









 本文分享了一款使用Python的requests和bs4库编写的爬虫程序,该程序能从知乎高赞回答中抓取表情包。通过解析HTML和使用正则表达式,程序成功抓取了数百张表情包,并提供了完整代码和表情包下载方式。
本文分享了一款使用Python的requests和bs4库编写的爬虫程序,该程序能从知乎高赞回答中抓取表情包。通过解析HTML和使用正则表达式,程序成功抓取了数百张表情包,并提供了完整代码和表情包下载方式。
干货分享

引言
今天研究了会requests库。发现和urllib库功能类似,很好上手,因此写了个Demo爬了爬表情包。我选取了几个知乎里关于表情包问题的高赞回答,一共爬取了三个回答共六百多个表情包。
相关文件
相关程序获取:公众号 拇指笔记 后台回复“表情包”获取。
在安装好相关库后,只需要更改url,就可以实现爬取其他网页中的表情包。
表情包获取:公众号 拇指笔记 后台回复“表情包”获取。
爬取到的表情包我也一并上传到了公众号,回复即可获得全部表情包。
第三方库
re:正则匹配,用来提取图片信息
bs4:解析HTML文件
urllib :根据提取到的连接下载图片
requests:发送http请求
实现效果
爬到的表情包如下:
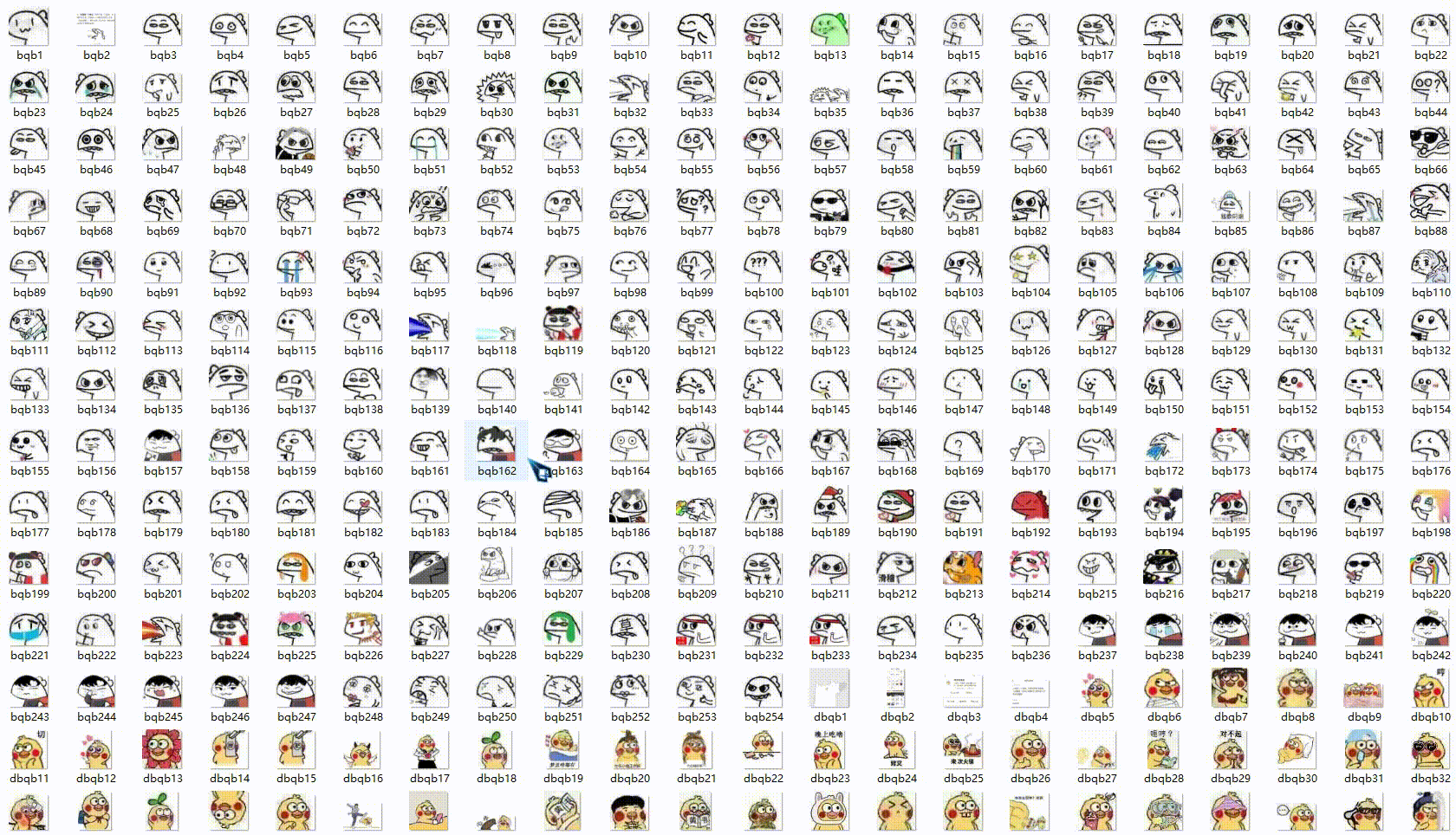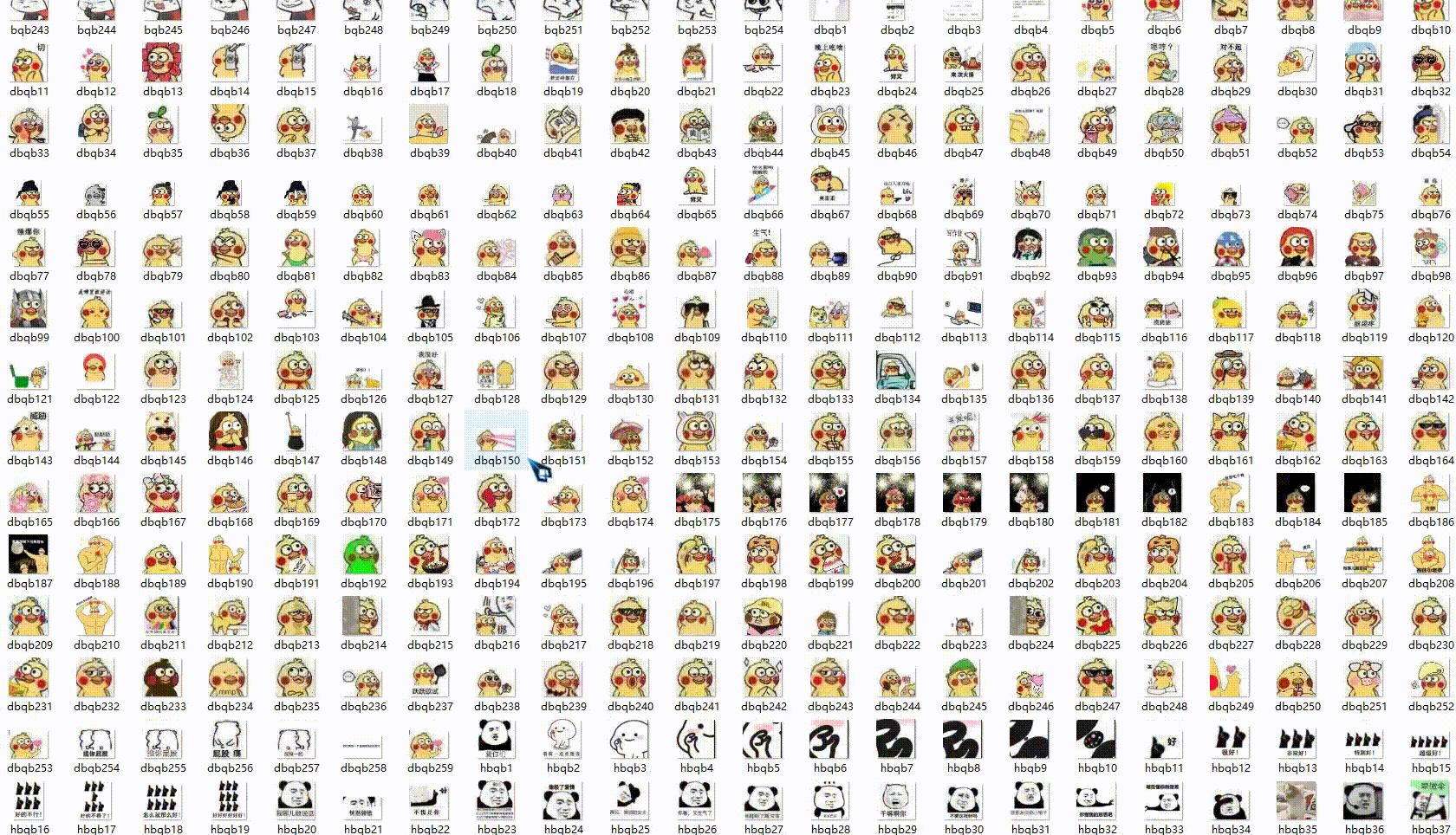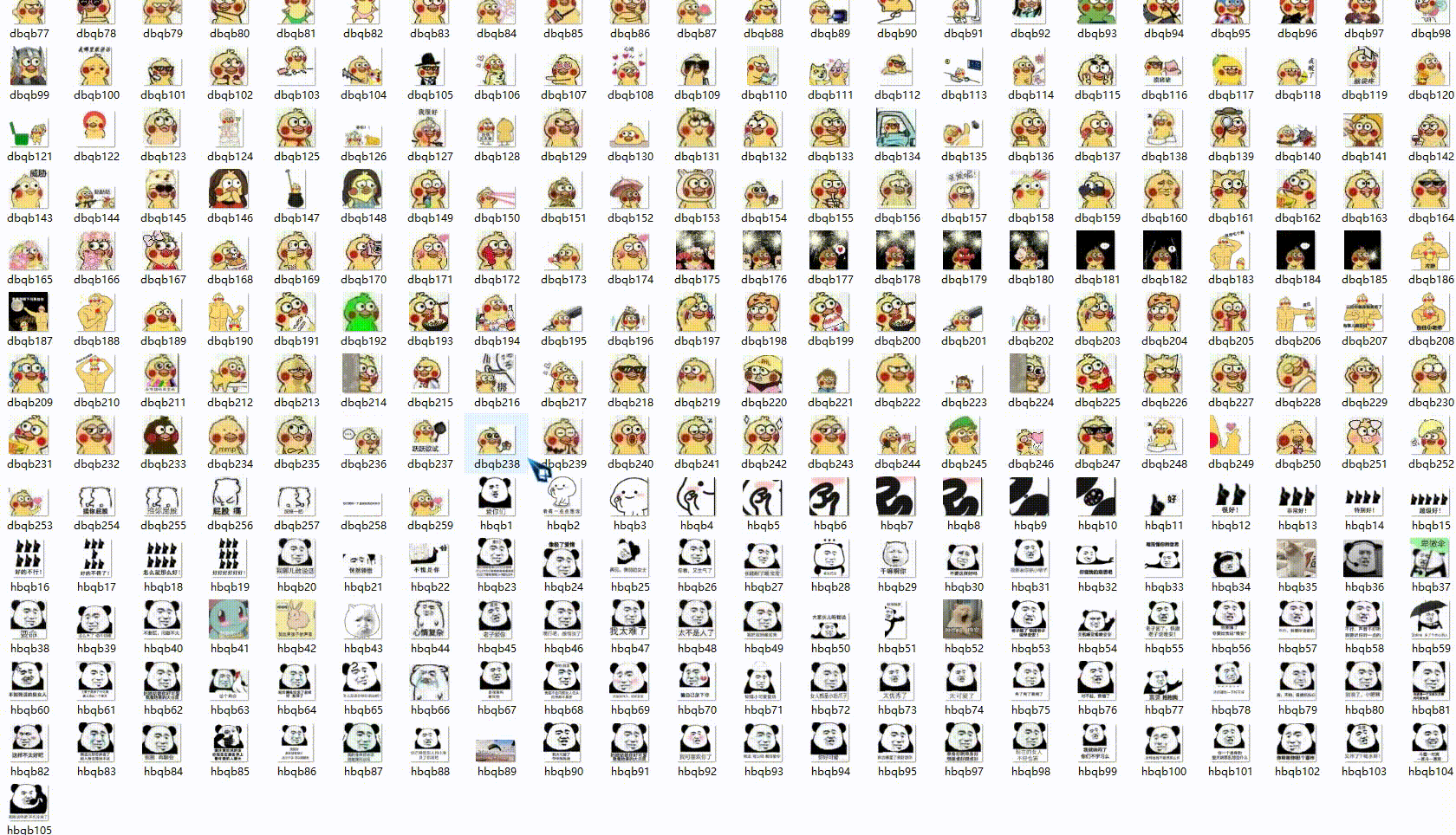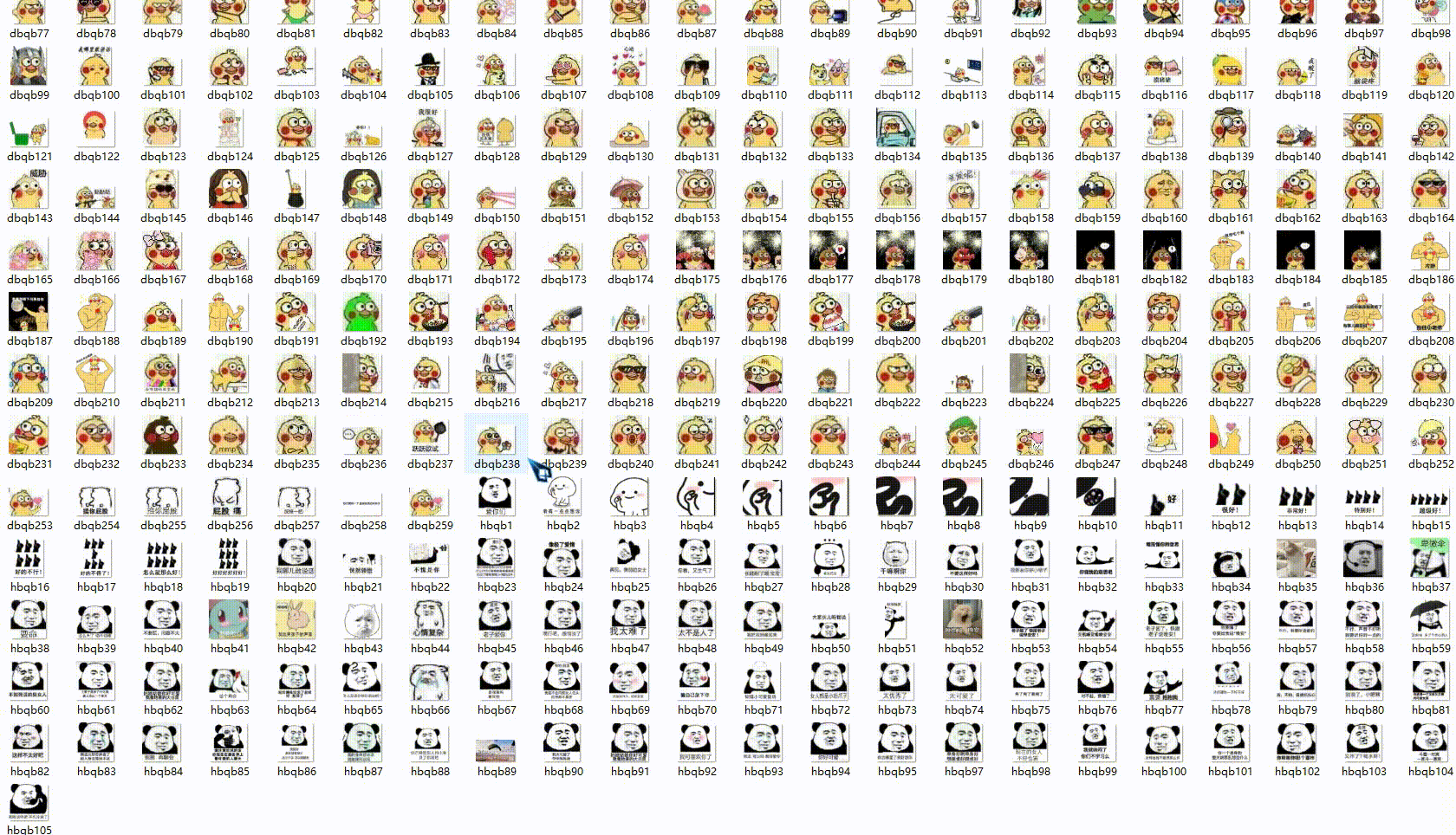
爬取表情包
整个程序实现还是很简单的,就是标准的爬取静态网页的过程。首先是确定需要爬取的信息位置,F12打开看一下,很快确定了图片的所在位置。
<img src="https://pic1.zhimg.com/80/v2-bffbbe33c937ceb498d0882bf21a651c_720w.jpg">
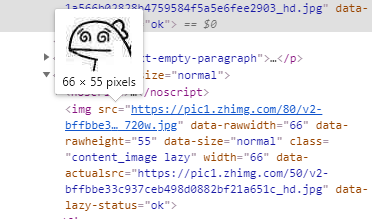
接下来就是使用bs4库解析一下get到的页面信息。四行代码就可以实现这一功能。

最后使用urllib库的urlretrieve方法下载图片即可,同时需要记着为每下载一张图片改一次名。
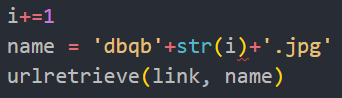
最后
如果觉得本文还可以,还请各位点个在看。


















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









