







当AI学会思考:DeepSeek如何突破大模型的"系统2"边界?
2016年AlphaGo战胜李世石时,公众惊叹于AI的计算能力;2025年的今天,当我们与AI对话时,却常常产生"它是否真的在思考"的疑惑。这场持续十年的认知革命背后,隐藏着一条从"鹦鹉学舌"到"逻辑推演"的技术进化链。
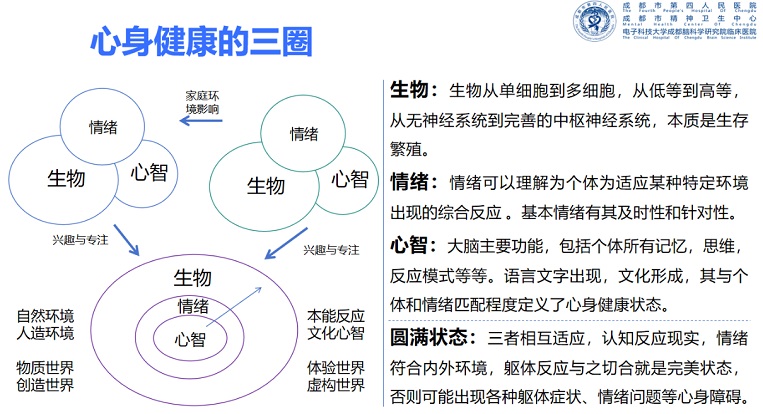
一、从单词接龙到逻辑推演:大模型的认知跃迁
传统语言模型就像精密的文字接龙机器,基于GPT-3.5的ChatGPT首次展现出对话能力时,人类突然意识到:当参数规模突破千亿量级,量变真的能引发质变。这种质变的核心密码,藏在Transformer架构的自注意力机制中。
想象每个单词都长出了"意识触角",在句子中不断与其他词汇建立连接。通过12层甚至32层的神经网络堆叠,这些触角最终编织出对语义的全局理解。正是这种机制,让ChatGPT在2023年展现出拒绝回答不当问题的"价值观",以及根据上下文调整回答详略的"情商"。
但真正的转折点出现在DeepSeek-R1系列模型。这个被称为"系统2"的智能体,通过多阶段强化学习训练,将大模型的推理错误率降低了47%。当ChatGPT还在解释"为什么天空是蓝色"时,DeepSeek已经能推演出不同大气成分对落日颜色的影响梯度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









