







Python微信订餐小程序课程视频
https://edu.csdn.net/course/detail/36074
Python实战量化交易理财系统
https://edu.csdn.net/course/detail/35475
线性模型最简单的形式就是输入变量的线性模型,但是,将一组输入变量的非线性函数进行线性组合,我们可以得到一类更加有用的函数,本章我们的讨论重点就是输入变量的非线性函数的线性组合。
1 线性基函数
回归问题最简单的形式就是输入变量的线性函数,即
y(x,w)=w0+w1x1+w2x2+⋯+wDxDy(x,w)=w0+w1x1+w2x2+⋯+wDxDy(\mathbf x,\mathbf w)=w_0+w_1x_1+w_2x_2+\cdots+w_Dx_D
这称为线性回归(linear regression),更一般地
y(x,w)=w0+∑j=1M−1wjϕj(x)y(x,w)=w0+∑j=1M−1wjϕj(x)y(\mathbf x,\mathbf w)=w_0+\sum_{j=1}^{M-1}w_j\phi_j(\mathbf x)
其中ϕj(x)ϕj(x)\phi_j(\mathbf x)称为基函数(basis function),这是线性模型更一般的形式,具有更广泛的应用。参数w0w0w_0使数据中可以存在任意的偏置,故这个值通常称为偏置参数(bias parameter)。通常我们会定义ϕ0(x)=1ϕ0(x)=1\phi_0(\mathbf x)=1,那么此时
y(x,w)=∑j=0M−1wjϕj(x)=wTϕϕ(x)y(x,w)=∑j=0M−1wjϕj(x)=wTϕϕ(x)y(\mathbf x,\mathbf w)=\sum_{j=0}^{M-1}w_j\phi_j(\mathbf x)=\mathbf w^T\pmb\phi(\mathbf x)
其中w=(w0,⋯,wM−1)Tw=(w0,⋯,wM−1)T\mathbf w=(w_0,\cdots,w_{M-1})^T,ϕϕ(x)=(ϕ0(x),⋯,ϕM−1(x))Tϕϕ(x)=(ϕ0(x),⋯,ϕM−1(x))T\pmb\phi(\mathbf x)=(\phi_0(\mathbf x),\cdots,\phi_{M-1}(\mathbf x))^T。
在PRML 基础知识一节中,我们曾经介绍过Polynomial Curve Fitting问题,那时的基函数即为ϕj(x)=xjϕj(x)=xj\phi_j(x)=x^j,这属于多项式基函数,多项基函数在许多场合很有用,但是它的一个局限性在于:它们是输入变量的全局函数,因此输入空间中一个区域的改变会影响到所有其他区域,比如,在顺序学习过程中,当我们有一个新得到的数据点,那么原则上我们只需要修改与之相近的区域,但是在多项式基函数的例子中,新得到一个数据点将会影响到所有区域。另外,如果我们要建立的模型是分段的,那么多项式基函数就有很大的局限性。对于此处出现的问题,我们可以这样解决:把输入空间切分为多个小区域,并对每个小区域用不同的多项式函数拟合。这样的函数叫做样条函数(spline function)。
对于基函数还有其他选择,例如高斯基函数
ϕj(x)=exp{−(x−μj)22s2}ϕj(x)=exp{−(x−μj)22s2}\phi_j(x)=\text{exp}{-\frac{(x-\mu_j)2}{2s2}}
其中μjμj\mu_j控制了基函数在输入空间的位置,参数sss控制了基函数的空间大小。注意,虽然此种基函数称为高斯基函数,但是它未必是一个归一化的概率表达式,其归一化系数并不重要,因为它将与一个调节参数wjwjw_j相乘。另一种基函数的例子是sigmoid基函数,即
ϕj(x)=σ(x−μjs)ϕj(x)=σ(x−μjs)\phi_j(x)=\sigma(\frac{x-\mu_j}{s})
其中σ(x)=11+exp(−x)’ role=“presentation”>σ(x)=11+exp(−x)σ(x)=11+exp(−x)\sigma(x)=\frac{1}{1+\text{exp}(-x)},该函数是S函数(sigmoid function)的一个简单例子。因为我们已经证明S函数的另一个实例双曲正切(hyperbolic tangent)函数等价于logistic sigmoid函数的平移和缩放,即tanh(x)=2σ(2x)−1tanh(x)=2σ(2x)−1\tanh(x)=2\sigma(2x)-1,所以我们也可以选择双曲正切函数作为基函数。下图展示了上述三个基函数的直观图像,从左至右依次为:多项式基函数、高斯基函数、sigmoid基函数
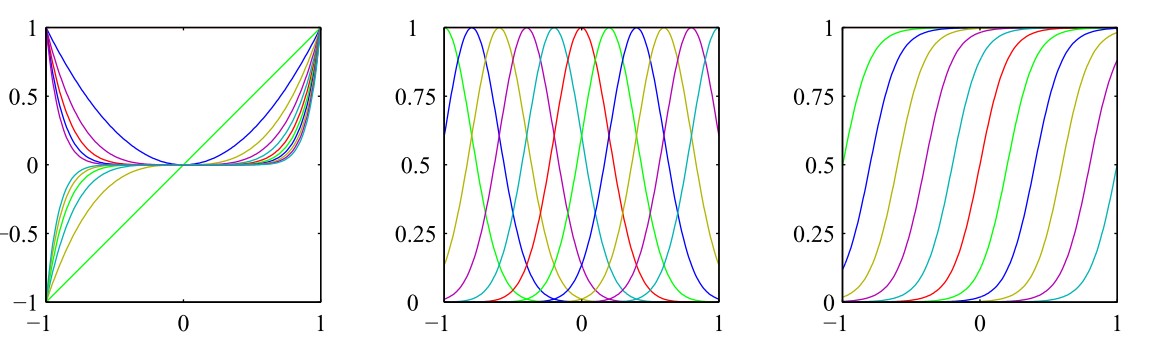
基函数的选择实际上就是为了描述一个函数空间,根据所学知识,傅里叶(Fourier)函数可以描述任意的函数,因此,傅里叶基函数可以被选为基函数,这在信号处理领域是尤其重要的,这种研究产生了一类被称为小波(wavelet)的函数,为了简化应用,这些基函数被选为正交的。
在本章中,我们通常不会关注基函数的具体形式,除非特别说明。
1.1 极大似然与最小平方
对于一般的问题而言,极大似然方法与最小误差方法都是可行的思路,特别地,对于Polynomial Curve Fitting问题来说,就是极大似然与最小平方,现在来详细地讨论最小平方的方法与极大似然方法之间的关系。
假设目标变量ttt由两部分组成:模型y(x,w)y(x,w)y(\mathbf x,\mathbf w)和噪声ϵϵ\epsilon组成,其中噪声ϵϵ\epsilon符合高斯分布(均值为零,精度为ββ\beta),即
t=y(x,w)+ϵt=y(x,w)+ϵt=y(\mathbf x,\mathbf w)+\epsilon
则有
p(t|x,w,β)=N(t|y(x,w),β−1)p(t|x,w,β)=N(t|y(x,w),β−1)p(t|\mathbf x,\mathbf w,\beta)=\mathcal N(t|y(\mathbf x,\mathbf w),\beta^{-1})
从PRML 基础知识5.2小节中知道,当我们新输入一个xx\mathbf x的时候,为使平方损失函数最小,目标变量ttt的预测值应为
E(t|x)=∫tp(t|x)dt=y(x,w)E(t|x)=∫tp(t|x)dt=y(x,w)E(t|\mathbf x)=\int tp(t|\mathbf x)dt=y(\mathbf x,\mathbf w)
注意,噪声的假设说明,给定xxx的条件下,ttt的条件分布是单峰的,这对于⼀些实际应用来说是不合适的,后面一些章节将扩展到条件高斯分布的混合,那种情况下可以描述多峰的条件分布。
现在考虑一个输入数据集X={x1⋯,xN}X={x1⋯,xN}\mathbf X={\mathbf x_1\cdots,\mathbf x_N}和对应的目标值t={t1,⋯,tN}t={t1,⋯,tN}\mathbf t={t_1,\cdots,t_N},于是有如下的似然函数
p(t|X,w,β)=∏n=1NN(tn|wTϕϕ(xn),β−1)p(t|X,w,β)=∏n=1NN(tn|wTϕϕ(xn),β−1)p(\mathbf t|\mathbf X,\mathbf w,\beta)=\prod_{n=1}^N\mathcal N(t_n|\mathbf w^T\pmb\phi(\mathbf x_n),\beta^{-1})
在有监督学习(例如回归问题和分类问题)领域内,我们不是在寻找模型来对输入变量进行概率分布建模,因此xx\mathbf x总会出现在条件变量的位置上,因此此后不再在诸如p(t|x,w,β)p(t|x,w,β)p(\mathbf t|\mathbf x,\mathbf w,\beta)这类表达式中显式地写出xx\mathbf x。对上述似然函数取对数,得到
lnp(t|w,β)=∑n=1NlnN(tn|wTϕϕ(xn),β−1)=∑n=1Nln(1(2πβ−1)1/2exp{−(xn−wTϕϕ(xn))22β−1})=N2lnβ−N2ln(2π)−βED(w)lnp(t|w,β)=∑n=1NlnN(tn|wTϕϕ(xn),β−1)=∑n=1Nln(1(2πβ−1)1/2exp{−(xn−wTϕϕ(xn))22β−1})=N2lnβ−N2ln(2π)−βED(w)\begin{aligned}
\ln p(\mathbf t|\mathbf w,\beta)&=\sum_{n=1}^N\ln\mathcal N(t_n|\mathbf w^T\pmb\phi(\mathbf x_n),\beta^{-1})\
&=\sum_{n=1}N\ln(\frac{1}{(2\pi\beta{-1})^{1/2}}\text{exp}{-\frac{(\mathbf x_n-\mathbf w^T\pmb\phi(\mathbf x_n))2}{2\beta{-1}}})\
&=\frac{N}{2}\ln\beta-\frac{N}{2}\ln(2\pi)-\beta E_D(\mathbf w)
\end{aligned}
其中平方误差和函数为
ED(w)=12∑n=1N{tn−wTϕϕ(xn)}2ED(w)=12∑n=1N{tn−wTϕϕ(xn)}2E_D(\mathbf w)=\frac12\sum_{n=1}^N{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)}^2
这样,我们就得到了一个重要的结论:当噪声符合高斯分布时,极大似然方法等价于最小化平方和误差函数方法,特别地,当我们添加一个惩罚项(以保证不会过拟合)的时候,该结论仍然成立,这在PRML 基础知识的2.3小节中出现过。下面用极大似然方法确定参数ww\mathbf w和ββ\beta,上述对数似然函数对ww\mathbf w求偏导得到
∇lnp(t|w,β)=β∑n=1N{tn−wTϕϕ(xn)}ϕϕ(xn)T=0∇lnp(t|w,β)=β∑n=1N{tn−wTϕϕ(xn)}ϕϕ(xn)T=0\nabla\ln p(\mathbf t|\mathbf w,\beta)=\beta\sum_{n=1}^N{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)}\pmb\phi(\mathbf x_n)^T=0
解得
wML=(ΦTΦ)−1ΦTtwML=(ΦTΦ)−1ΦTt\mathbf w_{ML}=(\mathbf\PhiT\mathbf\Phi){-1}\mathbf\Phi^T\mathbf t
这被称为最小平方问题的规范方程(normal equation),其中ΦΦ\mathbf\Phi是一个N×MN×MN\times M的矩阵,被称为设计矩阵(design matrix)
Φ=⎛⎝⎜⎜⎜⎜ϕ0(x1)ϕ0(x2)⋮ϕ0(xN)ϕ1(x1)ϕ1(x2)⋮ϕ1(xN)⋯⋯⋯ϕM−1(x1)ϕM−1(x2)⋮ϕM−1(xN)⎞⎠⎟⎟⎟⎟Φ=(ϕ0(x1)ϕ1(x1)⋯ϕM−1(x1)ϕ0(x2)ϕ1(x2)⋯ϕM−1(x2)⋮⋮⋮ϕ0(xN)ϕ1(xN)⋯ϕM−1(xN))\mathbf\Phi=
\left(
\begin{array}
{cccc}
\phi_0(\mathbf x_1) & \phi_1(\mathbf x_1) & \cdots & \phi_{M-1}(\mathbf x_1)\
\phi_0(\mathbf x_2) & \phi_1(\mathbf x_2) & \cdots & \phi_{M-1}(\mathbf x_2)\
\vdots & \vdots & & \vdots\
\phi_0(\mathbf x_N) & \phi_1(\mathbf x_N) & \cdots & \phi_{M-1}(\mathbf x_N)
\end{array}
\right)
现令Φ†=(ΦTΦ)−1ΦTΦ†=(ΦTΦ)−1ΦT\mathbf\Phi{\dagger}=(\mathbf\PhiT\mathbf\Phi){-1}\mathbf\PhiT,称为矩阵ΦΦ\mathbf\Phi的Moore-Penrose伪逆矩阵(pseudo-inverse matrix),可以视为逆矩阵概念对于非方阵的推广,如果矩阵ΦΦ\mathbf\Phi是方阵且可逆,那么有Φ−1=Φ†Φ−1=Φ†\mathbf\Phi{-1}=\mathbf\Phi{\dagger}。另外,当ΦTΦΦTΦ\mathbf\Phi^T\mathbf\Phi接近奇异矩阵时,直接求解规范方程会导致数值计算上的困难,此时可以通过奇异值分解(singular value decomposition or SVD)的方法解决。注意, 正则项的添加确保了矩阵是非奇异的。
对于偏置参数w0w0w_0,如果我们显式地写出它,那么误差函数变为
ED(w)=12∑n=1N{tn−w0−∑j=1M−1wjϕj(xn)}2ED(w)=12∑n=1N{tn−w0−∑j=1M−1wjϕj(xn)}2E_D(\mathbf w)=\frac12\sum_{n=1}N{t_n-w_0-\sum_{j=1}{M-1}w_j\phi_j(\mathbf x_n)}^2
令其关于w0w0w_0的导数为零,解得
w0=t¯−∑j=1M−1wjϕj¯,t¯=1N∑n=1Ntn,ϕj¯=1N∑n=1Nϕj(xn)w0=t¯−∑j=1M−1wjϕj¯,t¯=1N∑n=1Ntn,ϕj¯=1N∑n=1Nϕj(xn)w_0=\bar{t}-\sum_{j=1}^{M-1}w_j\bar{\phi_j},
\quad\bar{t}=\frac1N\sum_{n=1}^Nt_n,
\quad\bar{\phi_j}=\frac1N\sum_{n=1}^N\phi_j(\mathbf x_n)
因此w0w0w_0的作用就是补偿了目标值的平均值与基函数的值的平均值的加权求和之间的差。
类似地,上述对数似然函数对ββ\beta求偏导得到
∇lnp(t|w,β)=N2β−12∑n=1N{tn−wTϕϕ(xn)}2=0∇lnp(t|w,β)=N2β−12∑n=1N{tn−wTϕϕ(xn)}2=0\nabla\ln p(\mathbf t|\mathbf w,\beta)=\frac{N}{2\beta}-\frac12\sum_{n=1}^N{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)}^2=0
解得
1βML=1N∑n=1N{tn−wTMLϕϕ(xn)}21βML=1N∑n=1N{tn−wMLTϕϕ(xn)}2\frac{1}{\beta_{ML}}=\frac1N\sum_{n=1}^N{t_n-\mathbf w_{ML}^T\pmb\phi(\mathbf x_n)}^2
因此我们看到噪声精度的倒数由目标值在回归函数周围的残留方差(residual variance)给出。
3.2 顺序学习
顺序学习在数据集非常大或者数据点依次到达的情况下非常有用,一个常用的方法是随机梯度下降(stochastic gradient descent)或者称为顺序梯度下降(sequential gradient descent)
w(τ+1)=w(τ)−η∇Enw(τ+1)=w(τ)−η∇En\mathbf w^{(\tau+1)}=\mathbf w^{(\tau)}-\eta\nabla E_n
其中ττ\tau表示迭代次数,ηη\eta是学习率参数,EnEnE_n表示误差函数,对于平方和误差函数而言
w(τ+1)=w(τ)+η(tn−w(τ)Tϕϕ(xn))ϕϕ(xn)w(τ+1)=w(τ)+η(tn−w(τ)Tϕϕ(xn))ϕϕ(xn)\mathbf w^{(\tau+1)}=\mathbf w^{(\tau)}+\eta(t_n-\mathbf {w{(\tau)}}T\pmb\phi(\mathbf x_n))\pmb\phi(\mathbf x_n)
这和PRML 概率分布中3.9小节介绍的Robbins-Monro方法有相通的地方,该方法称为最小均方(least-mean-squares or LMS)算法,其中ηη\eta的值需要仔细选取以保证收敛。
3.3 正则化最小平方
向误差函数中添加正则项,总误差函数变成了
12∑n=1N{tn−wTϕϕ(xn)}2+λ2wTw12∑n=1N{tn−wTϕϕ(xn)}2+λ2wTw\frac12\sum_{n=1}^N{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)}^2+\frac\lambda2\mathbf w^T\mathbf w
并给出如下定义
ED(w)EW(w)=12∑n=1N{tn−wTϕϕ(xn)}2=12wTwED(w)=12∑n=1N{tn−wTϕϕ(xn)}2EW(w)=12wTw\begin{aligned}
E_D(\mathbf w)&=\frac12\sum_{n=1}^N{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)}^2\
E_W(\mathbf w)&=\frac12\mathbf w^T\mathbf w
\end{aligned}
则可记总误差函数为ED(w)+λEW(w)ED(w)+λEW(w)E_D(\mathbf w)+\lambda E_W(\mathbf w)。注意,正则化项并不是唯一的,但其中最简单的形式就是λ2wTwλ2wTw\frac\lambda2\mathbf w^T\mathbf w。这种对于正则化项的选择方法在机器学习文献中称为权值衰减(weight decay),因为在顺序学习中,它倾向于让权值向零的方向衰减,除非有数据支持;在统计学中,它提供了一个参数收缩(parameter shrinkage)的例子,因为这种方法把参数的值向零的方向收缩。将上述总误差函数对ww\mathbf w求偏导并令其为零,解得
w=(λI+ΦTΦ)−1ΦTtw=(λI+ΦTΦ)−1ΦTt\mathbf w=(\lambda\mathbf I+\mathbf\PhiT\mathbf\Phi){-1}\mathbf\Phi^T\mathbf t
这是wML=(ΦTΦ)−1ΦTtwML=(ΦTΦ)−1ΦTt\mathbf w_{ML}=(\mathbf\PhiT\mathbf\Phi){-1}\mathbf\Phi^T\mathbf t的一个扩展。
正则化项可以选取其他形式,更一般地,总误差函数为
12∑n=1N{tn−wTϕϕ(xn)}2+λ2∑j=1M|wj|q12∑n=1N{tn−wTϕϕ(xn)}2+λ2∑j=1M|wj|q\frac12\sum_{n=1}^N{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)}2+\frac\lambda2\sum_{j=1}M|w_j|^q
其中q=1q=1q=1的情形称为套索(lasso),它的性质是:如果λλ\lambda合理地大,那么某些系数wjwjw_j将会等于零,从而产生了一个稀疏(sparse)模型。我们注意到最小化上述的总误差函数等价于在∑Mj=1|wj|q≤η∑j=1M|wj|q≤η\sum_{j=1}M|w_j|q\leq\eta(其中ηη\eta是选取的合适的值)的条件下将12∑Nn=1{tn−wTϕϕ(xn)}212∑n=1N{tn−wTϕϕ(xn)}2\frac12\sum_{n=1}^N{t_n-\mathbf w^T\pmb\phi(\mathbf x_n)}2进行最小化,不妨令∑Mj=1|wj|q=η∑j=1M|wj|q=η\sum_{j=1}M|w_j|^q=\eta,那么这通过拉格朗日乘数法很容易求解。下面两幅图说明了q=1q=1q=1时稀疏性的来源
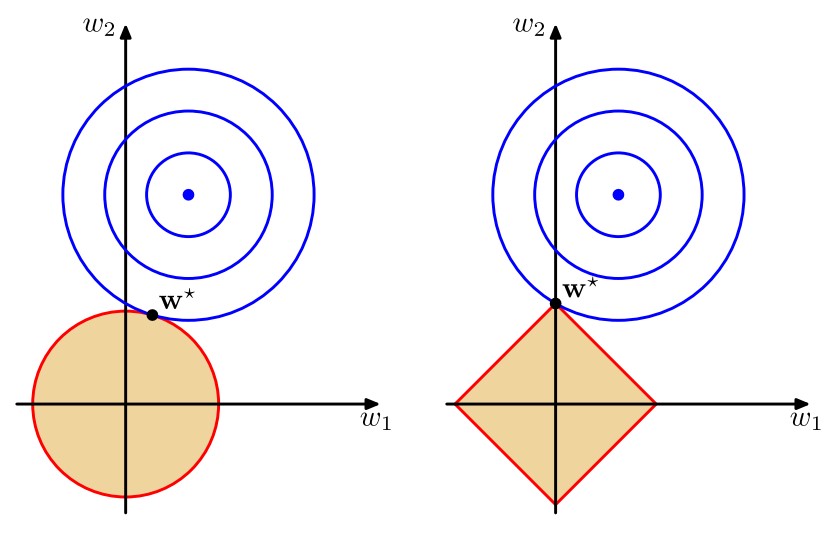
第一幅图给出了不同的qqq值对应的正则项的轮廓线,第二幅图中蓝色同心圆即为12∑Nn=1{tn−wTϕϕ(xn)}212∑n=1N{tn−wTϕϕ(xn)}2\frac12\sum_{n=1}^N{t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











