






Flow Matching 是让模型学会一条“路径”,把一个随机点(比如噪声)顺滑地“流动”到目标数据的过程。
想象你有两个点,一个是起点,一个是终点。你已经知道用线性插值能画出这两个点之间的直线。那么 Flow Matching 的任务,就是教模型沿着这条“直线路径”去走,每一步往哪个方向走、走多快。
通俗类比:导航软件
想象你在用地图导航从 A 地(起点)走到 B 地(终点):
-
你知道直线路径(线性插值告诉你路线)。
-
但是你需要实时告诉导航系统“当前我在哪,该往哪走”。
-
Flow Matching 就是训练一个“导航系统”,学会告诉模型每一时刻的前进方向。
这个“方向”就是一个 向量场(vector field),告诉你:
如果我现在在某个点,时间是 t,那么我应该往哪个方向动。
数学解释
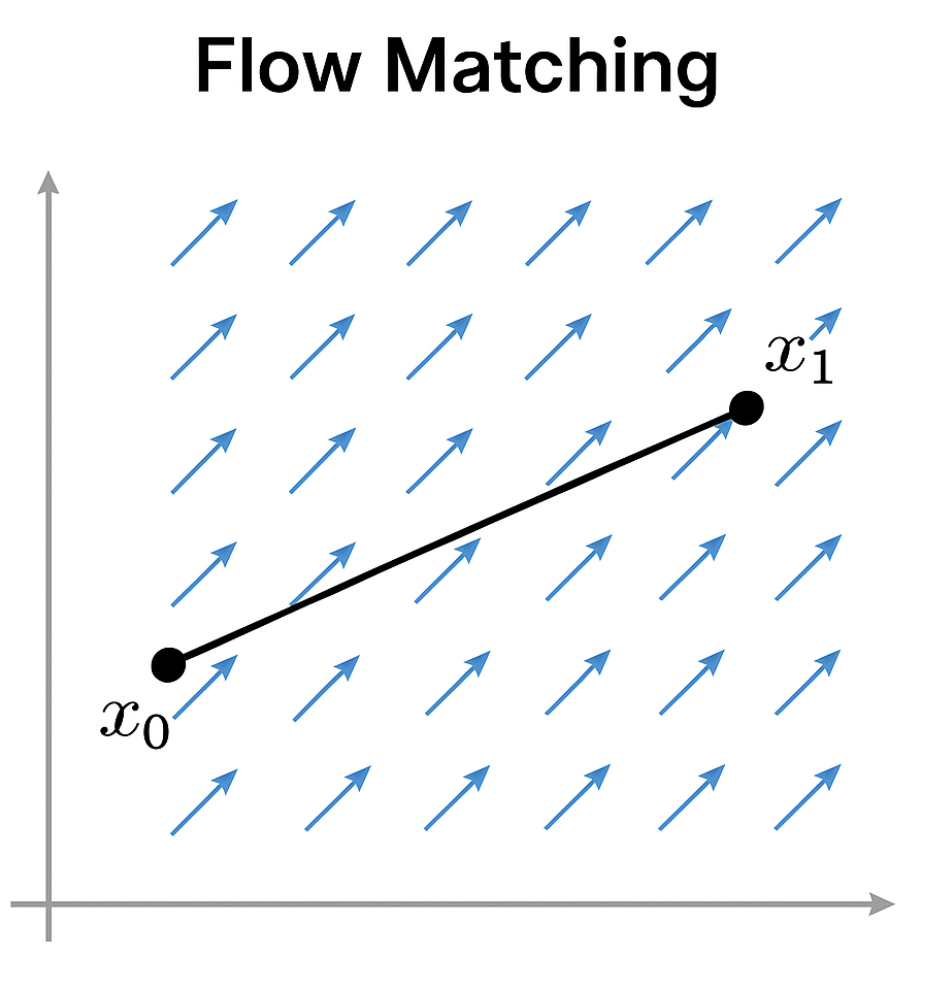
给定起点 x0,终点 x1,用线性插值构造路径:
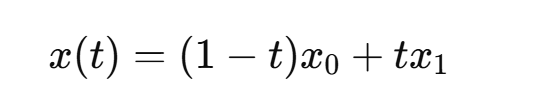
那么这个路径的速度(也就是方向)是常量:
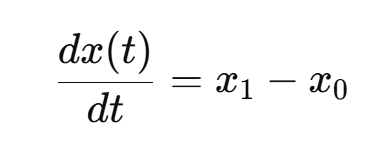
Flow Matching 就是学一个模型 v(x,t)≈x1−x0, 也就是说:学会在路径上的每个位置给出“正确的前进方向”。
FM有什么用?
在生成模型中,比如扩散模型、flow-based 模型,我们想从“随机点”生成真实数据。Flow Matching 提供了一种:
-
不用噪声预测、
-
不用 score function、
-
直接建模路径的方法。
换句话说,它是一种“不走弯路”的生成方式—— 给你一条理想路线,学会沿着走!
举个实验例子
比如你训练一个模型,把标准高斯分布的点(起点)转换成一张猫的图片的 latent 向量(终点)。你就:
-
抽一个高斯样本 x0,
-
用训练好的编码器拿到猫的 latent 表示 x1,
-
构造线性路径 x(t),
-
训练模型 v(x,t)逼近路径方向。
训练好后,你只需要从 x0出发,用这个向量场引导它一步步“流”到猫图像对应的隐空间 —— 这就是 Flow Matching 的生成过程。
📌 总结一句话
Flow Matching 就是:“我已经知道从哪里到哪里(起点到终点),我要训练一个模型,在任意中间位置都能告诉我应该往哪走”,而这个“走”的路径,通常用线性插值定义。
在大语言模型(LLM)中,Flow Matching(FM)策略通常被用来训练潜在空间中的向量场,以实现高效、平滑地从随机初始化(如高斯噪声)“流”向语言表示或模型权重,尤其在以下两个方向中具有代表性:
应用于 LLM 蒸馏 / 微调
在参数空间或表示空间中,Flow Matching 可用于训练一个连续路径模型,将:
-
✅ 一个轻量模型的初始表示(或参数) x0
-
✅ 流向一个强大教师模型的表示(或参数) x1
训练目标是:
学习一个向量场 v(x,t),满足对所有 t 有:
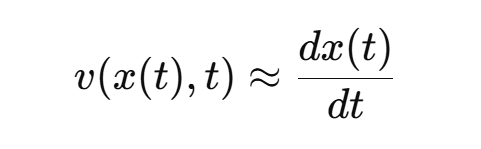
其中路径 x(t)通常用线性插值定义:
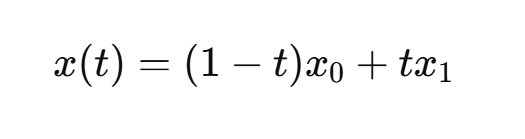
应用于表示空间训练(如 Diffusion Transformer)
一些生成式 Transformer 模型(如 DiffuSeq、FlowSeq)中,在训练阶段:
-
把目标 token 表示 x1和随机初始表示 x0 定义好;
-
用 Flow Matching 拟合它们之间的路径方向;
-
最终生成时,从随机向量出发,沿着学到的流动轨迹“流”向真实句子向量,实现解码。
训练流程(伪代码)
# x0: 起点 (如随机 token embedding)
# x1: 终点 (如真实句子的 embedding)
# t: 时间采样
t = torch.rand(batch_size, 1)
# 路径上的点
x_t = (1 - t) * x0 + t * x1
# 真正的速度向量(线性插值导数是常量)
v_target = x1 - x0
# 模型预测的向量场
v_pred = model(x_t, t)
# 最小化方向误差(MSE loss)
loss = ((v_pred - v_target) ** 2).mean()
loss.backward()
优势

在语言模型中的延伸方向
-
Embedding Flow Matching:生成 token embedding 的向量场;
-
Hidden State Matching:transformer 中间层状态的连续路径建模;
-
权重空间 Matching(如 model soup):多个模型参数之间的“流动”建模;
-
少样本 / 零样本迁移:基于 flow 把旧任务表示迁移到新任务。
📌 总结一句话:
在大语言模型中,Flow Matching 通过建模表示或参数空间中的“连续轨迹”,用向量场预测从初始状态流向目标状态的路径,从而实现更平滑、更高效的表示学习或生成过程。
📢 想要了解更多人工智能,可在VX小程序搜索🔍AI Pulse,获取更多最新内容。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











