2]上的表现记录在表1中。在这些框架中采用了不同的特征提取器[11][19][20]。特别是,通过采用与ARNet [8]相同的优化策略,我们的方法在AUC指标上实现了显著的改善。提出的MCR在AUC上超越了AR-Net,从92.60%提高到94.92%,相对增益为2.32%。
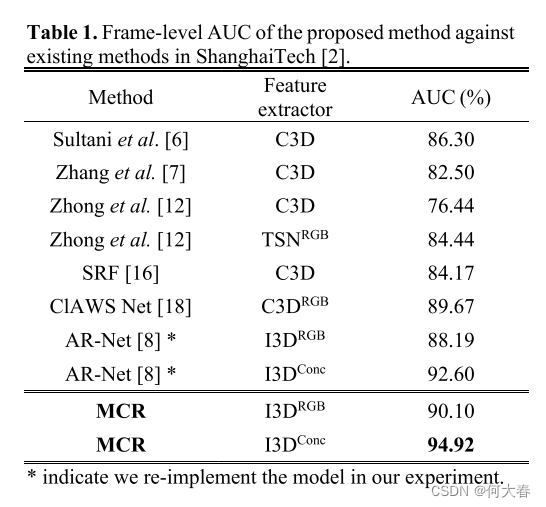
我们的模型还在UCF-Crime [6]上进行了评估,如表2所示。我们使用了I3DRGB作为特征,并采用了与AR-Net [8]相同的十次裁剪增强策略。值得注意的是,我们的MCR网络在帧级AUC上仍然比AR-Net [8]高出1%,与其他最先进的方法相比也具有竞争力。

3.4. Qualitative results and analysis
我们的模型还在UCF-Crime [6]上进行了评估,如表2所示。我们使用了I3DRGB作为特征,并采用了与AR-Net [8]相同的十次裁剪增强策略。值得注意的是,我们的MCR网络在帧级AUC上仍然比AR-Net [8]高出1%,与其他最先进的方法相比也具有竞争力。
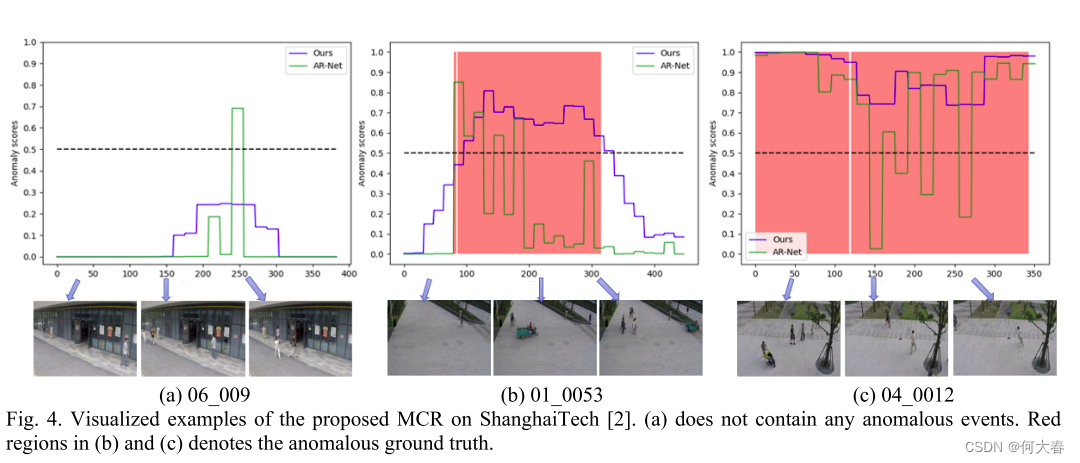
我们将我们的方法和AR-Net [8]生成的正常和异常得分图进行了比较,如图4所示。可以看出,我们的MCR生成的结果更趋向于连续,这与异常事件的特征相符合。在正常视频(图4(a))中,AR-Net [8]在第250帧左右的错误高异常得分可以被我们模型中相邻帧有效地拉低。相应地,MCR给出的异常事件的得分图(b)和(c)更接近于真实情况。
3.5. Ablation study
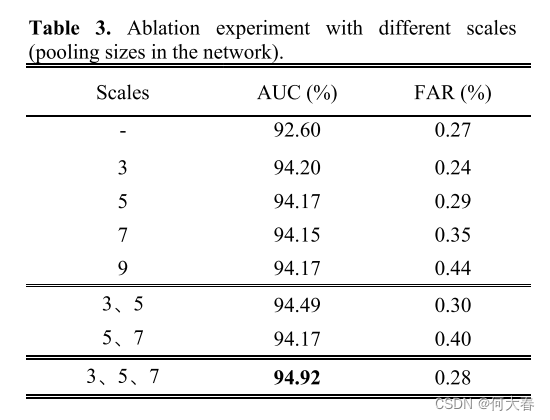
为验证多尺度策略的有效性,我们使用AR-Net [8]生成基本的异常得分作为基线,然后进行一系列实验,使用不同的窗口大小。
如表4所示,随着池化大小的增加,帧级AUC略有变化,但假阳性率始终增加。考虑到我们提出的网络的稳健性,我们更倾向于较小的三个尺寸(大小为3、5、7)。
实验结果表明,所提出的多尺度方案有效地将帧级AUC提升到了94.12%。此外,通过加权因子融合多尺度连续信息,我们将性能提升到了帧级AUC 94.92%,相对于基线改进了约2.32%。
4. CONCLUSION
在本文中,我们提出了一种用于视频异常检测的多尺度连续性感知精化网络(MCR)。我们的网络遵循弱监督视频异常检测范式,在训练阶段仅具备视频级别标签。与基于MIL学习的先前工作不同,我们充分利用了异常事件的时间连续性特征。我们提取相邻片段的多尺度连续性信息,并通过多尺度注意力模块进行加权。对具有挑战性的数据集的实验证明了我们方法的有效性。
阅读总结
有一个疑问,这个窗口分数,三个尺度都不一样,那得到的窗口分数向量的长度也是不一样的吧,看图2和论文的意思是一样的,但是论文好像并没有说是怎么对齐他们的长度的。
















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









