






哈喽大家好,我是歪小王,本期继续分享pytest学习笔记。本期主要是pytest的常用插件补充以及pytest常用装饰器
01 上期回顾
上期内容主要围绕pytest配置文件进行阐述,其中包括命令行参数、失败重试、生成html版本的测试报告、分组以及文件路径设置、运行顺序等。本期就上期内容进行一点补充。
上期我们说到pytest的运行方式是由上至下的线性运行方式,那在日常工作中。有些用例是要优先执行的,在我们写完用例后,才发现这些前置用例写在了用例队列中的后几行,这个时候就可以使用pytest中控制排序方法进行排序。使用方法如下
安装pip install pytest-ordering 进行安装
使用装饰器在需要控制顺序的函数上增加这个装饰器即可
@pytest.mark.run(order = x)
def test_login(self):....
# 优先级:0 > 较小的正数 > 较大的正数 > 空 > 较小的负数 > 较大的负数分布式执行:
当我们将所有的⾃动化测试⽤例都编写完成后,进⾏执⾏时,由于case较多,导致执⾏速度⽐较慢,那么如何提高用例执行效率呢?
安装 pip install pytest-xdist;
分布式命令:-n x/auto (x表示分布执行数,auto则是根据当前硬件CPU核芯数进行自动分配)
使用方式有三种:
1.在配置文件中的命令行参数增加-n x
2.在main文件中增加-n x
3.在terminal使用pytest命令运行时,在命令后面增加-n x
from time import sleep
class TestDemo:
def test_demo(self):
sleep(2)
print("测试用例1")
def test_demo2(self):
sleep(2)
print("测试用例2")
def test_demo3(self):
sleep(2)
print("测试用例3")
def test_demo4(self):
sleep(2)
print("测试用例4") 如上代码,使用普通执行,运行时间大概是8秒多一点

使用分布式后效果如下

02 pytest装饰器扩展
日常用例执行中,会遇到某些用例需要跳过、做预期值,以及最重要也是最常用的数据参数化。那么在pytest中,也自带了这些装饰器。
跳过测试函数
使用修饰器
@pytest.mark.skipif(布尔类型, reason='不想执行了')
如果第一个参数为True就跳过。如果为False就不跳过
reason是跳过原因,入参类型必须是一个字符串
class TestLogin:
S = 5
def test_login(self):
print('test_login')
assert 1
# reason不能传None
@pytest.mark.skipif(S < 6, reason='不想执行了')
def test_login_b(self):
print('test_login_b')
assert 1预期失败
应用场景:一般会使用在反向测试的时候
使用装饰器标记用例,并写入预期值:
@pytest.mark.xfail(布尔类型, reason='')
如果为True是预期失败,如果是False是预期成功
报告结论:
红色的表示bug(预期和结果不一致)
带X的,表示预期失败
import pytest
class TestLogin:
S = 5
# 预期成功。结果成功
@pytest.mark.xfail(False, reason='')
def test_login1(self):
print('test_login')
assert 1
# 预期成功。结果失败
@pytest.mark.xfail(False, reason='')
def test_login2(self):
print('test_login_b')
assert 0
# 预期失败。结果失败
@pytest.mark.xfail(True, reason='')
def test_login3(self):
print('test_login')
assert 0
# 预期失败 结果成功
@pytest.mark.xfail(True, reason='')
def test_login4(self):
print('test_login')
assert 1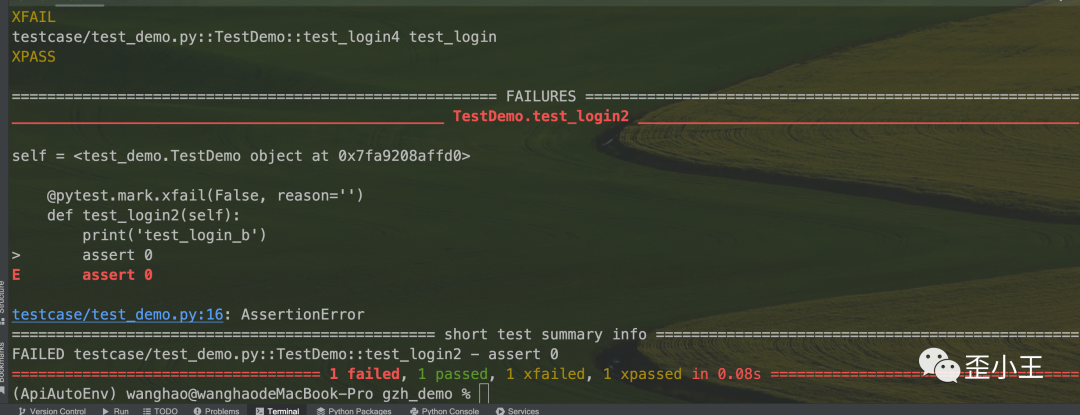
数据参数化
应用场景:同一个接口,不同用例,一般是一个正向用例,多个反向用例
使用装饰器:
单个参数:@pytest.mark.parametrize('参数名', [参数值1,参数值2......])
多个参数:@pytest.mark.parametrize((“参数名1”,“参数名2”....), [(“参数名1的值1”,“参数名2的值1”),(“参数名1的值2”,“参数名2的值2”)])
# 单个参数化装饰器。参数传入,name(参数名),[参数值1,参数值2......] 多个值之间用逗号分割
@pytest.mark.parametrize('name', ['lisi', 'zhangssan'])
def test_contact(self, name):
print(name)
# 多个参数在单个参数的基础上,将参数名变成元祖。参数值以列表嵌套元祖的方式
# 实现[('zhangsan','18888888888'),('lisi','13333333333')]
#参数名可以以元祖方式,也可以以字符串方式传--->>'name,phone'
@pytest.mark.parametrize(('name','phone'), [('zhangsan','188888888888'),('lisi','13333333333')])
def test_contact(self, name , phone):
print("姓名是:",name)
print("手机号是:",phone)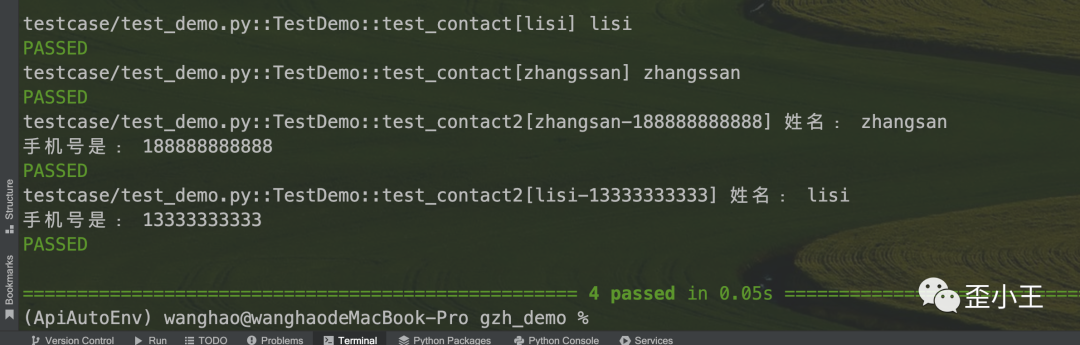
可以看到。上方用例代码只写了两条,但是结果中则是四条case。这就是参数化的好处。简化代码的同时,可以覆盖更多的场景
03 结语
好了。本期内容就到这里了。大家下期见。拜拜~














 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









