







树
树是一种数据结构。它的特点如下:
- 每个节点有零个或多个子节点。没有父节点的节点称为根节点
- 每一个非根节点有且只有一个父节点除了根节点外,每个子节点可以分为多个不相交的子树
如下图就是一颗树
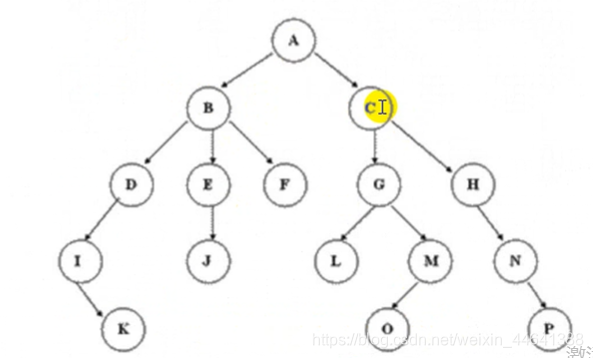
相关术语:
- 节点的度: 一个节点(上图中一个圆圈就是一个节点)含有的子节点的个数称为该节点的度。( 上图A节点的度为2 B节点的度为3 J节点的度为0 )
- 树的度: 一棵树中,最大的节点的度称为树的度(.上图B节点的度为3,最大)
- 叶节点或终端节点: 没有子节点的节点称为叶子节点。也即度为0的节点(上图KOP三个节点均为叶子节点)
- 父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点(上图A是BC的父节点B是DEF的父节点)
- 子节点:一个节点含有的子树的根节点称为该节点的子节点(.上图BC是A的子节点DEF是B的子节点)
- 兄弟节点:具有相同父节点的节点互称为兄弟节点( 上图BC DEF LM是相互的兄弟节点)
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推(上图A为第1层BC第2层DEFGH第三层.. )
- 树的高度或深度: 树中节点的最大层次(上图为5层)
- 子树:每个节点都可以作为子树的根,它和它所有的子节点,子节点的子节点等都包含在子树中。
度与节点数量的关系:
已知一棵树的情形如下
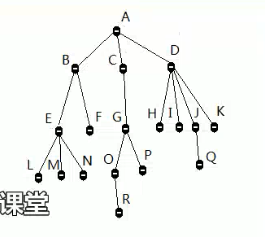
该树含有: 度为0的节点10个,含有度为1的节点3个,含有度为2的节点2个,含有度为3的节点2个,含有度为4的节点1个,
故该树的总节点数量为(0 * 10)+ (1 * 3)+(2 * 2)+(3 * 2)+(4 * 1)+ 1 == 18
计算公式为:总结点个数 = 所有 (节点的度 * 该度所对应的节点数量 ) 的总和 + 1
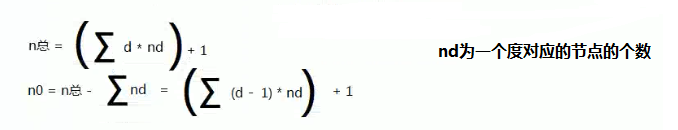
树的遍历方式(后面会具体分析)
- 深度优先遍历。比如上面那棵树遍历结果是:A-->B-->E-->L-->M-->N-->F-->C-->G-->O-->R-->P-->D-->H-->I-->J-->Q-->K
- 广度优先遍历(层序遍历):即逐层遍历,由A到R依次遍历。
二叉树
每个节点最多只能有两个子节点的一种形式称为二叉树。二叉树的子节点分为左节点和右节点。
满二叉树
除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。一颗高度为n的满二叉树,其节点个数为2^n-1
完全二叉树
将一颗满二叉树的所有节点,依次从上至下,从左至右从1开始连续编号;然后将最后若干个编号最大的节点删除,使得删除后的节点的编号依然从1开始是连续编号;剩下的节点所形成的二叉树,称为“完全二叉树”。
通过图也可以清晰看到完全二叉树节点它的编号确实是连续的啊。如果从1开始编号,通过这种连续编号的方式,我们可以计算出来每个节点左孩子和右孩子的位置。这么看的话,如果使用顺序存储结构存储这些节点我们也可以像访问树型结构一样地访问它们。只不过不再通过引用直接访问,而是改成计算的方式访问每个节点。所以将完全二叉树看成是一个数组或者链表都是可以的。
完全二叉树的总节点与叶子节点数量的关系
叶子节点数量 = (总结点数量 + 1)/ 2
二叉树的三种遍历方式介绍
- 先根序:根--->左子树--->右子树
- 中根序:左子树--->根--->右子树
- 后根序:左子树--->右子树--->根
为了能够用代码的方式体现这三种遍历方式,就需要首先构建一棵树。于是回忆之前教主所讲的括号匹配法生成一颗二叉树。现在以java代码体现出来。
需求:输入一个一定规则字符串,得到一颗构建好的树的对象。
括号匹配法生成一颗二叉树:
用一个字符表示一个树的节点,该节点的左孩子与右孩子需要用一对括号括起来,紧跟在该节点的后面,左孩子与右孩子中间需要以逗号分隔开来。语言表达我不太在行,可以参照如下示例:
为了规范字符串的写法,也为了方便编写程序,我列举出来一个状态变迁图,将字符串与构建二叉树结合起来,也作为编程的依据。如下:

上图中给出的每一种状态只是为了方便处理下一个遇到的字符,举个例子来说,根节点状态下的下一个字符只能是‘('。
思路分析:
- 每处理一个字符都转换为相应的状态来规范检查下一个字符。如果符合书写要求则处理再转换状态。否则就无法处理
- 如何正确构建一颗二叉树呢? 利用栈这种数据结构。 每当遇到左括号,我让左括号前的一个字母入栈。因为遇到一个左括号就说明以左括号前面字母表示的根节点需要构建子树(子树也可能有子树)了;每当遇到右括号,我让栈顶元素出栈,就说明以该栈顶元素为根节点的子树构建完成。遇到逗号只需改变状态然后略过即可,主要是以逗号区分是左孩子或是右孩子。
public class BinaryTree {
//标识状态
private static final int BTREE_STATUS_BEGIN = 0;
private static final int BTREE_STATUS_LEFT = 1;
private static final int BTREE_STATUS_RIGHT = 2;
private static final int BTREE_STATUS_COMMA = 3;
private static final int BTREE_STATUS_ROOT = 4;
private static final int BTREE_STATUS_CHILD = 5;
private TreeNode root; //树根
private int status; //当前状态
private Stack<TreeNode> stack; //存储一个子树的根节点
private TreeNode curNode; //当前需要入栈的节点
public BinaryTree() {
status = BTREE_STATUS_BEGIN;
stack = new Stack<TreeNode>();
}
public void createTreeByString(String str) {
for(int index = 0; index < str.length(); index++) {
char c = str.charAt(index);
if(status == BTREE_STATUS_BEGIN) {
dealStatusBegin(c, index);
}else if(status == BTREE_STATUS_ROOT) {
dealStatusRoot(c,index);
}else if(status == BTREE_STATUS_LEFT) {
dealStatusLeft(c, index);
}else if(status == BTREE_STATUS_CHILD) {
dealStatusChild(c,index);
}else if(status == BTREE_STATUS_COMMA) {
dealStatusComma(c, index);
}else if(status == BTREE_STATUS_RIGHT) {
dealStatusRight(c, index);
}
}
dealLast();
}
//检测书写规范,如果到最后栈不为空的话就说明,有些节点没有书写右括号
private void dealLast() throws CreateTreeException {
if(stack.isEmpty()) {
return;
}
StringBuffer sb = new StringBuffer("请您仔细一点: ");
while(!stack.isEmpty()) {
sb.append("[" + stack.pop().value + "] ");
}
sb.append("没有匹配到右括号");
throw new CreateTreeException(sb.toString());
}
private void dealStatusComma(char c, int index) throws CreateTreeException {
if(c == ')') {
//栈顶元素出栈
this.stack.pop();
this.status = BTREE_STATUS_RIGHT;
}else if(isAlphabet(c)) {
TreeNode topNode = this.stack.peek();
//由于可能存在这种写法 E(H,I,O) 当一个根已经添加过右孩子,则不应该再次添加右孩子,否则会造成覆盖。故需要判断
if(topNode.rightNode != null) {
throw new CreateTreeException("挖太多咧!");
}
//创建节点将其作为以栈顶元素为根的右孩子
this.curNode = new TreeNode(c);
topNode.rightNode = curNode;
this.status = BTREE_STATUS_CHILD;
}else {
throw new CreateTreeException("非法字符[" + index + "]");
}
}
private void dealStatusRight(char c, int index) throws CreateTreeException {
if(c == ',') {
this.status = BTREE_STATUS_COMMA;
}else if(c == ')') {
this.stack.pop();
}else {
throw new CreateTreeException("非法字符[" + index + "]");
}
}
private void dealStatusChild(char c, int index) throws CreateTreeException {
if(c == '(') {
//当前节点入栈
stack.push(this.curNode);
this.status = BTREE_STATUS_LEFT;
}else if(c == ')') {
//栈顶元素出栈----标志着以栈顶元素为根的一个子树构造完毕
stack.pop();
this.status = BTREE_STATUS_RIGHT;
}else if(c == ',') {
this.status = BTREE_STATUS_COMMA;
}else{
throw new CreateTreeException("非法字符[" + index + "]");
}
}
private void dealStatusLeft(char c, int index) throws CreateTreeException {
//如果是字母,左括号后面的字母一定是左孩子
if(isAlphabet(c)) {
this.curNode = new TreeNode(c);
//获取栈顶元素,并将该节点作为以栈顶元素为根的左子树
TreeNode topNode = stack.peek();
topNode.leftNode = curNode;
this.status = BTREE_STATUS_CHILD;
}else if(c == ',') {
this.status = BTREE_STATUS_COMMA;
}else if(c == ')') {
stack.pop();
this.status = BTREE_STATUS_RIGHT;
}else{
throw new CreateTreeException("非法字符[" + index + "]");
}
}
private void dealStatusRoot(char c, int index) throws CreateTreeException {
if(c == '(') {
//遇到左括号时当前节点入栈
stack.push(this.curNode);
this.status = BTREE_STATUS_LEFT;
}else{
throw new CreateTreeException("非法字符[" + index + "]");
}
}
private void dealStatusBegin(char c, int index) throws CreateTreeException {
//开始状态即字符串第一个字符只能是英文字母
if(isAlphabet(c)) {
this.root = new TreeNode(c);
//根节点设置为当前节点
this.curNode = this.root;
this.status = BTREE_STATUS_ROOT;
}else {
throw new CreateTreeException("出师未捷身先死");
}
}
//判断是否为英文字母
private boolean isAlphabet(char c) {
return (c >= 'A' && c <= 'Z') || (c >= 'a' && c <= 'z');
}
//树节点的数据结构
class TreeNode{
char value;
private TreeNode leftNode;
private TreeNode rightNode;
public TreeNode(char value) {
this.value = value;
}
}
}
如果需要检测树是否构建好则需要加上遍历方式。现在先来检测一下那些不符合书写规范的写法:

三序遍历方式的代码实现
利用递归的方式可以实现三种遍历方式。以先根序为例,无非就是先输出一个树的根节点,在遍历其左子树,遍历完左子树再遍历右子树。在遍历子树的过程中又是以子树的根为根重复上述流程,其他两种方式道理一样。故添加代码如下:
public class BinaryTree {
private TreeNode root; //树根
public void preOrder() {
if(this.root != null) {
this.root.preOrder();
}else {
System.out.println("当前二叉树为空");
}
}
public void infixOrder() {
if(this.root != null) {
this.root.infixOrder();
}else {
System.out.println("当前二叉树为空");
}
}
public void postOrder() {
if(this.root != null) {
this.root.postOrder();
}else {
System.out.println("当前二叉树为空");
}
}
class TreeNode{
char value;
private TreeNode leftNode;
private TreeNode rightNode;
public TreeNode(char value) {
this.value = value;
}
//先根序遍历方法
public void preOrder() {
System.out.print(this.value + " "); //先输出父节点
if(this.leftNode != null) {
this.leftNode.preOrder();
}
if(this.rightNode != null) {
this.rightNode.preOrder();
}
}
//中根序遍历方法
public void infixOrder() {
//递归向左子树遍历
if(this.leftNode != null) {
this.leftNode.infixOrder();
}
System.out.print(this.value + " "); //输出根节点
if(this.rightNode != null) {
this.rightNode.infixOrder();
}
}
//后根序遍历方法
public void postOrder() {
if(this.leftNode != null) {
this.leftNode.postOrder();
}
if(this.rightNode != null) {
this.rightNode.postOrder();
}
System.out.print(this.value + " ");
}
}
}我们来构建下面的这颗树验证
public static void main(String[] args) {
String str = "A(B(D(F,G(J))),C(E(H,I)))";
BinaryTree binaryTree = new BinaryTree();
binaryTree.createTreeByString(str);
System.out.println("先根序遍历结果:");
binaryTree.preOrder();
System.out.println("\n中根序遍历结果:");
binaryTree.infixOrder();
System.out.println("\n后根序遍历结果:");
binaryTree.postOrder();
}结果如下:

非递归方式遍历
如果数据量大的情况下,采用递归方式可能会造成方法栈溢出。所以采用堆栈方式遍历是较好的。
先根序
//方式一
public void preOrderByStack() {
if(root == null) {
return;
}
Stack<TreeNode> stack = new Stack<TreeNode>();
TreeNode treeNode = root;
while(treeNode != null || !stack.isEmpty()) {
while(treeNode != null) {
//这里先访问根
System.out.print(treeNode.value + " ");
//这里是唯一的入栈操作 压入了左子节点
stack.push(treeNode);
treeNode = treeNode.leftNode;
}
if(!stack.isEmpty()) {
treeNode = stack.pop();
treeNode = treeNode.rightNode;
}
}
}
//先根序遍历方式二
public void preOrderByStack2() {
if(root == null) {
return;
}
Stack<TreeNode> stack = new Stack<TreeNode>();
//先将根压入栈
stack.push(root);
TreeNode topNode = null;
while(!stack.isEmpty()) {
topNode = stack.pop();
System.out.print(topNode.value + " ");
if(topNode != null && topNode.rightNode != null) {
stack.push(topNode.rightNode);
}
if(topNode != null && topNode.leftNode != null) {
stack.push(topNode.leftNode);
}
}
}
中根序
中根序与先根序的第一种方式类似,只不过访问的时机不同。
//堆栈方式中根序遍历 左-->根-->右
public void infixOrderByStack() {
if(root == null) {
return;
}
Stack<TreeNode> stack = new Stack<TreeNode>();
TreeNode treeNode = root;
while(treeNode != null || !stack.isEmpty()) {
//首先是根入栈 然后让其所有沿途的左子树的根全部入栈
while(treeNode != null) {
stack.push(treeNode);
treeNode = treeNode.leftNode;
}
if(!stack.isEmpty()) {
//到这里已经是栈顶元素已经没有左子节点了 让其出栈
treeNode = stack.pop();
//输出这个一个子树中最左边的节点
System.out.print(treeNode.value + " ");
//这里是输出完了之后才去压右子树. 保证右是最后边输出的
treeNode = treeNode.rightNode;
}
}
}后根序
//标志位法
public void postOderByStack2() {
TreeNode cur = root;
TreeNode last = null;
Stack<TreeNode> stack = new Stack<TreeNode>();
while(cur != null || !stack.isEmpty()) {
while(cur != null) {
stack.push(cur);
cur = cur.leftNode;
}
cur = stack.peek();
if(cur.rightNode != null && last != cur.rightNode) {
cur = cur.rightNode;
}else{
last = cur;
stack.pop();
System.out.print(cur.value + " ");
/**
* cur置空作用在于当原栈顶结点被访问并弹出后,下一层while是将当前栈顶节点的左子树入栈,
* 当前栈顶节点的左子树已经被遍历过, 因此会造成死循环,所以将cur置空,直接考虑当前栈顶点的右子树
* 一旦某个节点入栈,首先会遍历这个节点的左子树,然后考虑右子树的情况
*/
cur = null;
}
}
}
//双栈法
public void postOderByStack() {
if(root == null) {
return;
}
Stack<TreeNode> stack1 = new Stack<TreeNode>();
Stack<TreeNode> stack2 = new Stack<TreeNode>();
TreeNode treeNode = root;
while(treeNode != null || !stack1.isEmpty()) {
while(treeNode != null) {
stack1.push(treeNode);
stack2.push(treeNode);
treeNode = treeNode.rightNode;
}
if(!stack1.isEmpty()) {
treeNode = stack1.pop();
treeNode = treeNode.leftNode;
}
}
while(!stack2.isEmpty()) {
treeNode = stack2.pop();
System.out.print(treeNode.value + " ");
}
}二叉树节点的查找
能够遍历到就能查找到。所以相应的我们可以用三序遍历的方式找到某一个节点。我们假设上面那颗二叉树是从A---J依次编号为1---10,用编号来查找,方式如下:
public void preOrderSearch(int index) {
if(this.root != null) {
TreeNode treeNode = this.root.preOrderSearch(index);
if(treeNode != null) {
System.out.println("找到编号为[" + index+ "]的节点---->[" + treeNode.value + "]");
}else {
System.out.println("不存在该节点");
}
}else {
System.out.println("当前二叉树为空");
}
}
//先根序查找
public TreeNode preOrderSearch(int index) {
//如果是根节点就直接返回
if(this.value - 64 == index) {
return this;
}
TreeNode result = null;
if(result == null && this.leftNode != null) {
result = this.leftNode.preOrderSearch(index);
}
//在左子树中找到
if(result != null) {
return result;
}
//如果左子树中没有找到就在右子树中找,无论找没找到都将结果返回
if(result == null && this.rightNode != null) {
result = this.rightNode.preOrderSearch(index);
}
return result;
}public static void main(String[] args) {
String str = "A(B(D(F,G(J))),C(E(H,I)))";
BinaryTree binaryTree = new BinaryTree();
binaryTree.createTreeByString(str);
binaryTree.preOrderSearch(9);
}
运行之:
![]()
二叉树节点的删除
现在想要完成的是:如果删除的是叶子节点那么就将该叶子节点删除。如果删除的是非叶子节点,那么就将以该节点为根的整个子树删除。
public void preOrderDelete(int index) {
if(index == 1) {
this.root = null;
return;
}
if(this.root != null) {
this.root.preOrderDelete(index);
}else {
System.out.println("当前二叉树为空");
}
}
public boolean preOrderDelete(int index) {
if(this.leftNode != null && (this.leftNode.value - 64) == index) {
this.leftNode = null;
return true;
}
if(this.rightNode != null && (this.rightNode.value - 64) == index) {
this.rightNode = null;
return true;
}
boolean flag = false;
if(this.leftNode != null) {
flag = this.leftNode.preOrderDelete(index);
}
//如果左子树没有删除掉而且存在右子树,就尝试在右子树中删除
if(!flag && this.rightNode != null) {
flag = this.rightNode.preOrderDelete(index);
}
return flag;
}测试(将D节点删除掉):
public static void main(String[] args) {
String str = "A(B(D(F,G(J))),C(E(H,I)))";
BinaryTree binaryTree = new BinaryTree();
binaryTree.createTreeByString(str);
System.out.println("先根序遍历结果:");
binaryTree.preOrder();
binaryTree.preOrderDelete(4);
System.out.println("\n删除元素之后先根序遍历结果:");
binaryTree.preOrder();
}运行之:

树的深度优先遍历和广度优先遍历
可以构建二叉树就可以构建树,不同的是树节点可以有两个以上的子节点。二叉树最多只能有两个。在原来BinaryTree基础上不变,只需要改变一下底层数据结构,再对处理方式细节稍作修改即可。修改如下:
class TreeNode{
char value;
List<TreeNode> children;
public TreeNode(char value) {
children = new LinkedList<TreeNode>();
this.value = value;
}
//添加子节点
public void add(TreeNode childNode) {
children.add(childNode);
}
//获取所有子节点
public List<TreeNode> getChildren(){
return this.children;
}
}其他细节修改:
- 在逗号状态下遇到字母,直接添加进子节点集合,二叉树处理中是判断了一下然后直接添加到右子节点上了。
- 在左括号状态下:遇到字母直接添加进子节点集合。
树的深度优先遍历分析(利用栈结构)

//深度优先遍历(利用栈结构的特性:后进先出)
public void depthFirst() {
Stack<TreeNode> tmpStack = new Stack<TreeNode>();
tmpStack.push(root);
//如果栈不为空,则栈顶元素出栈输出,并push进其所有子节点
while(!tmpStack.isEmpty()) {
TreeNode topNode = tmpStack.pop();
System.out.print(topNode.value + " ");
List<TreeNode> children = topNode.getChildren();
for(int index = children.size() - 1; index >= 0; index--) {
TreeNode childNode = children.get(index);
tmpStack.push(childNode);
}
}
}树的广度优先遍历(利用队列结构)
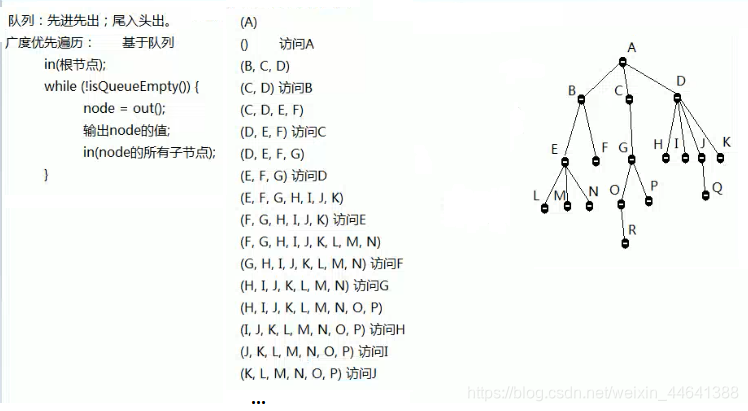
//广度优先遍历(利用队列结构的特性:先进先出)
public void breadthFirst() {
LinkedList<TreeNode> tmpQueue = new LinkedList<TreeNode>();
tmpQueue.add(this.root);
while(!tmpQueue.isEmpty()) {
TreeNode treeNode = tmpQueue.poll();
System.out.print(treeNode.value + " ");
List<TreeNode> children = treeNode.getChildren();
for (TreeNode node : children) {
tmpQueue.offer(node);
}
}
}构建此树测试:
public static void main(String[] args) {
String str = "A(B(E(L,M,N),F),C(G(O(R),P)),D(H,I,J(Q),K))";
Tree tree = new Tree();
tree.createTreeByString(str);
System.out.println("深度优先遍历:");
tree.depthFirst();
System.out.println("\n广度优先遍历:");
tree.breadthFirst();
}结果:

顺序结构存储完全二叉树
在一开始的时候分析到一个完全二叉树的性质,他一定是连续编号的,当然数组也是连续编号的,所以这二者之间就可以建立联系。如果有一颗完全二叉树的底层存储结构不是上面的树节点,改为数组。能不能完成三序遍历? 当然可以。可以通过计算的方式定位到每个节点。
按照上图的公式,来实现一把。
public class ArrayBinaryTree {
//使用数组存储完全二叉树的节点
private int[] arr;
public ArrayBinaryTree(int[] arr) {
this.arr = arr;
}
public void preOrder() {
preOrder(0);
}
//先根序遍历
private void preOrder(int index) {
if(arr == null || arr.length == 0) {
System.out.println("没有初始化树");
return;
}
if(index > arr.length - 1) {
return;
}
System.out.print(arr[index] + " ");
//递归遍历左子树
preOrder(2 * index + 1);
//递归遍历右子树
preOrder(2 * index + 2);
}
public void infixOrder() {
infixOrder(0);
}
//中根序遍历方法
public void infixOrder(int index) {
if(arr == null || arr.length == 0) {
System.out.println("没有初始化树");
return;
}
if(index > arr.length - 1) {
return;
}
infixOrder(2 * index + 1);
System.out.print(arr[index] + " ");
infixOrder(2 * index + 2);
}
}
测试:
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6,7,8};
ArrayBinaryTree abTree = new ArrayBinaryTree(arr);
System.out.println("先根序遍历结果:");
abTree.preOrder();
System.out.println("\n中根序遍历结果:");
abTree.infixOrder();
} 运行之:















 3791
3791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









