







Math of GCN
一、warmup
1.Graph vs Image
①Graph是相比于Image更加广义的一种拓扑结构。
②Image是Grape在欧式空间的一种特例。
2.符号含义
①A:图的邻接矩阵
②
A
^
\hat{A}
A^ :
A
^
=
A
+
I
\hat{A}=A+I
A^=A+I,
I
I
I为单位矩阵
③D:节点的度矩阵
④
D
^
\hat{D}
D^ :
D
^
=
D
+
I
\hat{D}=D+I
D^=D+I,
I
I
I为单位矩阵
二、Basic of GCN
1.什么是GNN
GNN的公式表达:
H
(
l
+
1
)
=
f
(
A
,
H
l
)
H^{(l+1)} =f(A,H^{l})
H(l+1)=f(A,Hl)
公式理解:给定图的邻接矩阵A和每个节点的特征
H
l
H^{l}
Hl作为输入,经过函数f()的映射后,从而得到每个节点输出
H
(
l
+
1
)
H^{(l+1)}
H(l+1),作为下一层的输入特征。不同的函数f()会产生不同的图神经网络架构。本文探究的是GCN模型。
2.GCN(本文的研究对象是无向简单图)
GCN的公式表达:
H
(
l
+
1
)
=
σ
(
D
^
−
1
2
A
^
D
^
−
1
2
H
(
l
)
θ
)
H^{(l+1)} =\sigma (\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}\theta)
H(l+1)=σ(D^−21A^D^−21H(l)θ)
公式理解:
A
^
\hat{A}
A^ :
A
^
=
A
+
I
\hat{A}=A+I
A^=A+I,
I
I
I为单位矩阵,
D
^
−
1
2
\hat{D}^{-\frac{1}{2}}
D^−21代表对矩阵幂运算,因为
D
^
−
1
2
\hat{D}^{-\frac{1}{2}}
D^−21只有主对角线有非零实数,所以只需对主对角线上的元素进行(-1/2)次的幂运算进行,
H
l
H^{l}
Hl为每个结点的特征,
θ
\theta
θ为可训练参数,对输入的特征进行线性变换,
σ
\sigma
σ为非线性激活函数。
现在,我们可以简单来理解一下GCN在做什么,其实就是对图的邻接矩阵A首先加了一个自环得到
A
^
\hat{A}
A^,然后左右分别乘了
D
^
−
1
2
\hat{D}^{-\frac{1}{2}}
D^−21,做了一个对称归一化,接着使用得到的矩阵
D
^
−
1
2
A
^
D
^
−
1
2
\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}
D^−21A^D^−21去对节点输入特征
H
(
l
)
H^{(l)}
H(l)进行聚合,每个节点都聚合到了自身的信息和相邻结点的特征信息。
三、Spectral Graph Theory
1.linear algebra recap
①eigenvalue and eigenvector
【定义】:A为n阶矩阵,若数λ和n维非0列向量x满足Ax=λx,那么数λ称为A的特征值,x称为A的对应于特征值λ的特征向量。
②实对称矩阵
【定义】:如果有n阶矩阵A,其矩阵的元素都为实数,且矩阵A的转置等于其本身
(
a
i
j
=
a
j
i
)
(a_{ij}=a_{ji})
(aij=aji),则称A为实对称矩阵。
【性质】:实对称矩阵的属于不同特征值的特征向量相互正交。
【实对称矩阵的相似对角化】:实对称矩阵必定相似于一个对角矩阵(对角线以外的元素全为0的矩阵),即存在可逆矩阵P,使得
P
−
1
A
P
=
Λ
P^{-1} AP=\Lambda
P−1AP=Λ,且存在正交矩阵U,使得
U
−
1
A
U
=
U
T
A
U
=
Λ
U^{-1} AU=U^{T} AU=\Lambda
U−1AU=UTAU=Λ。
【实对称矩阵的相似对角化理解】:
U
T
A
U
=
Λ
U^{T} AU=\Lambda
UTAU=Λ,可以改写为
A
=
U
Λ
U
T
A=U\Lambda U^{T}
A=UΛUT,其中
U
U
T
=
I
(
I
为单位矩阵
)
UU^{T}=I(I为单位矩阵)
UUT=I(I为单位矩阵),
Λ
=
[
λ
1
λ
2
.
.
.
.
.
.
λ
n
]
\Lambda = \begin{bmatrix} \lambda_{1} & & & & \\ & \lambda_{2} & & & \\ & & ... & & \\ & & & ... &\\ & & & & \lambda_{n} \end{bmatrix}
Λ=⎣
⎡λ1λ2......λn⎦
⎤
③positive semi-definite matrix
【定义】:设A是实对称矩阵。如果对任意的实非零列向量x有
X
T
A
X
≥
0
X^{T}AX≥0
XTAX≥0,就称A为半正定矩阵。
【性质】:A的特征值均为非负的,即对于任意特征值
λ
i
\lambda _{i}
λi,都有
λ
i
≥
0
\lambda _{i}≥0
λi≥0。
④quadratic form
【定义】:二次型:
R
n
R^n
Rn上的一个二次型是一个定义在
R
n
R^n
Rn 上的函数,表达式为
Q
(
x
)
=
x
T
A
x
Q(x)=x^TAx
Q(x)=xTAx ,其中A是一个n×n对称矩阵(一定要注意A是对称矩阵,不是一个随便的矩阵),矩阵A称为关于二次型的矩阵(二次型矩阵),
x
T
A
x
x^TAx
xTAx可以称为向量x关于矩阵A的二次型。
【瑞利商】:即一个向量关于矩阵A的二次型与该向量关于单位矩阵的二次型的比值,数学表达式为:
R
(
A
,
x
)
=
x
⃗
T
A
x
⃗
x
⃗
T
x
⃗
R(A,x)=\frac{\vec{x}^TA\vec{x} }{\vec{x}^T\vec{x}}
R(A,x)=xTxxTAx。
【研究二次型和瑞利商的意义】:二次型和瑞利商与矩阵的特征值有着密切的联系。当瑞利商
R
(
A
,
x
)
=
x
⃗
T
A
x
⃗
x
⃗
T
x
⃗
R(A,x)=\frac{\vec{x}^TA\vec{x} }{\vec{x}^T\vec{x}}
R(A,x)=xTxxTAx中的
x
⃗
\vec{x}
x为矩阵的的特征向量时,有
R
(
A
,
x
)
=
x
⃗
T
A
x
⃗
x
⃗
T
x
⃗
=
x
⃗
T
(
λ
x
⃗
)
x
⃗
T
x
⃗
=
λ
(
x
⃗
T
x
⃗
)
x
⃗
T
x
⃗
=
λ
R(A,x)=\frac{\vec{x}^TA\vec{x} }{\vec{x}^T\vec{x}}=\frac{\vec{x}^T(\lambda \vec{x}) }{\vec{x}^T\vec{x}}=\frac{\lambda (\vec{x}^T\vec{x}) }{\vec{x}^T\vec{x}}=\lambda
R(A,x)=xTxxTAx=xTxxT(λx)=xTxλ(xTx)=λ。因此瑞利商是研究特征值的一个重要手段。
2.properties of matrices related to A
(1)拉普拉斯矩阵和拉普拉斯矩阵对称规范化
①拉普拉斯矩阵(用
L
L
L表示):
L
=
D
−
A
L=D−A
L=D−A,A是邻接矩阵,D是度矩阵。
②拉普拉斯矩阵对称规范化(用
L
s
y
m
表示
L_{sym}表示
Lsym表示):
L
s
y
m
=
D
−
1
2
L
D
−
1
2
L_{sym}={D}^{-\frac{1}{2}}L{D}^{-\frac{1}{2}}
Lsym=D−21LD−21。
【研究L和
L
s
y
m
L_{sym}
Lsym的意义】:
Ⅰ:
L
L
L和
L
s
y
m
L_{sym}
Lsym都为实对称矩阵,因此他们都有n个特征值和n个正交的特征向量,可以分解为
U
Λ
U
T
U\Lambda U^{T}
UΛUT的形式。
Ⅱ:
L
L
L和
L
s
y
m
L_{sym}
Lsym都为半正定矩阵,因此他们的特征值都大于等于0。
3.证明 L L L和 L s y m L_{sym} Lsym都为半正定矩阵
证明思路:证明瑞利商≥0 对于任意
x
⃗
{\vec{x}}
x都成立,则当
x
⃗
{\vec{x}}
x为特征向量时,仍有瑞利商≥0,此时的瑞利商等于特征值,可以证得特征值≥0。
【证明L为半正定矩阵】:
R
(
A
,
x
)
=
x
⃗
T
A
x
⃗
x
⃗
T
x
⃗
R(A,x)=\frac{\vec{x}^TA\vec{x} }{\vec{x}^T\vec{x}}
R(A,x)=xTxxTAx,其中
x
⃗
T
x
⃗
{\vec{x}^T\vec{x}}
xTx>0 恒成立,故只需证明
x
⃗
T
A
x
⃗
{\vec{x}^TA\vec{x} }
xTAx≥0即可。
构造辅助矩阵:
G
i
,
j
=
[
1
−
1
.
.
.
−
1
1
]
G_{i,j}=\begin{bmatrix} & & & & & & \\ & & & & & & \\ & & 1 & -1 & \\ & & & ... & & \\ & & -1 & 1 &\\ & & & & & & \end{bmatrix}
Gi,j=⎣
⎡1−1−1...1⎦
⎤,辅助矩阵
G
i
,
j
G_{i,j}
Gi,j的意思是在矩阵的第i行i列取值为1,矩阵的第j行j列取值为1,矩阵的第i行j列取值为-1,矩阵的第j行i列取值为-1,其余位置取值为0。如此一来,L可以重写为
L
=
D
−
A
=
∑
(
i
,
j
)
∈
E
G
(
i
,
j
)
L=D-A=\sum_{(i,j)∈E}G_{(i,j)}
L=D−A=∑(i,j)∈EG(i,j) , 【
G
(
i
,
j
)
G_{(i,j)}
G(i,j)可以理解为L=D+(-A)得到的】,对于任意
x
⃗
\vec{x}
x,有
x
⃗
T
G
(
i
,
j
)
x
⃗
=
x
⃗
T
[
.
.
.
.
.
.
x
i
−
x
j
.
.
.
x
j
−
x
i
.
.
.
]
=
x
i
(
x
i
−
x
j
)
+
x
j
(
x
j
−
x
i
)
=
(
x
i
−
x
j
)
2
\vec{x} ^TG_{(i,j)}\vec{x}=\vec{x} ^T\begin{bmatrix} ...\\ ...\\ x_i-x_j\\ ...\\ x_j-x_i\\ ...\\ \end{bmatrix}=x_i(x_i-x_j)+x_j(x_j-x_i)=(x_i-x_j)^2
xTG(i,j)x=xT⎣
⎡......xi−xj...xj−xi...⎦
⎤=xi(xi−xj)+xj(xj−xi)=(xi−xj)2,则有
x
⃗
T
L
x
⃗
=
x
⃗
T
(
∑
(
i
,
j
)
∈
E
G
(
i
,
j
)
)
x
⃗
=
(
∑
(
i
,
j
)
∈
E
x
⃗
T
G
(
i
,
j
)
x
⃗
)
=
∑
(
i
,
j
)
∈
E
(
x
i
−
x
j
)
2
\vec{x} ^TL\vec{x}=\vec{x}^T(\sum_{(i,j)∈E}^{ }G_{(i,j)})\vec{x}=(\sum_{(i,j)∈E}^{ }\vec{x}^TG_{(i,j)}\vec{x})=\sum_{(i,j)∈E}^{ }(x_i-x_j)^2
xTLx=xT(∑(i,j)∈EG(i,j))x=(∑(i,j)∈ExTG(i,j)x)=∑(i,j)∈E(xi−xj)2,因此
x
⃗
T
L
x
⃗
≥
0
\vec{x} ^TL\vec{x}≥0
xTLx≥0恒成立,所以瑞利商R(A,x)≥0恒成立,故
L
L
L为半正定矩阵。
【证明L_sym为半正定矩阵】:
x
⃗
T
L
s
y
m
x
⃗
=
(
x
⃗
T
D
−
1
2
)
L
(
D
−
1
2
x
⃗
)
=
∑
(
i
,
j
)
∈
E
(
x
i
d
i
−
x
j
d
j
)
2
\vec{x}^TL_{sym}\vec{x}=(\vec{x}^TD^{-\frac{1}{2}})L(D^{-\frac{1}{2}}\vec{x})=\sum_{(i,j)∈E}(\frac{x_i}{\sqrt{d_i}}-\frac{x_j}{\sqrt{d_j}})^2
xTLsymx=(xTD−21)L(D−21x)=∑(i,j)∈E(dixi−djxj)2,因此
x
⃗
T
L
s
y
m
x
⃗
≥
0
\vec{x}^TL_{sym}\vec{x}≥0
xTLsymx≥0恒成立,所以瑞利商R(A,x)≥0恒成立,故
L
s
y
m
L_{sym}
Lsym为半正定矩阵。
4. L s y m L_{sym} Lsym的特征值取值范围
定义正数形式的辅助矩阵:
G
i
,
j
p
o
s
=
[
1
1
.
.
.
1
1
]
G^{pos}_{i,j}=\begin{bmatrix} & & & & & & \\ & & & & & & \\ & & 1 & 1 & \\ & & & ... & & \\ & & 1 & 1 &\\ & & & & & & \end{bmatrix}
Gi,jpos=⎣
⎡111...1⎦
⎤,辅助矩阵
G
i
,
j
G_{i,j}
Gi,j的意思是在矩阵的第i行i列取值为1,矩阵的第j行j列取值为1,矩阵的第i行j列取值为1,矩阵的第j行i列取值为1,其余位置取值为0。
则
x
⃗
T
G
(
i
,
j
)
p
o
s
x
⃗
=
(
x
i
+
x
j
)
2
\vec{x} ^TG^{pos}_{(i,j)}\vec{x}=(x_i+x_j)^2
xTG(i,j)posx=(xi+xj)2,
令
L
p
o
s
=
D
+
A
L^{pos}=D+A
Lpos=D+A,则
L
p
o
s
=
∑
(
i
,
j
)
∈
E
G
(
i
,
j
)
p
o
s
L^{pos}=\sum_{(i,j)∈E}G^{pos}_{(i,j)}
Lpos=∑(i,j)∈EG(i,j)pos,
x
⃗
T
L
p
o
s
x
⃗
=
x
⃗
T
(
∑
(
i
,
j
)
∈
E
G
(
i
,
j
)
)
x
⃗
=
(
∑
(
i
,
j
)
∈
E
x
⃗
T
G
(
i
,
j
)
p
o
s
x
⃗
)
=
∑
(
i
,
j
)
∈
E
(
x
i
+
x
j
)
2
≥
0
\vec{x} ^TL^{pos}\vec{x}=\vec{x}^T(\sum_{(i,j)∈E}^{ }G_{(i,j)})\vec{x}=(\sum_{(i,j)∈E}^{ }\vec{x}^TG^{pos}_{(i,j)}\vec{x})=\sum_{(i,j)∈E}^{ }(x_i+x_j)^2≥0
xTLposx=xT(∑(i,j)∈EG(i,j))x=(∑(i,j)∈ExTG(i,j)posx)=∑(i,j)∈E(xi+xj)2≥0,
L
s
y
m
p
o
s
=
D
−
1
2
L
p
o
s
D
−
1
2
L^{pos}_{sym}={D}^{-\frac{1}{2}}L^{pos}{D}^{-\frac{1}{2}}
Lsympos=D−21LposD−21,
x
⃗
T
L
s
y
m
p
o
s
x
⃗
=
∑
(
i
,
j
)
∈
E
(
x
i
d
i
+
x
j
d
j
)
2
≥
0
\vec{x} ^TL^{pos}_{sym}\vec{x}=\sum_{(i,j)∈E}(\frac{x_i}{\sqrt{d_i}}+\frac{x_j}{\sqrt{d_j}})^2≥0
xTLsymposx=∑(i,j)∈E(dixi+djxj)2≥0,
将
L
p
o
s
=
D
+
A
L^{pos}=D+A
Lpos=D+A代入
L
s
y
m
p
o
s
=
D
−
1
2
L
p
o
s
D
−
1
2
L^{pos}_{sym}={D}^{-\frac{1}{2}}L^{pos}{D}^{-\frac{1}{2}}
Lsympos=D−21LposD−21,,有
L
s
y
m
p
o
s
=
D
−
1
2
L
p
o
s
D
−
1
2
=
I
+
D
−
1
2
A
D
−
1
2
L^{pos}_{sym}={D}^{-\frac{1}{2}}L^{pos}{D}^{-\frac{1}{2}}=I+{D}^{-\frac{1}{2}}A{D}^{-\frac{1}{2}}
Lsympos=D−21LposD−21=I+D−21AD−21,
有
x
⃗
T
L
s
y
m
p
o
s
x
⃗
=
x
⃗
T
(
I
+
D
−
1
2
A
D
−
1
2
)
x
⃗
≥
0
\vec{x} ^TL^{pos}_{sym}\vec{x}=\vec{x} ^T(I+{D}^{-\frac{1}{2}}A{D}^{-\frac{1}{2}})\vec{x}≥0
xTLsymposx=xT(I+D−21AD−21)x≥0,
x
⃗
T
x
⃗
+
x
⃗
T
D
−
1
2
A
D
−
1
2
x
⃗
≥
0
\vec{x} ^T\vec{x}+\vec{x} ^T{D}^{-\frac{1}{2}}A{D}^{-\frac{1}{2}}\vec{x}≥0
xTx+xTD−21AD−21x≥0,
x
⃗
T
x
⃗
≥
−
x
⃗
T
D
−
1
2
A
D
−
1
2
x
⃗
\vec{x} ^T\vec{x}≥-\vec{x} ^T{D}^{-\frac{1}{2}}A{D}^{-\frac{1}{2}}\vec{x}
xTx≥−xTD−21AD−21x,
2
x
⃗
T
x
⃗
≥
x
⃗
T
x
⃗
−
x
⃗
T
D
−
1
2
A
D
−
1
2
x
⃗
2\vec{x} ^T\vec{x}≥\vec{x} ^T\vec{x}-\vec{x} ^T{D}^{-\frac{1}{2}}A{D}^{-\frac{1}{2}}\vec{x}
2xTx≥xTx−xTD−21AD−21x,
2
x
⃗
T
x
⃗
≥
x
⃗
T
(
I
−
D
−
1
2
A
D
−
1
2
)
x
⃗
2\vec{x} ^T\vec{x}≥\vec{x} ^T(I-D^{-\frac{1}{2}}A{D}^{-\frac{1}{2}})\vec{x}
2xTx≥xT(I−D−21AD−21)x,
2
x
⃗
T
x
⃗
≥
x
⃗
T
D
−
1
2
(
D
−
A
)
D
−
1
2
x
⃗
2\vec{x} ^T\vec{x}≥\vec{x} ^TD^{-\frac{1}{2}}(D-A){D}^{-\frac{1}{2}}\vec{x}
2xTx≥xTD−21(D−A)D−21x,
2
x
⃗
T
x
⃗
≥
x
⃗
T
L
s
y
m
x
⃗
2\vec{x} ^T\vec{x}≥\vec{x} ^TL_{sym}\vec{x}
2xTx≥xTLsymx,
2
≥
x
⃗
T
L
s
y
m
x
⃗
x
⃗
T
x
⃗
=
R
(
L
s
y
m
,
x
)
2≥\frac{\vec{x}^TL_{sym}\vec{x} }{\vec{x}^T\vec{x}}=R(L_{sym},x)
2≥xTxxTLsymx=R(Lsym,x)。
因为
L
s
y
m
L_{sym}
Lsym为半正定矩阵,所以
R
(
L
s
y
m
,
x
)
≥
0
R(L_{sym},x)≥0
R(Lsym,x)≥0,综上所述,
L
s
y
m
L_{sym}
Lsym的特征值取值范围是[0,2]。
四、Fourier Transform
1.什么是傅里叶变换
傅里叶变换是同一个事物在不同的域的不同视角,并不会改变事物本质。下图分别展示了同一个波形图的时域图象和频域图像。既然不会改变事物的本质,为什么需要傅里叶变换呢?因为有些操作在频域中更容易进行。例如有一段混合有男声和女声的音频,需要我们去除女声。在常规的时域空间是很难完成的,所以我们可以利用傅里叶变换转换到频域空间,利用女声频率比较高的特点,将高频部分去除,然后将得到的低频部分进行傅里叶逆变换,就可以得到只有男声的音频。
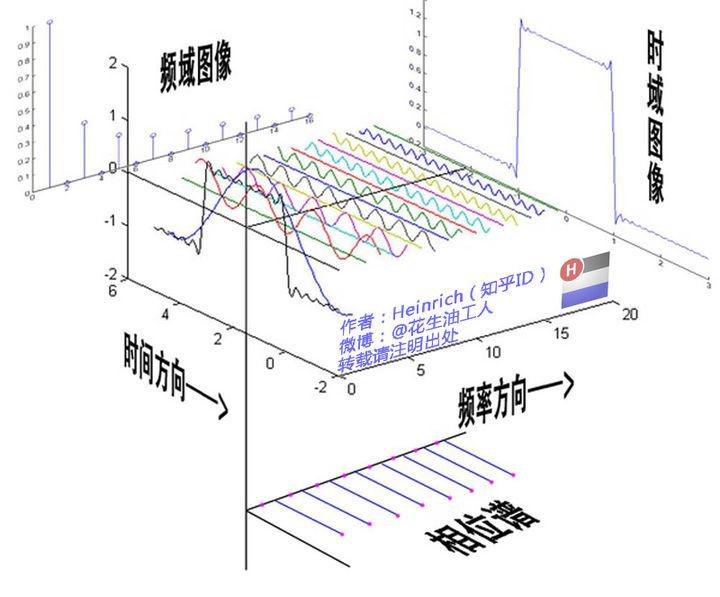
傅里叶变换参考链接:https://zhuanlan.zhihu.com/p/19763358
2.快速傅里叶变换(FFT)
给定下列函数:
f
(
x
)
=
a
0
+
a
1
x
+
a
2
x
2
+
.
.
.
+
a
n
x
n
f(x)=a_0+a_1x+a_2x^2+...+a_nx^n
f(x)=a0+a1x+a2x2+...+anxn
g
(
x
)
=
b
0
+
b
1
x
+
b
2
x
2
+
.
.
.
+
b
n
x
n
g(x)=b_0+b_1x+b_2x^2+...+b_nx^n
g(x)=b0+b1x+b2x2+...+bnxn
求
f
(
x
)
∗
g
(
x
)
f(x)*g(x)
f(x)∗g(x)
(1)如果利用暴力计算,则有
f
(
x
)
∗
g
(
x
)
=
c
0
+
c
1
x
+
c
2
x
2
+
.
.
.
+
c
2
n
x
2
n
f(x)*g(x)=c_0+c_1x+c_2x^2+...+c_{2n}x^{2n}
f(x)∗g(x)=c0+c1x+c2x2+...+c2nx2n
此时的复杂度为
O
(
n
2
)
O(n^2)
O(n2)
(2)利用快速 傅里叶变换将f(x)和g(x)转换为由点对组成的域,此时有
f
(
x
)
⇔
(
x
1
,
f
(
x
1
)
)
,
(
x
2
,
f
(
x
2
)
)
,
.
.
.
,
(
x
n
+
1
,
f
(
x
n
+
1
)
)
f(x)\Leftrightarrow(x_1,f(x_1)),(x_2,f(x_2)),...,(x_{n+1},f(x_{n+1}))
f(x)⇔(x1,f(x1)),(x2,f(x2)),...,(xn+1,f(xn+1))
g
(
x
)
⇔
(
x
1
,
g
(
x
1
)
)
,
(
x
2
,
g
(
x
2
)
)
,
.
.
.
,
(
x
n
+
1
,
g
(
x
n
+
1
)
)
g(x)\Leftrightarrow(x_1,g(x_1)),(x_2,g(x_2)),...,(x_{n+1},g(x_{n+1}))
g(x)⇔(x1,g(x1)),(x2,g(x2)),...,(xn+1,g(xn+1))
f
(
x
)
∗
g
(
n
)
⇔
(
x
1
,
f
(
x
1
)
g
(
x
1
)
)
,
(
x
2
,
f
(
x
2
)
g
(
x
2
)
)
,
.
.
.
,
(
x
n
+
1
,
f
(
x
n
+
1
)
g
(
x
n
+
1
)
)
f(x)*g(n)\Leftrightarrow(x_1,f(x_1)g(x_1)),(x_2,f(x_2)g(x_2)),...,(x_{n+1},f(x_{n+1})g(x_{n+1}))
f(x)∗g(n)⇔(x1,f(x1)g(x1)),(x2,f(x2)g(x2)),...,(xn+1,f(xn+1)g(xn+1))
此时的复杂度由三部分组成:
①将函数从系数表示转换为点对表示的复杂度
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn);
②在点对域的乘法
f
(
x
)
∗
g
(
n
)
f(x)*g(n)
f(x)∗g(n)的复杂度为O(n);
③将
f
(
x
)
∗
g
(
n
)
f(x)*g(n)
f(x)∗g(n)从点对表示转换为系数表示的复杂度
O
(
n
l
o
g
n
)
O(nlogn)
O(nlogn)。
因此总的复杂度为
O
(
n
)
+
2
O
(
n
l
o
g
n
)
O(n)+2O(nlogn)
O(n)+2O(nlogn)。
3.图的傅里叶变换
x
⃗
\vec{x}
x为列向量,
L
x
⃗
=
[
∑
(
i
,
j
)
∈
E
(
x
1
−
x
j
)
∑
(
i
,
j
)
∈
E
(
x
2
−
x
j
)
.
.
.
.
.
.
∑
(
i
,
j
)
∈
E
(
x
n
−
x
j
)
]
L\vec{x}= \begin{bmatrix} \sum_{(i,j)∈E}^{}(x_1-x_j) \\ \sum_{(i,j)∈E}^{}(x_2-x_j)\\ ...\\ ...\\ \sum_{(i,j)∈E}^{}(x_n-x_j) \end{bmatrix}
Lx=⎣
⎡∑(i,j)∈E(x1−xj)∑(i,j)∈E(x2−xj)......∑(i,j)∈E(xn−xj)⎦
⎤,
(
x
1
−
x
j
)
(x_1-x_j)
(x1−xj)中的
x
j
x_j
xj表示的是与
x
1
x_1
x1相连的点,
(
x
2
−
x
j
)
(x_2-x_j)
(x2−xj)中的
x
j
x_j
xj表示的是与
x
2
x_2
x2相连的点,其他以此类推。我们可以发现,
x
⃗
\vec{x}
x在乘了L之后,其实是进行了一个类似于聚合邻居的操作。
因为
L
=
U
Λ
U
T
L=U\Lambda U^{T}
L=UΛUT
所以
L
x
⃗
=
U
Λ
U
T
x
⃗
L\vec{x}=U\Lambda U^{T}\vec{x}
Lx=UΛUTx,这个式子的意思是,
U
T
x
⃗
U^{T}\vec{x}
UTx先对
x
⃗
\vec{x}
x进行基底变换,
Λ
U
T
x
⃗
\Lambda U^{T}\vec{x}
ΛUTx意思是在新基底中对
x
⃗
\vec{x}
x进行放缩,
L
x
⃗
=
U
Λ
U
T
x
⃗
L\vec{x}=U\Lambda U^{T}\vec{x}
Lx=UΛUTx的意思是最后将放缩后的
x
⃗
\vec{x}
x变换回原始的基底表示。我们发现,经过傅里叶变换后,在新的域中,我们只对每个维度进行了放缩操作,就完成了邻居的聚合。
五、GCN
1.图卷积
首先要定义图上的卷积操作,例如我们将图的邻接矩阵输入函数后得到L或者
L
s
y
m
L_{sym}
Lsym,即
F
(
A
)
→
L
(
或者是
L
s
y
m
)
F(A)\to L(或者是L_{sym})
F(A)→L(或者是Lsym)。设
F
(
A
)
=
U
Λ
U
T
F(A)=U\Lambda U^T
F(A)=UΛUT,则图上的卷积操作可以定义为
g
θ
∗
x
=
U
g
θ
(
Λ
)
U
T
x
g_{\theta}*x=Ug_{\theta}(\Lambda)U^Tx
gθ∗x=Ugθ(Λ)UTx,
U
T
x
U^Tx
UTx指的是先用傅里叶变换将x转换到频域中,
(
Λ
)
U
T
x
(\Lambda)U^Tx
(Λ)UTx直达实在频域空间中执行操作,
g
θ
(
Λ
)
g_{\theta}(\Lambda)
gθ(Λ)是我们要学习的关于特征值
Λ
\Lambda
Λ的函数,
U
g
θ
(
Λ
)
U
T
x
Ug_{\theta}(\Lambda)U^Tx
Ugθ(Λ)UTx指的是执行完操作后将域转换回对应的空间域。我们限定
g
θ
(
Λ
)
=
θ
0
Λ
0
+
θ
1
Λ
1
+
.
.
.
+
θ
n
Λ
n
+
.
.
.
g_{\theta}(\Lambda)={\theta}_0\Lambda^0+{\theta}_1\Lambda^1+...+{\theta}_n\Lambda^n+...
gθ(Λ)=θ0Λ0+θ1Λ1+...+θnΛn+...。
则有
U
g
θ
(
Λ
)
U
T
=
g
θ
(
U
Λ
U
T
)
=
g
θ
(
F
(
A
)
)
Ug_{\theta}(\Lambda)U^T=g_{\theta}(U\Lambda U^T)=g_{\theta}(F(A))
Ugθ(Λ)UT=gθ(UΛUT)=gθ(F(A)),如此一来就不用进行特征分解了,复杂度也得以下降。
2.切比雪夫多项式
在实际操作中,我们很少使用系数的方式去拟合多项式,因为随着n的变大,使用系数的方式会面临梯度消失或者梯度爆炸的问题,因此我们一般采用切比雪夫多项式去拟合多项式。
【定义】:
T
n
(
x
)
=
2
x
T
n
−
1
(
x
)
−
T
n
−
2
(
x
)
,其中
T
0
(
x
)
=
1
,
T
1
(
x
)
=
x
T_n(x)=2xT_{n-1}(x)-T_{n-2}(x),其中T_0(x)=1,T_1(x)=x
Tn(x)=2xTn−1(x)−Tn−2(x),其中T0(x)=1,T1(x)=x。
切比雪夫多项式不会出现梯度消失或者梯度爆炸的原因是
T
n
(
c
o
s
θ
)
=
c
o
s
n
θ
T_n(cos\theta)=cosn\theta
Tn(cosθ)=cosnθ,也就是无论n多大,
T
n
(
c
o
s
θ
)
T_n(cos\theta)
Tn(cosθ)在数值上都有摆动的稳定趋势。但这也要求自变量必须要在[-1,1]中取值,在这里也就是要求特征值的取值范围在[-1,1]。因为
L
s
y
m
L_{sym}
Lsym的特征值取值范围是[0,2],因此要想在[-1,1]中取值,只需减去一个单位矩阵,所以
F
(
A
)
=
U
Λ
U
T
=
L
s
y
m
−
I
F(A)=U\Lambda U^T=L_{sym}-I
F(A)=UΛUT=Lsym−I,最终卷积的定义可以写为
g
θ
∗
x
=
U
g
θ
(
Λ
)
U
T
x
=
U
(
∑
k
=
0
k
θ
k
T
k
(
Λ
)
)
U
T
x
=
∑
k
=
0
k
θ
k
T
k
(
U
Λ
U
T
)
x
=
∑
k
=
0
k
θ
k
T
k
(
L
s
y
m
−
I
)
x
g_{\theta}*x =Ug_{\theta}(\Lambda)U^Tx =U(\sum_{k=0}^{k}\theta_kT_k(\Lambda))U^Tx =\sum_{k=0}^{k}\theta_kT_k(U\Lambda U^T)x =\sum_{k=0}^{k}\theta_kT_k(L_{sym}-I)x
gθ∗x=Ugθ(Λ)UTx=U(∑k=0kθkTk(Λ))UTx=∑k=0kθkTk(UΛUT)x=∑k=0kθkTk(Lsym−I)x
设k的最大值为1,则有
∑
k
=
0
k
θ
k
T
k
(
L
s
y
m
−
I
)
x
=
θ
0
T
0
(
L
s
y
m
−
I
)
x
+
θ
1
T
1
(
L
s
y
m
−
I
)
x
=
θ
0
x
+
θ
1
(
L
s
y
m
−
I
)
x
\sum_{k=0}^{k}\theta_kT_k(L_{sym}-I)x =\theta_0T_0(L_{sym}-I)x+\theta_1T_1(L_{sym}-I)x =\theta_0x+\theta_1(L_{sym}-I)x
∑k=0kθkTk(Lsym−I)x=θ0T0(Lsym−I)x+θ1T1(Lsym−I)x=θ0x+θ1(Lsym−I)x
因为
L
s
y
m
=
D
−
1
2
L
D
−
1
2
=
D
−
1
2
(
D
−
A
)
D
−
1
2
=
I
−
D
−
1
2
A
D
−
1
2
L_{sym}=D^{-\frac{1}{2}}LD^{-\frac{1}{2} }=D^{-\frac{1}{2}}(D-A)D^{-\frac{1}{2} }=I-D^{-\frac{1}{2}}AD^{-\frac{1}{2} }
Lsym=D−21LD−21=D−21(D−A)D−21=I−D−21AD−21
所以
θ
0
x
+
θ
1
(
L
s
y
m
−
I
)
x
=
θ
0
x
−
θ
1
D
−
1
2
A
D
−
1
2
\theta_0x+\theta_1(L_{sym}-I)x=\theta_0x-\theta_1D^{-\frac{1}{2}}AD^{-\frac{1}{2}}
θ0x+θ1(Lsym−I)x=θ0x−θ1D−21AD−21
令
θ
1
=
−
θ
0
\theta_1=-\theta_0
θ1=−θ0,则
θ
0
x
−
θ
1
D
−
1
2
A
D
−
1
2
=
θ
0
(
I
+
D
−
1
2
A
D
−
1
2
)
X
⇒
D
^
−
1
2
A
^
D
^
−
1
2
x
\theta_0x-\theta_1D^{-\frac{1}{2}}AD^{-\frac{1}{2}}=\theta_0(I+D^{-\frac{1}{2}}AD^{-\frac{1}{2}})X\Rightarrow\hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}x
θ0x−θ1D−21AD−21=θ0(I+D−21AD−21)X⇒D^−21A^D^−21x。
参考链接:
https://www.bilibili.com/video/BV1Vw411R7Fj?p=1&vd_source=ddb3c83e8d9149762cf2ab01fbab10e4
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









