







多线程理论基础(三)
目录
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cOKdF3RB-1612775152125)(/Users/gaoxu/Library/Application Support/typora-user-images/image-20210208170515921.png)]
一.前言
前面对于多线程理论进行了分析,主要是针对多线程并发问题的根源,以及如何从方法论上解决多线程的并发问题,针对多线程的主要问题互斥和协同,对于synchronized最基本的管程模型,进行分析,了解管程的重要性.本章节从多线程生命周期.线程状态变更,线程创建等角度分析;
- 线程生命周期
- 线程状态转换
- 常用方法
二.线程生命周期
线程生命周期:
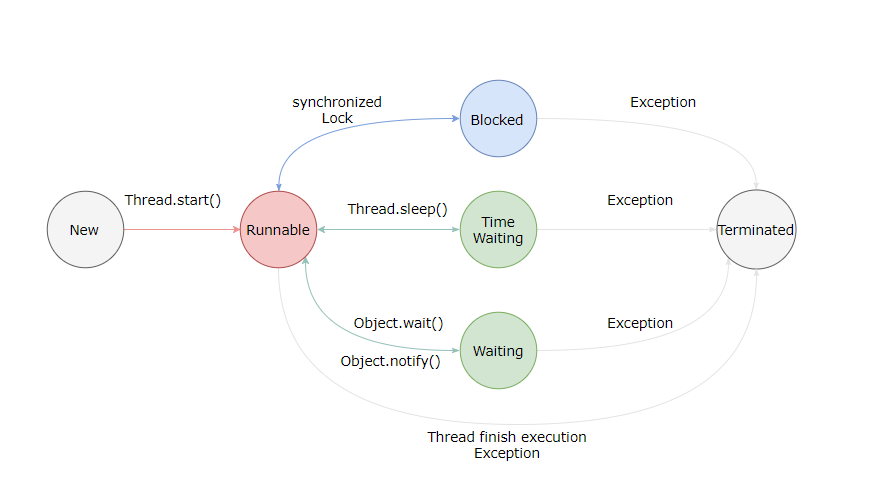
1.NEW (初始化状态)
2.RUNABLE(可运行/运行状态)
3.WAITING(无限时等待)
4.TIMED_WAITING(有时限等待)
5.BLOCKED(阻塞)
6.TERMINATED(终止状态)
其中,从操作系统层面,BLOCKED,WAITING,TIMED_WAITING都是属于休眠状态.并没有CPU的使用权.
三.线程状态转换
3.1.RUNABLE 和BLOCKED状态转换
只有一种场景会触发这种转换,就是线程等待 synchronized 的隐式锁。
synchronized 修饰的方法、代码块同一时刻只允许一个线程执行,其他线程只能等待,这种情况下,等待的线程就会从 RUNNABLE 转换到 BLOCKED 状态。而当等待的线程获得 synchronized 隐式锁时,就又会从 BLOCKED 转换到 RUNNABLE 状态。
小贴士:
线程调用阻塞式API时,是否会转换到BLOCKED状态呢?
JVM层面,Java线程的状态不会发生变化,也就是说 Java 线程的状态会依然保持RUNNABLE状态.JVM层面并不关心操作系统调度相关的状态,因为在JVM看来,等待 CPU 使用权(操作系统层面此时处于可执行状态)与等待 I/O(操作系统层面此时处于休眠状态)没有区别,都是在等待某个资源,所以都归入了RUNNABLE状态。
3.2.RUNABLE 和WAITING状态转换
第一种场景,获得 synchronized 隐式锁的线程,调用无参数的 Object.wait() 方法。
第二种场景,调用无参数的 Thread.join() 方法。其中的 join() 是一种线程同步方法,例如有一个线程对象 thread A,当调用 A.join() 的时候,执行这条语句的线程会等待 thread A 执行完,而等待中的这个线程,其状态会从 RUNNABLE 转换到 WAITING。当线程 thread A 执行完,原来等待它的线程又会从 WAITING 状态转换到 RUNNABLE。
第三种场景,调用 LockSupport.park() 方法。其中的 LockSupport 对象,也许你有点陌生,其实 Java 并发包中的锁,都是基于它实现的。调用 LockSupport.park() 方法,当前线程会阻塞,线程的状态会从 RUNNABLE 转换到 WAITING。调用 LockSupport.unpark(Thread thread) 可唤醒目标线程,目标线程的状态又会从 WAITING 状态转换到 RUNNABLE。
具体方法:
| 方法名称 | 方法退出 |
|---|---|
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
| LockSupport.park() 方法 | - |
3.3 RUNABLE 和 TIMED_WAITING状态转换
这两种状态的转换可以跟上面的那个做一下类比:
- 调用带超时参数的 Thread.sleep(long millis) 方法;
- 获得 synchronized 隐式锁的线程,调用带超时参数的 Object.wait(long timeout) 方法;
- 调用带超时参数的 Thread.join(long millis) 方法;
- 调用带超时参数的 LockSupport.parkNanos(Object blocker, long deadline) 方法;
- 调用带超时参数的 LockSupport.parkUntil(long deadline) 方法。
| 方法名称 | 方法退出 |
|---|---|
| Thread.sleep(long millis) 方法 | 休眠时间结束 |
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
| LockSupport.parkNanos() 方法 | - |
| LockSupport.parkUntil() 方法 | - |
3.3 NEW和RUNNABLE状态
JAVA刚创建出来的Thread对象就是NEW的状态,创建Thread对象的的方式有三种:
- 继承Thread类,重写run方法
- 实现Runnable接口,重写run方法
- 实现接口Callable接口,实现call方法.线程有返回值;
方式1:
// 自定义线程对象
class MyThread extends Thread {
public void run() {
// 线程需要执行的代码
......
}
}
// 创建线程对象
MyThread myThread = new MyThread();
方式2:
// 实现 Runnable 接口
class Runner implements Runnable {
@Override
public void run() {
// 线程需要执行的代码
......
}
}
// 创建线程对象
Thread thread = new Thread(new Runner());
方式3:
public class ThreadC implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(500);
System.out.println("这是线程C");
return "线程C";
}
}
方式3有些特殊,Thread类没有提供直接的构造方式.将Callable对象注入,或者属性注入的方式;

从Callable接口的角度分析使用方式:
public class FutureTask<V> implements RunnableFuture<V> {
/*
* Revision notes: This differs from previous versions of this
* class that relied on AbstractQueuedSynchronizer, mainly to
* avoid surprising users about retaining interrupt status during
* cancellation races. Sync control in the current design relies
* on a "state" field updated via CAS to track completion, along
* with a simple Treiber stack to hold waiting threads.
*
* Style note: As usual, we bypass overhead of using
* AtomicXFieldUpdaters and instead directly use Unsafe intrinsics.
*/
/**
* The run state of this task, initially NEW. The run state
* transitions to a terminal state only in methods set,
* setException, and cancel. During completion, state may take on
* transient values of COMPLETING (while outcome is being set) or
* INTERRUPTING (only while interrupting the runner to satisfy a
* cancel(true)). Transitions from these intermediate to final
* states use cheaper ordered/lazy writes because values are unique
* and cannot be further modified.
*
* Possible state transitions:
* NEW -> COMPLETING -> NORMAL
* NEW -> COMPLETING -> EXCEPTIONAL
* NEW -> CANCELLED
* NEW -> INTERRUPTING -> INTERRUPTED
*/
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
/** The underlying callable; nulled out after running */
private Callable<V> callable;
/** The result to return or exception to throw from get() */
private Object outcome; // non-volatile, protected by state reads/writes
/** The thread running the callable; CASed during run() */
private volatile Thread runner;
/** Treiber stack of waiting threads */
private volatile WaitNode waiters;
FutureTask 类中包含成员变量Callable对象.并且提供了构造方法:
/**
* Creates a {@code FutureTask} that will, upon running, execute the
* given {@code Callable}.
*
* @param callable the callable task
* @throws NullPointerException if the callable is null
*/
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
FutureTask对象实现了接口RunnableFuture接口,可以看一下其定义:
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
具体怎么在类FutureTask类中,实现run方法,感兴趣可以去看一下源码.
分析一下:

3.4 RUNNABLE 和 TERMINATED状态
线程执行完 run() 方法后,会自动转换到 TERMINATED 状态,当然如果执行 run() 方法的时候异常抛出,也会导致线程终止。有时候我们需要强制中断 run() 方法的执行,例如 run() 方法访问一个很慢的网络,我们等不下去了,想终止怎么办呢?Java 的 Thread 类里面倒是有个 stop() 方法,不过已经标记为 @Deprecated,所以不建议使用了。正确的姿势其实是调用 interrupt() 方法。
stop()和interrupt()方法的区别:
stop() 方法会真的杀死线程,不给线程喘息的机会,如果线程持有 ReentrantLock 锁,被 stop() 的线程并不会自动调用 ReentrantLock 的 unlock() 去释放锁,那其他线程就再也没机会获得 ReentrantLock 锁,这实在是太危险了。
当线程 A 处于 WAITING、TIMED_WAITING 状态时,如果其他线程调用线程 A 的 interrupt() 方法,会使线程 A 返回到 RUNNABLE 状态,同时线程 A 的代码会触发 InterruptedException 异常。上面我们提到转换到 WAITING、TIMED_WAITING 状态的触发条件,都是调用了类似 wait()、join()、sleep() 这样的方法,我们看这些方法的签名,发现都会 throws InterruptedException 这个异常。这个异常的触发条件就是:其他线程调用了该线程的 interrupt() 方法。
当线程 A 处于 RUNNABLE 状态时,并且阻塞在 java.nio.channels.InterruptibleChannel 上时,如果其他线程调用线程 A 的 interrupt() 方法,线程 A 会触发 java.nio.channels.ClosedByInterruptException 这个异常;而阻塞在 java.nio.channels.Selector 上时,如果其他线程调用线程 A 的 interrupt() 方法,线程 A 的 java.nio.channels.Selector 会立即返回。
四.如何量化线程
使用线程主要的目的在于提升系统性能,性能在量化的指标上有先考虑两个指标:
- 延迟性:指的是发出请求到收到响应这个过程的时间,字面理解时间越短越好;
- 吞吐量:指的是在单位时间内能处理请求的数量;吞吐量越大,意味着程序能处理的请求越多,性能也就越好;
一般说你要提高你程序的性能,自然而然就是提高系统的吞吐量,降低延迟;
多线程在使用的过程中需要判定使用场景,是针对I/O密集型还是CPU密集型应用;
小贴士:
具体可以参考美团的一篇文章:https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html
具体创建多少线程合适,要看多线程具体的应用场景。我们的程序一般都是 CPU 计算和 I/O 操作交叉执行的,由于 I/O 设备的速度相对于 CPU 来说都很慢,所以大部分情况下,I/O 操作执行的时间相对于 CPU 计算来说都非常长,这种场景我们一般都称为 I/O 密集型计算;和 I/O 密集型计算相对的就是 CPU 密集型计算了,CPU 密集型计算大部分场景下都是纯 CPU 计算。I/O 密集型程序和 CPU 密集型程序,计算最佳线程数的方法是不同的。
对于 CPU 密集型计算,多线程本质上是提升多核 CPU 的利用率,所以对于一个 4 核的 CPU,每个核一个线程,理论上创建 4 个线程就可以了,再多创建线程也只是增加线程切换的成本。所以,对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
对于 I/O 密集型的计算场景,比如前面我们的例子中,如果 CPU 计算和 I/O 操作的耗时是 1:1,那么 2 个线程是最合适的。如果 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?是 3 个线程,如下图所示:CPU 在 A、B、C 三个线程之间切换,对于线程 A,当 CPU 从 B、C 切换回来时,线程 A 正好执行完 I/O 操作。这样 CPU 和 I/O 设备的利用率都达到了 100%。

我们会发现,对于 I/O 密集型计算场景,最佳的线程数是与程序中 CPU 计算和 I/O 操作的耗时比相关的,我们可以总结出这样一个公式:
最佳线程数 = 1 +(I/O 耗时 / CPU 耗时)
我们令 R=I/O 耗时 / CPU 耗时,综合上图,可以这样理解:当线程 A 执行 IO 操作时,另外 R 个线程正好执行完各自的 CPU 计算。这样 CPU 的利用率就达到了 100%。
不过上面这个公式是针对单核 CPU 的,至于多核 CPU,也很简单,只需要等比扩大就可以了,计算公式如下:
最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]
四. 总结
主要侧重于线程状态转换的流程,各个线程之间是如何进行状态切换,从量化的角度如何在不同业务场景下,针对不同的业务设置不同线程数,从而在固定硬件架构下,如何设置合理的线程数提高系统性能;
往往在实际的工作中,很多实时多线程适用的场景真的不尽相同,需要结合自身业务特点以及应用情况合理设置,必要使用不当,造成资源浪费.
五.关于我
Hello,我是球小爷,热爱生活,求学七年,工作三载,而今已快入而立之年,如果您觉得对您有帮助那就一切都有价值,赠人玫瑰,手有余香❤️.最后把我最真挚的祝福送给您及其家人,愿众生一生喜悦,一世安康!















 9035
9035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









