






各位周末好~小王同学又来给大家分享内容了。本期接着上一期的celery做一个收尾。废话不多,昊料开始~
开篇
上篇对celery做了简单的介绍。在我们日常项目中,少不了分层思想。本期就分层结构做一个简单的整理,以及在flask中,如何使用celery,实现消息的处理
消费者
首先我们将目录结构区分为两个模块。一个消费者、一个生产者(废话~~)

生产者我们先抛开不提。后面我们将flask的视图函数当做生产者即可
先捋一下消费者需要哪些内容?
消息中间件的连接路径
实例化celery对象
天选打工人(消费者回调函数)
根据上面的区分,我们可以先实例化celery对象。先罗列出一个整体的目录结构
celery_uitl
--- main.py
--- config.py
--- workers
--- tasks.pymain.py
# 1.实例化celery对象
cel_app = celer.Celery("flask_celery")、
# 3.绑定配置
# cel_app下有个加载config的方法。写入配置文件所在目录即可。
# 注意此处路径的符号也是“.”
cel_app.config_from_object("celery_util.config")
# 5.绑定消费者
# autodiscover_tasks方法底层默认制定了消费者文件的名称。如果想要修改
cel_app.autodiscover_tasks(["celery_util.workers"])接着往下就是绑定中间件以及rendis
我们可以在上面实例化对象时,就将配置写死进去。但是在日常工作中,避免不了修改配置的情况。所以将其提取在配置文件中。(为了减少废话,就在上下这两个模块维护。请按照编号来看)
创建一个config的配置文件
config.py
#2.编写配置文件
# 接收和发送任务
BROKER_URL = "pyamqp://0.0.0.0:5673"
# 存储任务结果
CELERY_RESULT_BACKEND = "redis://0.0.0.0:6379/1"最后是雇佣一个工人,来帮助我们执行任务并将任务结果返回(创建一个tasks的文件)
此处这个tasks的文件名必须写死,因为在celery底层默认会读取这个文件名。当然,如果想使用自定义了文件名,可以指定autodiscover_tasks() 的related_name=指定的文件名。注意不要加后缀
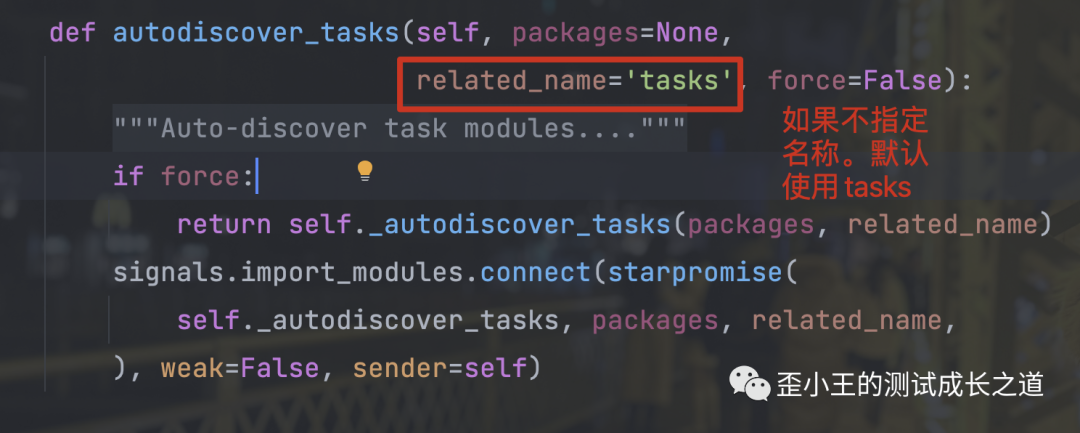
workers/tasks.py
# 4. 创建一个消费者
@cel_app.task
def create_case_file(name):
...
return {"msg": name}以上消费者的定义就搞定了
生产者
刚才说到,生产者可以结合视图函数来生产数据
举个小例子
from celery_util.workers.tasks import create_case_file
result = ""
@app.route("/index",methods=["GET","POST"])
def index():
global result
# 生产者创建数据
result = create_case_file.delay(name)
return "index.html"
@app.route("/get_result")
def get_result():
global result
# 获取消费者处理的结果
task_result = AsyncResult(id = result.id,app = cel_app)
return jsonfly({"result":task_result.result})上面这个例子中:
index创建了数据。并调用消费者启动线程,处理任务
get_result函数通过result变量,提取消费者处理的结果。并将结果返回
这里我简单用了个公共变量result来达成视图函数之间变量的传递。在项目中,我们可以通过ajax来传递result.id,并持续从**/get_result**这个路由上面获取任务的执行进度。实现页面loading的交互功能
结语
以上就是celery多目录以及结合flask的全部内容了
今天的分享就到这里了,各位大佬,下期见~~















 1661
1661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









