







复习笔记,方便手机随时阅读
一、朴素贝叶斯
特性有n维。X=(x1,…,xn),假设各特征相互独立。
任务:分类、生成式模型(建模p(x,y))
预测:用贝叶斯公式算。
训练:给定(x1,y1),…,(xN,yN), 最大化训练数据的对数似然log(P(x1,y1)…P(xn,yn))
得到各个y的先验、x的似然都=频度
平滑:设p(z|t)中,z有K个取值,则频度的分子+1, 分母+K
二、GDA
使用多变量正态分布对 x|y 建模。假设较强。
For k: x|y=k ~ N(μk,∑)
y ~ Bernoulli(β)
任务:分类、生成式模型
预测:用贝叶斯公式算
训练:β和μk 直接用频度和样本平均算;∑=(1/N)*( ∑k (xk-μk)(xk-μk)T)
三、
(1)两类LR
建模 p(y|x)=1/(1+e^(-wt*x)) :logistic函数;其中,1/(1+e^-x)是sigmoid函数
任务:分类、判别式模型
预测:看p(y|x)与0.5大小
训练:最大似然(由于判别式假定了p(x)一样,所以最大似然可以约掉p(x),仅对p(y1|x1)p(y2|x2)…*p(Yn|Xn)最大log似然。然后梯度下降。
(2)多类LR
Softmax取待sigmoid. W1, …, WK都是参数。
训练:最大似然(相当于最小化交叉熵(带入公式化简即可)),然后梯度下降。
四、Fisher线性判别
找一条最易分类的投影线。以得到线性判别函数。
任务:分类
预测:f(x)与T大小
训练:找w. 最大化降至1维后两均值之差除以两类内散度和。
等于
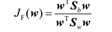
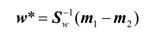
五、感知器
一种训练线性判别函数的算法。预处理:负样本*-1
While Changed:
Changed = False;
W分错则加、Changed=True,分对则减。
六、线性回归(最小二乘)
任务:回归
训练:最小化平方误差,然后梯度下降。
解释:高斯噪声下的最大似然。
正则化LMS:最小化平方误差相当于最大化后验p(w|y)

七、SVM
用间隔表示置信度
任务:分类,判别式
训练:求解二次规划,做题一般肉眼看即可。
八、PCA(又名KL
最小化重构误差 or 最大化投影后的方差
任务:降维,线性模型,无监督
过程:计算协方差矩阵-特征分解-特征值前K大的特征向量为K个投影向量-投影(内积)
九、KMEANS
最小化平方误差和
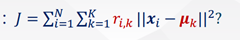
任务:聚类
过程:迭代:找各类中心点,分配点到各类
收敛性:不能保证全局最小,但会收敛。
问题:类间具有不同尺寸、密度、非球型,效果不好。
十、HMM
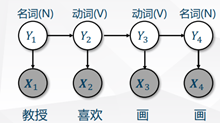
一种概率图模型,给定初始概率、各条件概率。
训练:频度估计概率。
预测:DP算法,注意子问题是 max{y1,…,y_{t-1}} p(x1,x2,…,xt, y1,…,y_{t-1},Yt=yt)
回溯时从T到1选最大的yt即可。














 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









