







VGG 网络的创新点:通过堆叠多个小卷积核来替代大尺度卷积核,可以减少训练参数,同时能保证相同的感受野。
例如,可以通过堆叠两个 3×3 的卷积核替代 5x5 的卷积核,堆叠三个 3×3 的卷积核替代 7x7 的卷积核。
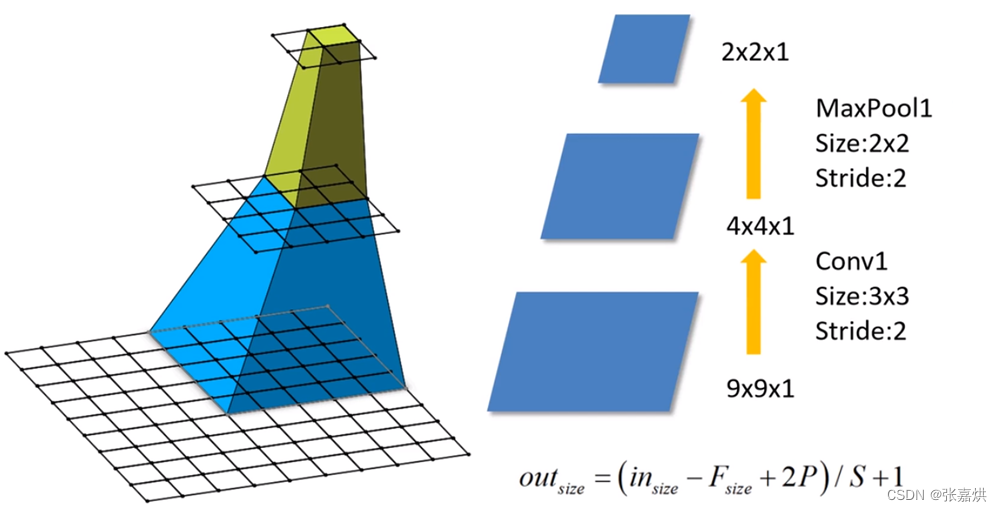
CNN 感受野
输出层 feature map 上的一个单元对应输入层上的区域大小,被称作感受野(receptive field)
如下图所示,输出层 layer3 中一个单元对应输入层 layer2 上区域大小为 2×2 (池化操作),对应输入层 layer1 上大小为5×5
感受野的计算公式为:
- F(i) 为第 i 层感受野
- Stride 为第 i 层的步距
- Ksize 为 卷积核 或 池化核 尺寸
以图中例子计算:可得F(3) = 1、F(2)=(1 − 1) × 2 + 2 = 2、F (1) = (2 − 1) × 2 + 3 = 5,可以理解为 layer2 中 2×2 区域中的每一块对应一个 3×3 的卷积核,又因为 stride=2,所以 layer1 的感受野为 5×5
思考:堆叠3×3卷积核后训练参数是否真的减少了?
CNN参数个数 = 卷积核尺寸 × 卷积核深度 × 卷积核组数 = 卷积核尺寸 × 输入特征矩阵深度 × 输出特征矩阵深度
现假设 输入特征矩阵深度 = 输出特征矩阵深度 = C
使用7×7卷积核所需参数个数:7 × 7 × C × C = 49C²
堆叠三个3×3的卷积核所需参数个数:3 × 3 × C × C + 3 × 3 × C × C + 3 × 3 × C × C = 27C²
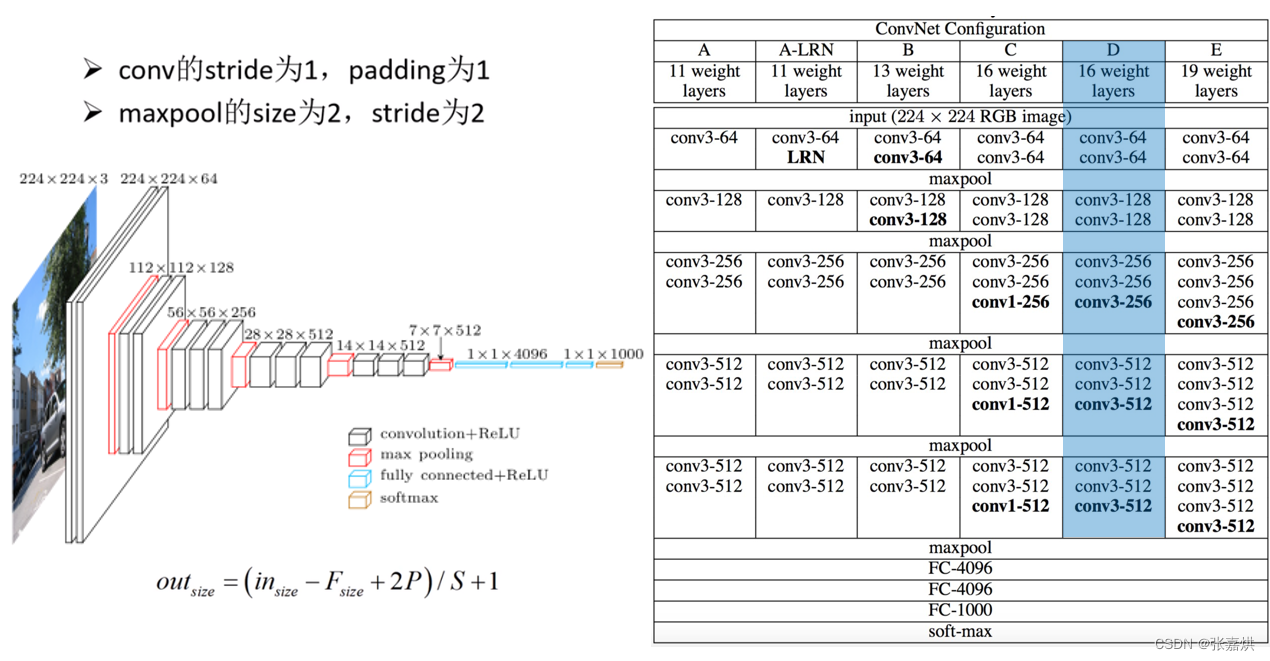
VGG-16
网络结构如下图所示:
搭建VGG网络
model.py
跟 AlexNet 网络模型一样,VGG网络也是分为 卷积层提取特征 和 全连接层进行分类
import torch.nn as nn
import torch
class VGG(nn.Module):
# 初始化函数
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features # 卷积层提取特征
# Sequential()方法是一个容器
self.classifier = nn.Sequential( # 全连接层进行分类
# 每个训练批次中忽略一半的特征检测器,可以明显地减少过拟合现象
nn.Dropout(p=0.5),
# 全连接层
nn.Linear(512*7*7, 2048),
# 非线性激活函数 ReLU
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(True),
nn.Linear(2048, num_classes)
)
if init_weights:
self._initialize_weights()
# 前向传播
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x) # 运行特征提取模块(cfg数据字典里面的结构)
# N x 512 x 7 x 7
# flatten(dim)是对多维数据的降维函数,从第dim个维度开始展开,将后面的维度转化为一维.也就是说,只保留dim之前的维度,其他维度的数据全都挤在dim这一维。
x = torch.flatten(x, start_dim=1) # 展平降维
# N x 512*7*7
# 分类器 self.classifier
x = self.classifier(x)
return x
# 权重初始化
def _initialize_weights(self):
for m in self.modules():
# isinstance 判断一个对象是否是一个已知的类型,类似 type()
if isinstance(m, nn.Conv2d):
# kaiming_normal_ 使用正态分布对输入张量进行赋值,深度学习还存在这样几种模型初始化策略:Constant 、Random 、Xavier
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight) # Xavier均匀分布
if m.bias is not None:
# constant(tensor, val):用val的值填充输入的张量或变量
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# normal(tensor, mean=0, std=1):从给定均值mean和标准差std的正态分布N(mean, std)中生成值,填充输入的张量或变量
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
VGG网络有 VGG-13、VGG-16等多种网络结构,其全连接层完全一样,卷积层只有卷积核个数稍有不同,可以将这几种结构统一在一个模型中。
# vgg网络模型配置列表,数字表示卷积核个数,'M'表示最大池化层
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], # 模型A
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'], # 模型B
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'], # 模型D
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'], # 模型E
}
# 卷积层提取特征
def make_features(cfg: list): # 传入的是具体某个模型的参数列表
layers = []
in_channels = 3 # 输入的原始图像(rgb三通道)
for v in cfg:
# 最大池化层
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
# 卷积层
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
# Sequential()方法是一个容器,描述了神经网络的网络结构,在Sequential()的输入参数中描述从输入层到输出层的网络结构
return nn.Sequential(*layers) # 单星号(*)将参数以元组(tuple)的形式导入
def vgg(model_name="vgg16", **kwargs): # 双星号(**)将参数以字典的形式导入
try:
cfg = cfgs[model_name]
except:
print("Warning: model number {} not in cfgs dict!".format(model_name))
exit(-1)
model = VGG(make_features(cfg), **kwargs)
return model
train.py
训练脚本跟另一篇 AlexNet 基本一致,需要注意的是 batch_size 和 实例化网络的过程。
不同机器 batch_size 可能不同,我这里设置的是16,否则会报 CUDA error
# 实例化网络
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
完整代码
# 导入包
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
import os
import json
import time
from model import vgg
# 使用GPU训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 图像预处理
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪,再缩放成 224×224
transforms.RandomHorizontalFlip(p=0.5), # 水平方向随机翻转,概率为 0.5, 即一半的概率翻转, 一半的概率不翻转
transforms.ToTensor(), # 将输入的数据shape H,W,C ——> C,H,W,将数据归一化到[0,1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# 获取图像数据集的路径
image_path = "../resnet/flower_data/" # flower data_set path
# 导入训练集并进行预处理
train_dataset = datasets.ImageFolder(root=image_path + "/train",
transform=data_transform["train"])
train_num = len(train_dataset)
# Epoch:将所有训练样本训练一次的过程
# Batch:将整个训练样本分成若干个Batch
# Batch Size:一次训练所选取的样本数,Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如GPU内存不大,该数值最好设置小一点。
# 按batch_size分批次加载训练集
train_loader = torch.utils.data.DataLoader(train_dataset, # 导入的训练集
batch_size=16, # 每批训练的样本数
shuffle=True, # 是否打乱训练集
num_workers=0) # 使用线程数,在windows下设置为0
# 导入验证集并进行预处理
validate_dataset = datasets.ImageFolder(root=image_path + "/val",
transform=data_transform["val"])
val_num = len(validate_dataset)
# 加载验证集
validate_loader = torch.utils.data.DataLoader(validate_dataset, # 导入的验证集
batch_size=16,
shuffle=True,
num_workers=0)
# class_to_idx 返回一个字典,类别:索引 {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
# 将 flower_list 中的 key 和 val 调换位置
cla_dict = dict((val, key) for key, val in flower_list.items())
# 将 cla_dict 写入 json 文件中
json_str = json.dumps(cla_dict, indent=4) # 参数根据数据格式缩进显示
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
net.to(device) # 分配网络到指定的设备(GPU/CPU)训练
loss_function = nn.CrossEntropyLoss() # 交叉熵损失,交叉熵主要是用来判定实际的输出与期望的输出的接近程度
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 优化器(训练参数,学习率)
save_path = './vgg.pth'
best_acc = 0.0 # 最佳准确率
for epoch in range(10):
########################################## train ###############################################
net.train() # 训练过程中开启 Dropout
running_loss = 0.0 # 每个 epoch 都会对 running_loss 清零
time_start = time.perf_counter() # 对训练一个 epoch 计时
# enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中
for step, data in enumerate(train_loader, start=0): # 遍历训练集,step从0开始计算
images, labels = data # 获取训练集的图像和标签
optimizer.zero_grad() # 清除历史梯度
outputs = net(images.to(device)) # 正向传播
loss = loss_function(outputs, labels.to(device)) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 优化器更新参数
running_loss += loss.item()
# 打印训练进度(使训练过程可视化)
rate = (step + 1) / len(train_loader) # 当前进度 = 当前step / 训练一轮epoch所需总step
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\rtrain loss: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
print()
print('%f s' % (time.perf_counter()-time_start))
########################################### validate ###########################################
net.eval() # 验证过程中关闭 Dropout
acc = 0.0
with torch.no_grad():
for val_data in validate_loader:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1] # 以output中值最大位置对应的索引(标签)作为预测输出
acc += (predict_y == val_labels.to(device)).sum().item()
val_accurate = acc / val_num
# 保存准确率最高的那次网络参数
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('[epoch %d] train_loss: %.3f test_accuracy: %.3f \n' %
(epoch + 1, running_loss / step, val_accurate))
print('Finished Training')
predict.py
预测脚本跟另一篇 AlexNet 一致
完整代码
import torch
from model import vgg
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
import json
# 预处理
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(), # shape H,W,C ——> C,H,W
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img = Image.open("OIP-C.jpg")
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# unsqueeze()函数起升维的作用,参数表示在哪个地方加一个维度
img = torch.unsqueeze(img, dim=0) # [C, H, W] ——> [N, C, H, W]
# read class_indict
try:
json_file = open('./class_indices.json', 'r')
class_indict = json.load(json_file)
except Exception as e:
print(e)
exit(-1)
# create model
model = vgg(num_classes=5)
# load model weights
model_weight_path = "./vgg.pth"
model.load_state_dict(torch.load(model_weight_path))
# 关闭 Dropout
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img)) # 将输出压缩,即压缩掉 batch 这个维度,[N, C, H, W] ——> [C, H, W]
predict = torch.softmax(output, dim=0) # softmax函数,又称归一化指数函数。目的是将多分类的结果以概率的形式展现出来。
predict_cla = torch.argmax(predict).numpy() # argmax:返回最大值的索引
print(class_indict[str(predict_cla)], predict[predict_cla].item())
plt.show()
class_indices.json
该文件由 train.py 自动生成,文件内容如下
{
"0": "daisy",
"1": "dandelion",
"2": "roses",
"3": "sunflowers",
"4": "tulips"
}















 1519
1519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









