







文章目录
一、Docker安装ES和Kibana
首先拉取docker镜像,这里我用的是7.4.2版本。ES和Kibana的版本需要保持一致。在宿主机上创建ES数据卷挂载的目录config、data、plugings三个目录。config目录下创建elasticsearch.yml配置文件。配置文件中写入如下配置:
http.host: 0.0.0.0
注意冒号后需要一个空格,否则启动不成功。
部署启动ES容器,执行如下命令:
docker run --name "ES" -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v ~/Desktop/mydata/ES/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v ~/Desktop/mydata/ES/data:/usr/share/elasticsearch/data \
-v ~/Desktop/mydata/ES/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
部署启动Kibana
docker run --name "kibana" \
-e ELASTICSEARCH_HOSTS=http://172.17.0.2:9200 \
-p 5601:5601 \
-d kibana:7.4.2
需要注意的是链接ES的ip不要指定为自己宿主机的ip或者localhost之类的,否则Kibana可能连接不上ES,要将指定为es容器的ip。可用如下命令查看:
docker inspect 容器ID或容器名

二、基本概念
文档
ES中文档是指最顶层或者根对象, 这个根对象被序列化成JSON并存储到 Elasticsearch 中,指定了唯一 ID。文档中不仅包含我们存储的对象数据,他还包含了一些元数据,三个必须的元数据如下。
_index(索引)
这里的索引是名词,相同特性的文档应该被存在同一个索引下, 索引可以理解为众多索引的集合。比如,我们可能存储所有的订单信息到orders这个索引下。
_type(类型)
数据在索引中可能只是松散的组合在一起,但是通常明确定义一些数据中的子分区是很有用的。比如我们会把天猫的订单放在tmall类型下,京东订单放在jd类型下。
_id(ID)
id是一个字符串,当它和 _index 以及 _type 组合就可以唯一确定 Elasticsearch 中的一个文档。 当你创建一个新的文档,要么提供自己的 _id,要么让 Elasticsearch帮你生成。
三、保存或修改文档数据(POST/PUT)
保存或者说新增一个文档,一般称为索引一个文档,这里的文档做动词,就是保存的意思。我们利用Http的方式访问ES服务器,ES也提供了一些列RestAPI供我们完成增删改查操作。
如下,直接使用curl的方式索引一个文档:
curl -X POST http://localhost:9200/customer/external/1 \
-H "Content-Type:application/json" \
-d '{"name":"yyy"}'
索引文档可以发送POST或者PUT请求,/customer/external/1 即(/索引/类型/ID),这唯一定位了一个文档,即使现在我们没有创建customer索引和external类型,但是ES会自动帮我们创建,此时也没有ID为1的文档,ES也会帮我们创建。我们要保存的真正内容就是-d参数指定的JSON对象。发出请求得到ES响应如下:
{
"_index": "customer", //表示这个文档存储在customer索引下
"_type": "external", //在external类型下
"_id": "1", //文档id
"_version": 1, //文档版本号
"result": "created", //created表示新建,updated表示更新
"_shards": { //分片信息
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
如果现在将同样的请求再执行一次就是一个修改操作,而不是新增一个文档。因为此时/customer/external/1这个文档已经存在了。当然我们可以改变curl中的-d参数指定的文档内容达到修改当前文档内容的目的。
PUT和POST请求都可以用来索引或者修改文档,POST如果不指定id,则会自动生成,新增一个文档,如果带id则是修改操作;PUT更多地用作修改操作,必须指定id,如果不指定则会报错。
ES的修改其实并不是严格意义上的直接对旧文档进行更新,文档是不可变的,不可以被更新,只能被替换。它不像MySQL,可以直接修改一条记录中的某个字段值,ES内部会删除旧文档并索引一个新的文档。
除了用上述方法可以对文档进行修改操作之外,Elasticsearch还提供了 _update API的方式,它接受一个doc参数,将doc中指定的字段与旧文档的数据结合,有则覆盖,无则新增。如下:
POST /customer/external/1/_update
{
"doc":{
"name":"hhh",
"age":18
}
}
得到响应如下:
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 2,
"_seq_no" : 11,
"_primary_term" : 2,
"found" : true,
"_source" : {
"name" : "hhh",
"age" : 18
}
}
四、检索文档(GET)
1.检索一个文档
执行如下命令即可检索一个文档
GET /customer/external/1
返回文档信息如下:

如上除了一些元数据信息,"_source"字段即是我们想要得到的真实内容。
2.检索多个文档(mget)
Elasticsearch提供了mget API帮助我们一次检索多个文档,他接受一个docs数组作为参数,每个元素包含需要检索文档的元数据。 包括 _index 、 _type 和 _id。如果只想检索一个或者多个特定的字段,那么你可以通过 _source参数来指定这些字段的名字:
GET /_mget
{
"docs" : [
{
"_index" : "customer",
"_type" : "external",
"_id" : "3"
},
{
"_index" : "customer",
"_type" : "external",
"_id" : "2",
"_source": "name"
}
]
}
响应体也包含一个docs数组,每个元素对应请求中需要查询的元素,且顺序与请求中的顺序相同。
如果我们想要检索的每个文档都具有想同的索引和类型,那可以把相同的元数据抽取到URL上,只传一个 ids 数组,而不是整个 docs 数组,如下,表示检索customer/external下id为3和id为2的文档:
GET /customer/external/_mget
{
"ids" : [ "3", "2" ]
}
如果存在个别数据的索引或类型与其他大部分不同,那可以单独覆盖,如下:
GET /customer/external/_mget
{
"docs":[
{"_id":"3"},
{"_type":"internal","_id":"2", "_source":"name"}
]
}
即使有某个文档没有找到,上述请求的 HTTP 状态码仍然是 200 。事实上,即使请求 没有 找到任何文档,它的状态码依然是 200 --因为 mget 请求本身已经成功执行。 为了确定某个文档查找是成功或者失败,你需要检查 found 标记。
五、删除文档&索引(DELETE)
- 删除一个文档:DELETE /customer/external/1
- 删除整个索引:DELETE /customer
删除文档不会立即将文档从磁盘中删除,只是将文档标记为已删除状态。随着不断的索引更多的数据,Elasticsearch将会在后台清理标记为已删除的文档。
六、批量操作的API(bulk)
语法格式:
{action:{metadata}}
{requestBody}
action:表示要执行的动作
- index:创建或者替换一个现有的文档
- create:如果文档不存在则创建
- delete:删除文档
- update:更新文档
批量API必须发POST请求
POST /customer/external/_bulk
{"index":{"_id":"1"}} //索引一个id为1的文档
{"name":"yyy"} //想要保存的真实内容
{"index":{"_id":"2"}} //索引一个id为2的文档
{"name":"hhh"} //内容
{"index":{}} //索引一个文档,未指定id,会自动生成
{"name":"jjj"} //内容
响应如下:

took表示花费了501毫秒;
errors表示没有发生错误;
items中的每个item即为每个操作对应的结果;
当然还可以对每个action单独指定元数据
POST /_bulk
{"delete":{"_index":"customer","_type":"external","_id":"1"}} //删除文档
{"update":{"_index":"customer","_type":"external","_id":"2"}} //更新文档
{"doc":{"age":18}} //新内容
{"index":{"_index":"customer","_type":"external","_id":"3"}} //索引文档
{"name":"LLL"} //内容
{"create":{"_index":"customer","_type":"external","_id":"4"}} //索引文档
{"name":"ppp"} //内容
官方为我们提供了一些批量数据:https://gitee.com/runewbie/learning/raw/master/ElasticSearch/resource/accounts.json#
数据结构如下:
{
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "amberduke@pyrami.com",
"city" : "Brogan",
"state" : "IL"
}
导入这些数据可以方便后面的测试。
七、查询表达式(Query DSL)
Elasticsearch最厉害的应该就是它的查询和聚合特性了,ElasticSearch提供了search API用于执行查询操作。ElasticSearch执行查询有两种方式:
- 通过URL发送查询参数;
- 通过请求体发送JSON风格的查询参数,这些参数都将影响最终的查询结果。
相对于URL携带查询参数来说,请求体的方式更加灵活强大。请求体中携带的JSON风格的查询语言又被称为Query DSL(特定域查询语言)。将Query DSL视为AST(抽象语法树),它由以下两种类型的子句组成。
叶子查询子句
叶子查询子句在特定字段中查找特定值,例如match查询、term查询或rang查询,这些查询可以单独使用。
复合查询子句
复合查询子句包裹其他叶子查询或复合查询,并以逻辑方式组合多个查询(如bool查询或dis-max查询),或更改其行为(如常数查询)
查询子句的行为在查询上下文和过滤上下文中使用是不同的。
1.查询表达式的语法结构
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
像官方文档所说的那样,如果需要使用这种查询表达式,只需将查询语句传递给 query 参数即可,如下是几种查询方式。
2.查询所有(match_all)
GET /bank/_search
{
"query":{
"match_all":{}
}
}
match_all,即匹配所有。它的value是一个空对象,该子句会查询出所有文档。但是默认的只会返回10条文档。
如果现在我们想查询bank索引下的所有文档,只取5条结果,返回的文档需要按照age降序排列,而且只想看这些文档的firstname字段和lastname字段,那么查询参数应该是这样的:
GET /bank/_search
{
"query":{
"match_all":{}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"_source":["firstname","lastname"],
"size":5
}
ES响应hits的其中一个元素如下:
{
"_index" : "bank",
"_type" : "account",
"_id" : "291",
"_score" : null,
"_source" : {
"firstname" : "Lynn",
"lastname" : "Pollard"
},
"sort" : [40]
}
除了query参数,上面的查询参数还有如下几个:
sort参数
用于对查询出的文档集做排序,order参数指定排序方式为降序,支持两种asc(升序)和desc(降序)两种方式。
_source参数
用于控制每个命中文档的_source字段的返回方式。默认情况下将返回_source字段的内容,上述方式我们直接指定了命中文档的_source字段需要返回的字段(firstname和lastname)。 还可以禁用_source字段,那么命中的文档将不会返回其_source字段
"_source":false
还可以使用includes和excludes模式来控制需要返回的字段。如下,只会返回address和balance字段
"_source":{
"includes": ["address","balance"],
"excludes": ["firstname","lastname"]
}
“_source"参数还支持使用通配符,如下文档结果集”_source"中只会返回字段名以first开头的字段。
"_source":"first*"
size和from参数
指定了要返回的最大结果数量。我们指定为5,该响应就会返回5条文档。结合from参数可以对结果分页,我们没有指定from参数,它的默认值是0。需要注意的是:from+size的值不能超过index.max_result_window参数设置的值,后者的默认值为10000,增大此参数,会导致系统开销线性增大。
3.匹配查询(match)
match可以针对特定字段或一组字段进行匹配搜索。如果字段是基本类型(非字符串)则会精准匹配,如果是字符串则会全文检索,分词匹配。
如下,查询address字段中包含mill或者包含lane的所有文档
GET /bank/_search
{
"query": {
"match": {
"address":"mill lane"
}
}
}
match匹配出来的数据都会有一个得分,结果集会按照得分由高到低排列。得分越高则表示越匹配。
4.短语匹配(match_phrase)
match进行字符串全文检索,被检索的字段会被分词匹配,如果不希望被分词,则可以使用短语匹配。如下,检索bank索引下包含"mill lane"这条短语的所有文档。
GET /bank/_search
{
"query": {
"match_phrase": {
"address":"mill lane"
}
}
}
5.多字段匹配(multi_match)
如下,查询bank索引下,只要state或者address这两个字段其中一个包含"mill"或者"lane"都会被检索出来。multi_match也会做分词。
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill lane",
"fields": ["state","address"]
}
}
}
这就是多个字段去匹配query参数中的文本值,文本值会被分词。
6.布尔查询(bool)
布尔查询是指用布尔逻辑的方式把基本的查询组合成复杂的查询。
如下的查询操作组合了两个匹配查询,返回bank索引下gender字段包含"M"且address字段包含"mill"的所有文档。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"gender": "M"
}},{
"match": {
"address": "mill"
}
}
]
}
}
}
must即必须,也就是返回的文档必须满足must指定的匹配条件。
与must相反的是must_not,意思是必须不满足,如下,查询age字段不是38的所有文档。
GET /bank/_search
{
"query": {
"bool": {
"must_not": [
{"match": {
"age": 38
}}
]
}
}
}
还有should可以指定的查询列表,只要有其中任何一个为真,即被视为匹配,也就是满足其中一个条件即可。
如下,查询bank索引下,address字段包含mill或者age字段为38的所有文档。
GET /bank/_search
{
"query": {
"bool": {
"should": [
{"match": {
"address": "mill"
}},{
"match": {
"age": "38"
}
}
]
}
}
}
此外,bool这个复合查询子句还可以包裹过滤器filter,用于结果过滤匹配,返回过滤条件为真的所有文档。
如下,查询出年龄(age字段)在10-40岁之间的所有文档。
GET /bank/_search
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 40
}
}
}
}
}
}
bool查询中可以同时组合must、should、must_not和filter,此外,还可以在这些bool子句中嵌套bool查询,以模拟任何复杂的多级布尔逻辑。。这也是上面所说的复合查询子句的特点。
需要注意的是 must、should如果条件成立都会提高文档的得分,而must_not和filter不会。(must_not被当成了一个过滤器) 这就是前面所说的:查询子句的行为在查询上下文和过滤上下文中使用是不同的。
查询上下文
查询上下文中使用的查询子句需要解决的问题是“此文档与此查询子句的匹配程度如何?”,除了决定文档是否匹配外,查询子句还计算一个分数_source,表示文档相对于其他文档的匹配程度。
过滤上下文
在过滤上下文中,查询子句解决的问题是“此文档是否与此查询子句匹配”,答案是简单的是或者否,不计算分数。不计算文档相关性得分可有效提高搜索性能。过滤上下文主要用于过滤数据,例如:
- 这个时间戳timestamp是否在2015年到2016年范围内?
- 状态字段status是否设置为published?
为了提高性能,Elasticsearch会自动缓存常用的过滤器
7.精确匹配(term)
如下,查询age字段为28所有文档。
GET /bank/_search
{
"query": {
"term": {
"age": 28
}
}
}
上面age是数值,但是注意 如果使用term去精确匹配文本类型的值,可能一条也匹配不到。 因为ES在存储文本类型的值的时候存在分词的问题,如果使用term检索会非常困难。
比如下面两个term匹配:
GET /bank/_search
{
"query": {
"term": {
"address": "149 Surf Avenue"
}
}
}
GET /bank/_search
{
"query": {
"term": {
"firstname": "Kemp"
}
}
}
- 检索address字段值为"149 Surf Avenue"的文档,返回结果为0。
- 检索firstname为"Kemp"的文档,返回结果为0。
如果希望精确匹配文本类型的值,可以使用文本字段.keyword的方式(所有的文本都可以.keyword),意思是用来匹配文本字段的精确值,如下:
GET /bank/_search
{
"query": {
"match": {
"firstname.keyword": "Kemp"
}
}
}
GET /bank/_search
{
"query": {
"match": {
"address.keyword": "149 Surf Avenue"
}
}
}
注意,与短语匹配不同的是,短语匹配是如果字段中包含一条短语则被视为匹配,而keywrod表示,该文本字段值等于某个值才会被匹配。
八、聚合(aggregation)
聚合提供了对数据分组和提取统计信息的能力。聚合功能可以理解为大致等同于SQL中的Group By和SQL聚合函数的功能。在ElasticSearch中,可以执行返回命中文档的搜索,同时返回与搜索结果分离的聚合结果。从某种意义上说,这是非常强大和高效的,可以同时运行和查询多个聚合,并一次性获得两个(或多个)操作的结果,避免使用单一的API进行多次网络交互。
聚合有多种不同的类型,每种类型都有自己的目的和输出。通常将他们分为四大类:
- 存储桶聚合:这个相当于分组统计,每个桶即是每个组。
- 度量值聚合:在一组文档上跟踪和计算度量值(一个数字)的聚合。
- 矩阵聚合:对多个字段进行操作并根据从请求的文档字段中提取的值生成矩阵结果的聚合系列。
- 管道聚合:聚合其他聚合的输出及其相关度量值的聚合。
存储桶聚合可以具有子聚合(度量值聚合或者存储桶聚合),在其父聚合生成的桶内计算子聚合,嵌套聚合的级别深度没有硬限制。
如下只列举几种较常用的聚合方式。
1. 存储桶(bucket)聚合
1.1 Term聚合
Term聚合是一种多桶值聚合,其中桶是动态构建的,每个唯一值对应一个桶。这相当于分组,每个桶即为一个组。
如下,匹配address字段中包含"mill"的文档,并对结果集进行Term聚合。
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
}
, "aggs": {
"terms_age": {
"terms": {
"field": "age",
"size": 20
}
}
},
"size": 0
}
“terms_age”是自定义的聚合的名字。其中terms.field字段指定需要根据哪个字段分桶,terms.size字段表示生成的桶的数量,假如age有100种可能,那就会被分成100个组,此处只取出前20组并统计,当然也可以不指定terms.size,默认值为10。根对象的size设置为0表示不需要返回匹配的文档结果,此处只看聚合结果,如下:
"aggregations" : {
"terms_age" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
}
}
返回的结果“terms_age”对应我们的聚合结果:
- doc_count_error_upper_bound:表示超过上限计数,每个Term的错误文档的计数。
- sum_other_doc_count:表示超过指定size的所有bucket的文档计数总和。
- buckets就是桶的集合。可以看出结果集的年龄有4种,38的两个,28的一个,32的一个。
聚合可以同时指定多个。即一次网络交互,多个聚合。如下,可以增加对返回结果中的age字段求平均值:
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
}
, "aggs": {
"terms_age": {
"terms": {
"field": "age",
"size": 20
}
},
"avg_age":{
"avg": {
"field": "age"
}
}
},
"size": 0
}
返回聚合结果如下,平均年龄为34。
"aggregations" : {
"avg_age" : {
"value" : 34.0
},
"terms_age" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
}
}
桶聚合也可以进行嵌套子聚合。 如果此时还想得到各年龄人的平均薪资,那就需要在terms_age聚合的基础上再进行子聚合,如下:
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
}
, "aggs": {
"terms_age": {
"terms": {
"field": "age",
"size": 10
},
"aggs":{
"avg_balance":{
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
返回聚合结果如下:
"aggregations" : {
"terms_age" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : 38,
"doc_count" : 2,
"avg_balance" : {
"value" : 27806.5
}
},
{
"key" : 28,
"doc_count" : 1,
"avg_balance" : {
"value" : 19648.0
}
},
{
"key" : 32,
"doc_count" : 1,
"avg_balance" : {
"value" : 25571.0
}
}
]
}
}
可以看到每个桶中的avg_balance中的值表示平均薪资。
嵌套没有深度限制,如下,多层聚合嵌套,求地址包含mill的所有人中,不同年龄的男人和女人各自的平均薪资:
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"terms_age": {
"terms": {
"field": "age",
"size": 10
},
"aggs":{
"terms_gender":{
"terms": {
"field": "gender.keyword",
"size": 2
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
},
"size": 0
}
由于gender是文本类型的字段,所以需要使用 gender.keyword 进行分桶。 最外层的聚合terms_age是对不同年龄分桶,在此基础上在此进行子聚合将各年龄组的人按性别在次分成男和女两个桶,在性别桶内在次进行一次子聚合avg_balance,得到各性别的平均薪资。
在此基础上还可以看各年龄的人的平均薪资(不分男女),如下:
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
"terms_age": {
"terms": {
"field": "age",
"size": 10
},
"aggs":{
"terms_gender":{
"terms": {
"field": "gender.keyword",
"size": 2
},
"aggs": {
"avg_balance": {
"avg": {
"field": "balance"
}
}
}
},
"avg_balance":{
"avg": {
"field": "balance"
}
}
}
}
},
"size": 0
}
如上,在terms_gender聚合后添加一个同级聚合avg_balance,求出这个年龄的人的总体平均薪资。
1.2 区间聚合
区间聚合是一种基于source的多桶值聚合,允许用户定义一组范围,每个范围代表一个桶。在聚合过程中,将根据每个bucket范围,核查匹配的文档属于哪个桶。注意:此聚合包括from值,但不包括每个范围的to值,是左闭右开区间。
如下:对所有人按照薪资区间进行统计
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"rang_balance":{
"range": {
"field": "balance",
"ranges": [
{"from": 0,"to": 10000},
{"from": 10000,"to":20000},
{"from": 20000}
]
}
}
},
"size": 0
}
聚合结果如下:
"aggregations" : {
"rang_balance" : {
"buckets" : [
{
"key" : "0.0-10000.0",
"from" : 0.0,
"to" : 10000.0,
"doc_count" : 168
},
{
"key" : "10000.0-20000.0",
"from" : 10000.0,
"to" : 20000.0,
"doc_count" : 213
},
{
"key" : "20000.0-*",
"from" : 20000.0,
"doc_count" : 619
}
]
}
}
可以看到[0-10000)的有168人(左闭右开区间),[10000-20000)的有213人,20000+的有619人。
1.3 日期区间聚合
日期区间聚合专用于日期值的范围聚合。此聚合与正常范围聚合的主要区别在于,from值和to值可以用日期数学表达式表示,还可以指定返回from值和to值响应字段的日期格式。注意:此聚合包括from值,但不包括每个范围的to值,是左闭右开区间。
如下,对sold字段按照日期区间进行聚合,统计10个月之前以及最近10个月的文档数。
GET /cars/transactions/_search
{
"query": {"match_all": {}},
"aggs": {
"range":{
"date_range":{
"field":"sold",
"format":"yyyy-MM-dd HH:mm:ss",
"ranges":[
{"to":"now-10M/M"},
{"from":"now-10M/M"}
]
}
}
},
"size": 0
}
上面format参数指定响应结果的日期格式。 now-10M/M表示当前时间减去10个月并4舍五入到月初。当然如果写为now-10M即不会四舍五入,就是精确的一个月时间。
返回的聚合结果如下:
"aggregations" : {
"range" : {
"buckets" : [
{
"key" : "*-2021-02-01 00:00:00",
"to" : 1.6121376E12,
"to_as_string" : "2021-02-01 00:00:00",
"doc_count" : 8
},
{
"key" : "2021-02-01 00:00:00-*",
"from" : 1.6121376E12,
"from_as_string" : "2021-02-01 00:00:00",
"doc_count" : 0
}
]
}
}
可以看到所有结果集中最开始的时间到2月初共8条,2月初到现在是0条。
2. 度量值(metrics)聚合
度量值聚合系列中的聚合基于以某种方式从要聚合的文档中提取的值计算聚合值,这些值通常从文档的字段中提取,但也可以使用脚本生成。 数值聚合是一种特殊类型的metrics聚合,它输出是数值。一些聚合输出单个数字度量值(例如avg),称为单值数值度量聚合,其他聚合生成多个度量值(例如stats),称为多值数值度量聚合。当这些聚合用作某些存储桶聚合的直接子聚合时,单值和多值数字聚合的区别是需要注意的,某些存储桶聚合能够根据每个存储桶中的数值聚合只对返回的存储桶进行排序。
2.1 均值聚合(avg)
均值聚合(avg)是一种单值数值度量聚合,计算从聚合文档中提取的数值的平均值。这些值可以从文档中的特定数字字段中提取,也可以由提供的脚本生成。在上面Term聚合中已经嵌套使用过均值聚合。
2.2 计数聚合(cardinality)
计数聚合是一种计算不同值的近似计数的单值数值度量聚合。值可以从文档中的特定字段中提取,也可以由脚本生成。
如下,统计一下/cars/transactions下的所有文档中有几种颜色
GET /cars/transactions/_search
{
"aggs":{
"color_count":{
"cardinality":{
"field" : "color.keyword"
}
}
},
"size":0
}
聚合结果如下:
"aggregations" : {
"color_count" : {
"value" : 3
}
}
cardinality聚合基于HyperLog++算法,该算法基于散列进行计数,该算法有如下特性:
- 可以进行精度配置,这决定了如何用内存换取精度。(更精确 = 更多内存)
- 在少量数集上具有出色的精度。
- 固定内存使用:无论是否有数百或数十亿个唯一值,内存使用都仅取决于配置的精度。
配置精度(precision_threshold)如下:
GET /cars/transactions/_search
{
"aggs":{
"color_count":{
"cardinality":{
"field" : "color.keyword",
"precision_threshold":100
}
}
},
"size":0
}
precision_threshold选项允许以内存开销交换准确性,并定义唯一的计数,低于该计数的计数是接近准确值的;超过这个值,就会开始节省内存而牺牲准确度,计数可能会变得更不准确。支持的最大值为40000,高于此值的阈值将与近40000的阈值具有相同的效果。默认值为3000。
对于指定的阈值,HLL 的数据结构会大概使用 precision_threshold * 8 字节的内存,所以就必须在牺牲内存和获得额外的准确度间做平衡。在实际应用中, 100 的阈值可以在唯一值为百万的情况下仍然将误差维持 5% 以内。
九、索引API
索引API是用于管理单个索引、索引设置、别名、映射和索引模板等功能的接口。
1.创建索引API
创建索引API用于在Elasticsearch中手动创建索引(之前我们没有直接手动创建索引,而是直接存储文档,Elasticsearch会帮我们自动创建索引)。现在我们知道Elasticsearch中的所有文档都存储在某一个索引中,所以手动创建索引并指定一些规则是必要的。
创建索引时的索引名称有如下规则:
- 仅小写字母(这个需要特别注意)
- 不能包括\、/.|#等字符
- 7.0版之前的索引可能包含冒号,但已弃用,7.0版本中不支持
- 不能长于255子节
- 等
PUT my_index
如上,我们创建了名为my_index的索引,其搜索设置都采用默认值。
2.索引设置
创建的每个索引都可以具有与之关联的特定设置。我们可以自己在请求体中定义,如下:
PUT my_index
{
"settings": {
"number_of_shards":3, //定义分片数量,默认值是1
"number_of_replicas":2 //定义副本数量,默认值是1(即每个主分片都有一个副本)
}
}
3. 映射(mapping)
映射的功能是完成字段的定义,包括数据类型、存储属性、分析器等。之前我们没有手动创建映射,在我们存储文档的时候,Elasticsearch会自动帮我们推断映射类型,当然有时候自动推断的类型映射不是我们想要的,所以自己手动指定字段映射是很有必要的。如下,使用mappings参数创建映射。
PUT my_index
{
"mappings": {
"properties": {
"title":{"type":"text"},
"name":{"type":"text"},
"age":{"type":"integer"},
"gender":{"type":"keyword"},
"created_time":{
"type":"date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
如上我们创建了一个索引并创建了各字段数据类型的映射:
- title、name为文本类型
- age为整数值
- gender是关键字(keyword)
- created_time是日期类型date,并且指定了两种可能的日期格式。
Elasticsearch支持如下数据类型:
- 数字类型:支持常用的类型,long、integer、short、byte、double、float、half_float(半精度浮点型)、scaled_float(可变浮点型)
- 布尔类型:布尔字段接受JSON格式的true和false,但也可以接受解释为真或假的字符串"true"和"false"
- 数组类型:Elasticsearch中没有专用的数组类型,默认情况下,任何字段都可以包含零个或多个值(每个字段都可以是多个值),但是数组中的所有值都必须具有相同的数据类型。
- 日期类型:JSON格式规范中没有对日期数据类型进行定义,因此Elasticsearch中的日期可以是:
- 包含格式化日期的字符串,例如2015-01-01或2015/01/01 00:00:00等
- 一个表示毫秒的长整型数字
在Elasticsearch中,日期将始终呈现为字符串,即使他们最初在JSON文档中作为长整型提供。
- 关键字:关键字(keyword)这种类型的特点是不再分词,直接作为一个Term,检索时也只能用精确值检索。
- 文本类型(text):这种类型会进行解析、分词,索引的是解析后的Term,检索时根据Term就可以检索到,一般适合用于长文本的全文检索。
- 地理位置类型:地理位置(geo)是用于存储经纬度的字段类型。
新增字段映射
上面是直接在创建索引的时候创建了字段映射,那么假如现在索引已经存在,该如何去为该索引新增一个字段映射呢?可以使用mappingAPI,如下:
PUT my_index/_mapping
{
"properties": {
"desc":{"type":"text"}
}
}
查看映射
GET my_index/_mapping

映射属性设置
映射属性(参数)决定了字段(Field)的存储、索引、搜索、分析等方面的功能和特征,主要的映射属性值有一下几种。
- index属性:index选项控制是否对字段值进行索引。它接受true和false,默认为true。若某个字段的index属性被指定为false,则其不能被搜索、排序、聚合等。
如下:
PUT my_index2
{
"mappings": {
"properties": {
"title":{
"type":"text",
"index": true
}
}
}
}
- store属性:该属性默认为false。如果将该属性指定为true,那么Elasticsearch将会对该字段单独存储倒排索引。我们平常检索的时候Elasticsearch都会将我们存储的所有数据放在_source字段中返回给我们,我们可以直接从_source中直接提取字段值,这很方便,那么既然这样为什么还需要这个store属性?
在某些情况下,单独存储某个字段是有意义的,比如下面的示例,一个具有title、date和非常大的content的文档。那我们可能只是想检索title和date字段,而不必从大型源字段_source中提取这两个字段的值,这会更加高效,因为大型源_source字段中会包含title、date和非常大的content值。
PUT my_index3
{
"mappings": {
"properties": {
"title":{
"type":"text",
"store": true
},
"date":{
"type":"date",
"format": ["yyyy-MM-dd HH:mm:ss"],
"store": true
},
"content":{
"type":"text"
}
}
}
}
POST my_index3/_doc/1
{
"title":"文章标题",
"date":"2021-12-19 20:00:00",
"content":"这是文章内容。。。。很长。。。"
}
GET my_index3/_search
{
"query": {
"match": {
"title": "文章标题"
}
},
"stored_fields": ["title","date"]
}

可以看到Elasticsearch并没有响应源_source字段。
3.判断索引是否存在
HEAD my_index
4.高版本去除类型type的概念
Elasticsearch是基于Lucene开发的搜索引擎,ES中不同type下名称相同的filed最终在Lucene中的处理方式是相同的。你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。去掉type是为了提高ES处理数据的效率。所以在索引文档的时候就不要再指定类型了。
十、RestHighLevelClient操作ES
Elasticsearch官方提供了RestClient供我们用Java去操作ES,Rest client 分成两部分:
- Java Low Level REST Client: 低级别ES客户端,使用http协议与Elastiicsearch集群通信,与所有ES版本兼容。
- Java High level REST Client: 高级别ES客户端,它是基于低级别的客户端,提供了更加简易,方便我们操作ES的API。
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
1.初始化Client
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
return client;
}
官方文档中介绍了多种API的使用,非常详细,与我们在Kibana中写DSL一样,这里只是使用API的形式构建DSL语句。如下,以index API和search API为例操作ES。
2.index API(索引API)
IndexRequest可用于索引文档,写入数据的方式较多,它可以接受一个Map参数,将Map自动转为JSON格式的对象作为文档的数据内容,也可以直接写入JSON格式字符串等。如下,直接写入JSON格式的字符串:
public void indexApiTest() throws IOException {
//指定索引名称users
IndexRequest indexRequest = new IndexRequest("users");
//设置id,如不设置则会自动生成一个唯一ID
indexRequest.id("1");
//需要索引的数据
User user = new User("yyy","男",24);
//写入JSON格式的数据内容
indexRequest.source(JSON.toJSONString(user), XContentType.JSON);
//发送索引文档的请求(同步请求),并得到响应
IndexResponse indexResponse = client.index(indexRequest,RequestOptions.DEFAULT);
}
RestHighLevelClient 中的所有API都接受一个 RequestOptions,RequestOptions类保存了应该在同一个应用程序中的许多请求之间共享的请求的部分。你可以创建一个单例实例,并在所有请求之间共享它。
RestHighLevelClient中的API支持同步调用和异步调用两种方式:
- 同步调用即方法会阻塞知道请求成功或抛出异常。
- 异步调用会立刻从方法中返回,但是需要有一个listener参数作为回调。
client.indexAsync(indexRequest, RequestOptions.DEFAULT, new ActionListener<IndexResponse>() {
@Override
public void onResponse(IndexResponse indexResponse) {
//索引成功则通过回调得到indexResponse
}
@Override
public void onFailure(Exception e) {
//索引失败则告知异常
}
});
索引文档成功之后,会得到一个IndexResponse响应对象,通过它可以获取到请求执行后的信息,比如索引成功数、失败数,失败原因,以及当前是created还是updated操作等。官方文档有比较详细的Demo。
3. Search API
SearchRequest可以用作检索文档、聚合等操作。
3.1 检索
public void searchApiTest() throws IOException {
//创建检索请求
SearchRequest searchRequest = new SearchRequest();
//指定索引
searchRequest.indices("bank");
//指定DSL语句,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//按照address字段做匹配查询
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill lane"));
searchSourceBuilder.from(0);
searchSourceBuilder.size(10);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);
System.out.println("检索条件:" + searchSourceBuilder);
System.out.println("检索结果:" + response);
}
query方法接受一个QueryBuilder参数,QueryBuilders是构建DSL语句的工具类,可以帮我们创建各种QueryBuilder,支持匹配查询(match)、短语匹配(match_phrase)、多字段匹配(multi_match)、布尔查询等。每种查询对应一个QueryBuilder。
上面matchQuery表示匹配查询,打印生成的检索条件如下(去除一些多余的信息):
{
"from": 0,
"size": 10,
"query": {
"match": {
"address": {
"query": "mill lane"
}
}
}
}
得到响应如下:
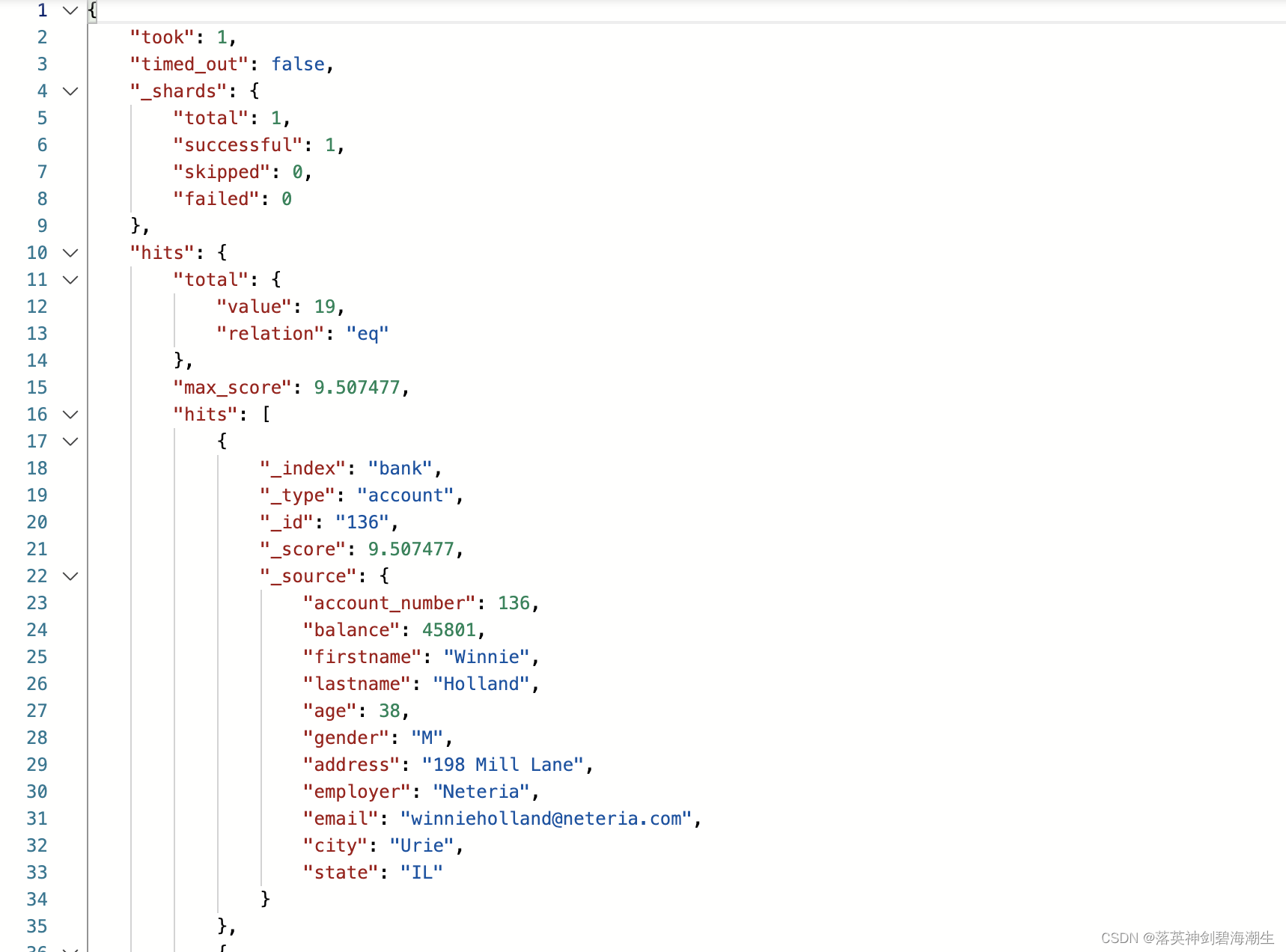
获取检索结果:
SearchHits outerHits = searchResponse.getHits();
SearchHit[] innerHits = outerHits.getHits();
Stream.of(innerHits).forEach(item -> System.out.println(item)); //1
Stream.of(innerHits).forEach(item -> System.out.println(item.getSourceAsString())); //2
1处可以获取每个hits元素的信息,比如:
{
"_index" : "bank",
"_type" : "account",
"_id" : "449",
"_score" : 4.1042743,
"_source" : {
"account_number" : 449,
"balance" : 41950,
"firstname" : "Barnett",
"lastname" : "Cantrell",
"age" : 39,
"gender" : "F",
"address" : "945 Bedell Lane",
"employer" : "Zentility",
"email" : "barnettcantrell@zentility.com",
"city" : "Swartzville",
"state" : "ND"
}
}
2处获取的是每个hits元素中的_source的内容,如下:
{"account_number":136,"balance":45801,"firstname":"Winnie","lastname":"Holland","age":38,"gender":"M","address":"198 Mill Lane","employer":"Neteria","email":"winnieholland@neteria.com","city":"Urie","state":"IL"}
3.2 聚合
public void searchAggApiTest() throws IOException {
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices("bank");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//按照年龄做term聚合
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("ageAgg").field("age").size(10);
//可嵌套聚合
//termsAggregationBuilder.subAggregation()
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("balanceAgg").field("balance");
searchSourceBuilder.aggregation(termsAggregationBuilder);
searchSourceBuilder.aggregation(avgAggregationBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);
}
这里age字段是long类型的,如果为text类型,则需要写成age.keyword,这与之前在kibana中的操作一样。
生成的聚合请求打印如下:
{
"aggregations": {
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
"balanceAgg": {
"avg": {
"field": "balance"
}
}
}
}
聚合响应打印如下,可以看到与在kibana中得到的结果也是一样的:
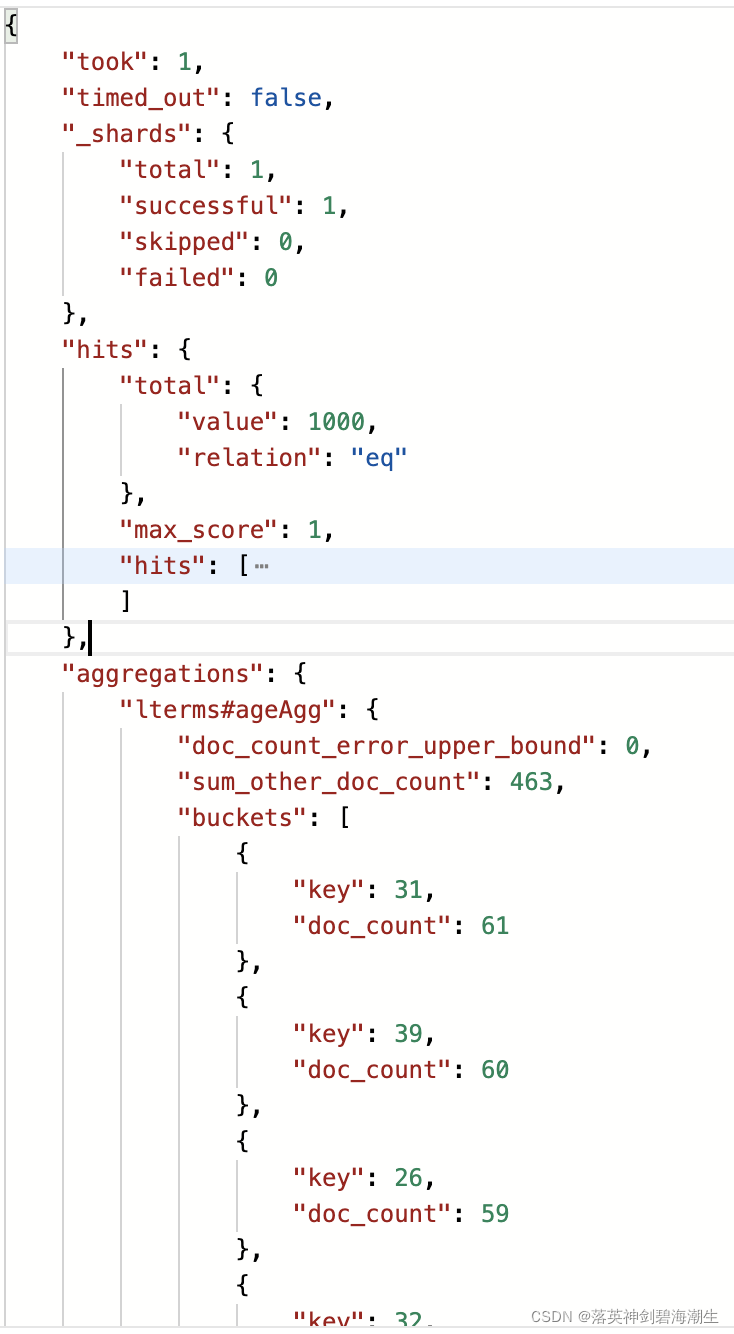
获取聚合信息:
Aggregations aggregations = response.getAggregations();
Terms ageTerm = aggregations.get("ageAgg");
for (Terms.Bucket bucket : ageTerm.getBuckets()) {
System.out.println(bucket.getKeyAsString() + "\t---" + bucket.getDocCount());
}
Avg avg = aggregations.get("balanceAgg");
System.out.println("平均薪资:" + avg.getValueAsString());
Aggregations中维护了Map<String, Aggregation>,Aggregation是一个接口,Terms和Avg都是其实现类,框架对于每种聚合都提供了一个Aggregation的实现类。














 1451
1451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









