







1. 前言
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消息,RDD的数据只在处理的过程中存在,一旦处理完成,就不见了,所以RDD的数据是过程数据。
RDD数据是过程数据的这个特性可以最大化的利用资源,老旧的RDD没用了就会从内存中清理,给后续的计算腾出内存空间。
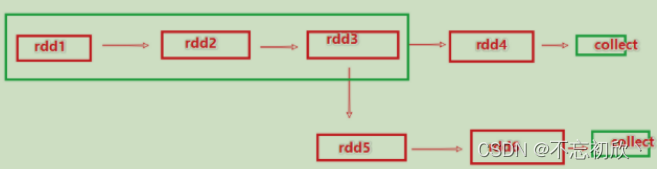
如上图,rdd3被2次使用,第一次使用之后,其实rdd3就不存在了,在第二次使用的时候,只能基于RDD的血缘关系,从RDD1重新执行,构建出来RDD3,供RDD5使用。
2. RDD的缓存
Spark中提供了缓存API,可以让我们通过调用API,将指定的RDD数据保留在内存或者硬盘上。上述场景如果使用缓存API,RDD3就不会消失,第二次使用RDD3的时候就不会在通过血缘关系重新开始构建出RDD3
# RDD3 被2次使用,可以加入缓存进行优化
rdd3.cache() # 缓存到内存中.
rdd3.persist(StorageLevel.MEMORY_ONLY) # 仅内存缓存
rdd3.persist(StorageLevel.MEMORY_ONLY_2) # 仅内存缓存,2个副本
rdd3.persist(StorageLevel.DISK_ONLY) # 仅缓存硬盘上
rdd3.persist(StorageLevel.DISK_ONLY_2) # 仅缓存硬盘上,2个副本
rdd3.persist(StorageLevel.DISK_ONLY_3) # 仅缓存硬盘上,3个副本
rdd3.persist(StorageLevel.MEMORY_AND_DISK) # 先放内存,不够放硬盘
rdd3.persist(StorageLevel.MEMORY_AND_DISK_2) # 先放内存,不够放硬盘,2个副本
rdd3.persist(StorageLevel.OFF_HEAP) # 堆放内存(系统内存)
# 如上API,自行选择使用即可
# 一般建议使用rdd3.persist(StorageLevel.MEMORY_AND_DISK)
# 如果内存比较小的集群,建议使用rdd3.persist(StorageLevel.DISK_ONLY) 或者别用缓存了 用CheckPoint
# 主动清理缓存的API
rdd.unpersist()
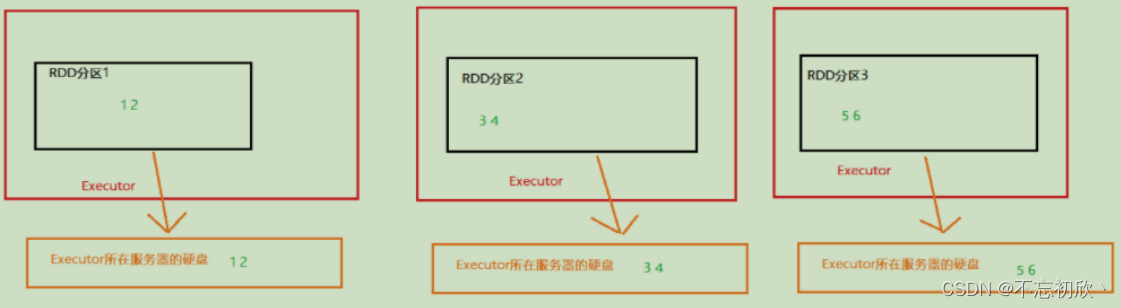
如上图,RDD是将自己分区的数据,每个分区自行将其数据保存在其所在的Executor内存和硬盘上,这就是分散存储。
缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上,但是这个保存在设定上是认为不安全的,存在丢失的风险,所以缓存有一个特点就是保存RDD之间的血缘关系。
一旦缓存丢失,可以基于血缘关系的记录,重新计算这个RDD的数据。
缓存一般是如果丢失的?
- 在内存中的存储是不安全的,比如断电\计算任务内存不足,把缓存清理给计算让路
- 硬盘中因为硬盘的损坏也是可能丢失的
3. RDD的CheckPoint
Spark中Checkpoint技术,也是将RDD的数据保存起来,但是它只支持硬盘存储,并且它被设计认为是安全的,不保留血缘关系。
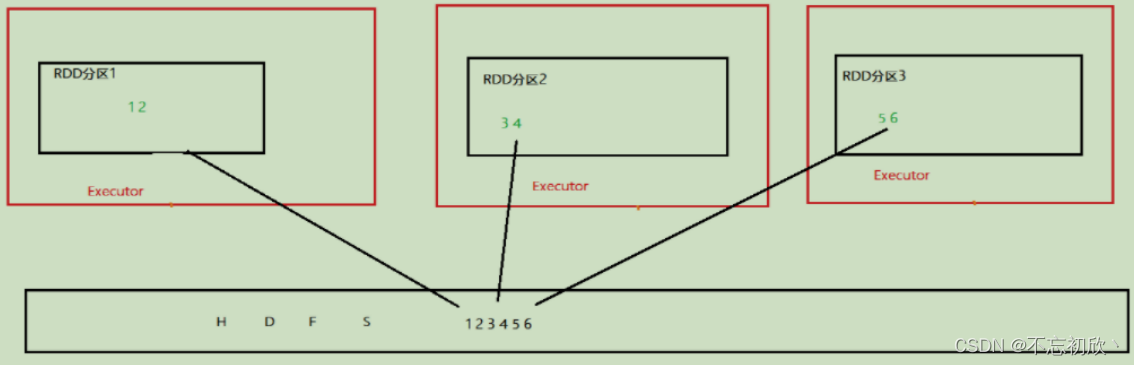
如上图,Checkpoint存储的RDD数据是集中收集各个分区的数据进行存储,而缓存是分散存储
缓存和Checkpoint的对比:
- CheckPoint不管分区数量多少,风险都一样。 缓存:分区越多,风险越多
- CheckPoint支持写入HDFS,缓存不行。HDFS是高可靠存储,CheckPoint被认为是安全的
- CheckPoint不支持内存,缓存可以。缓存如果写内存 性能比 CheckPoint 要好一些
- CheckPoint因为设计是安全的,所以
不保留血缘关系,而缓存则相反。
实现:
# 设置CheckPoint第一件事情,选择Checkpoint的保存路径
# 如果Local模式,可以支持本地文件系统,如果在集群运行,千万要用HDFS
sc.setCheckpointDir("hdfs://master:8020/output/11111")
# 用的时候,直接调用checkpoint算子即可,但是需要有action算子触发
rdd.checkpoint()
rdd.count()
# TODO: 再次执行count函数, 此时从checkpoint读取数据
rdd.count()
Checkpoint是一种重量级的使用,也就是RDD的重新计算成本很高的时候,我们采用Checkpoint比较合适,或者数据量很大的时候,采用Checkpoint比较合适。如果数据量小,或者RDD重新计算也是非常快的,直接使用缓存即可。
**注意:**Spark中缓存和Checkpoint两个API都不是action算子,所以需要后面跟action算子才能触发。















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









