







DeepSeek大模型为何会“一本正经胡说八道”?这份救命指南请收好
深夜两点,某高校宿舍突然爆发一声哀嚎。法律系学生小张绝望地发现,用DeepSeek生成的论文参考文献中,有3篇文献根本不存在。更可怕的是,模型竟然煞有介事地标注了根本不存在的法律条款——这种令人脊背发凉的场景,正在成为AI时代的集体焦虑。
大模型的"幻觉陷阱"远比想象中危险
北京大学王选计算机研究所的测试显示,DeepSeek-R1在摘要任务中的幻觉率高达14.3%,远超行业标杆的2.4%。这意味着每7次关键决策中,就有1次可能被错误信息误导。金融行业已有惨痛教训:某券商使用AI生成的行业分析报告,因虚构数据导致数千万投资失误;医疗领域更发生AI误诊事件,只因模型将"良性肿瘤特征"与"恶性肿瘤指标"混为一谈。
一、大模型为何会"睁眼说瞎话"?
1. 知识拼图的先天缺陷
就像孩童用积木搭建想象中的城堡,大模型通过3000亿token的语料拼接世界观。但当遇到专业领域时,这个"知识拼图"就会出现裂缝。法律条款、医学术语、金融参数,这些需要精确性的领域,恰恰是模型训练数据的盲区。
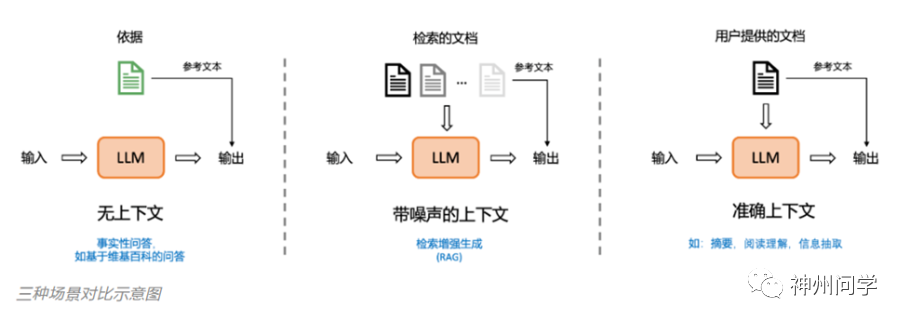
2. 语言流畅性的致命诱惑
Transformer架构赋予大模型惊人的语言天赋,但也埋下隐患。为了保持回答的连贯性,模型宁愿编造看似
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









