







一、概述
一个执行计划确切地定义了每个运算应使用的算法以及它们之间的执行应该如何协调。查询优化器的任务是产生一个查询计划,与原关系表达式相同并且结果执行代价最小。
产生查询执行计划分3步走:
- 产生逻辑上与给定表达式等价的表达式
- 对所产生的表达式以不同的方式做注释,产生不同的查询计划
- 估计每一个执行计划的代价,选择估计代价最小的一个
二、关系表达式转换的等价规则
用 θ , θ 1 , θ 2 \theta,\theta_1,\theta_2 θ,θ1,θ2代表为此, L , L 1 , L 2 L,L_1,L_2 L,L1,L2代表属性列表, E , E 1 , E 2 E,E_1,E_2 E,E1,E2代表关系代数表达式,r代表关系实例,可以出现在所有E出现的地方,则:
- 合取选择运算可分解为单个选择运算的序列。改变换被称为
σ
\sigma
σ的级联:
σ θ 1 ∧ θ 2 ( E ) = σ θ 1 ( σ θ 2 ( E ) ) \sigma_{\theta_1\land\theta_2}(E)=\sigma_{\theta_1}(\sigma_{\theta_2}(E)) σθ1∧θ2(E)=σθ1(σθ2(E)) - 选择运算满足交换律(commutative):
σ θ 1 ( σ θ 2 ( E ) ) = σ θ 2 ( σ θ 1 ( E ) ) \sigma_{\theta_1}(\sigma_{\theta_2}(E))=\sigma_{\theta_2}(\sigma_{\theta_1}(E)) σθ1(σθ2(E))=σθ2(σθ1(E)) - 一系列投影运算中只有最后有一个运算时必须的,其余可省略,该转换也可被称为
∏
\prod_{}
∏的级联:
∏ L 1 ( ∏ L 2 ( . . . ∏ L n ( E ) . . . ) ) = ∏ L 1 ( E ) \prod_{L_1}(\prod_{L_2}(...\prod_{L_n}(E)...))=\prod_{L_1}(E) ∏L1(∏L2(...∏Ln(E)...))=∏L1(E) - 选择操作可与笛卡儿积以及
θ
\theta
θ连接相结合
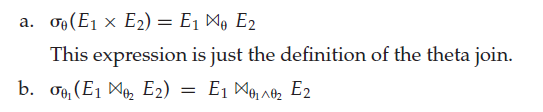
-
θ
\theta
θ连接运算满足交换律:
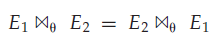
事实上如果考虑属性顺序时,这一条定律并不成立 - 自然连接运算满足结合律(associative),
θ
\theta
θ连接满足广义的结合律:
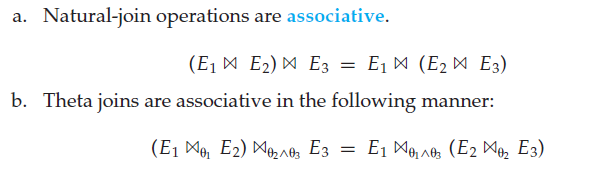
上面的式子事实上意味着笛卡尔积也满足结合律 - 选择运算在下面两个调剂按下对
θ
\theta
θ连接运算也具有分配律(选择的下沉):
a. 当选择条件 θ 0 \theta_0 θ0中的所有属性只涉及参与链接运算的表达式之一(比如 E 1 E_1 E1时),满足分配律
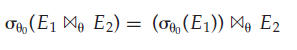
b. 当选择条件 θ 1 \theta_1 θ1只涉及 E 1 E_1 E1的属性,选择条件 θ 2 \theta_2 θ2只涉及 E 2 E_2 E2的属性时,满足分配律:
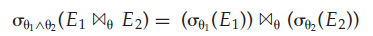
- 投影运算在下面条件下对
θ
\theta
θ连接运算具有分配律:

- 集合的并与交满足交换律,单集合的差不满足交换律
- 集合的并于交满足结合律
- 选择运算对并、交、差运算具有分配律:
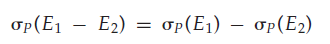
- 投影运算对并运算具有分配律。
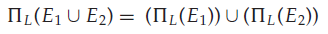
三、表达式结果集统计大小的估计
1. 统计数据阐述
数据库系统同目录存储了有关数据库关系的下列统计信息:
- n r n_r nr,关系r的元组数
- b r b_r br,包含关系r中元组的磁盘块数
- l r l_r lr,关系r中每个元组的字节数
- f r f_r fr,关系r的块因子,也即一个磁盘块中能容纳关系r中元组的个数
-
V
(
A
,
r
)
V(A,r)
V(A,r),关系r中属性A中出现的非重复值个数。该值与
∏
A
(
r
)
\prod_A(r)
∏A(r)的大小相同,如果A式关系r的主码,则
V
(
A
,
r
)
V(A,r)
V(A,r)等于
n
r
n_r
nr。
需要的话,V(A,r)可以针对某个属性集,而非单独的属性来维护。
延申:如果假设关系r的元组在物理上存储于一个文件中,则有
b
r
=
⌈
n
r
f
r
⌉
b_r=\lceil \frac{n_r}{f_r}\rceil
br=⌈frnr⌉成立。
另外,关于索引的统计信息,如B+树索引的高度和索引中叶节点的页数,也保存在目录中。
2.选择运算结果大小的估计
| 选择操作 | 分析 | 结果 |
|---|---|---|
| σ A = a ( r ) \sigma_{A=a}(r) σA=a(r) | 假设每个值出现概率相等,则结果应该与元组数正比,与重复值数量呈反比 | n r / V ( A , r ) n_r/V(A,r) nr/V(A,r) |
| σ A ≤ v ( r ) \sigma_{A\leq v}(r) σA≤v(r) | 如果统计信息中保留了A属性下的最小值min(A,r)和最大值max(A,r),可以进行更精确的判断 | 0 f o r v ≤ m i n ( A , r , n r f o r v ≥ m a x ( A , r ) , n r ⋅ v − m i n ( A , r ) m a x ( A , r ) − m i n ( A , r ) o t h e r w i z e . 0\ for\ v\leq min(A,r,\\n_r\ for\ v\geq max(A,r),\\ n_r\cdot \frac{v-min(A,r)}{max(A,r)-min(A,r)}\ otherwize. 0 for v≤min(A,r,nr for v≥max(A,r),nr⋅max(A,r)−min(A,r)v−min(A,r) otherwize. |
| σ θ 1 ∧ . . . ∧ θ n ( r ) \sigma_{\theta_1\land...\land\theta_n}(r) σθ1∧...∧θn(r) | 对每一个合取项,将 σ θ i ( r ) \sigma_{\theta_i}(r) σθi(r)的大小记为 s i s_i si,那么某一个元组存在于这个自己的概率是 s i n r \frac{s_i}{n_r} nrsi,那么如果这n个选择是互相独立的,满足所有合取项选择的概率就是所有上述概率的乘积 | 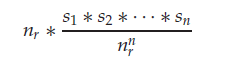 |
| σ θ 1 ∨ . . . ∨ θ n ( r ) \sigma_{\theta_1\vee...\vee\theta_n}(r) σθ1∨...∨θn(r) | 析取项与合取项类似,整体取反后每项取反即可得到 | 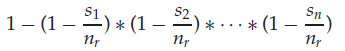 |
| σ ¬ θ ( r ) \sigma_{\neg\theta}(r) σ¬θ(r) | 如果null值不存在,结果就是总数减去正选择的数量 | n r − s i z e ( σ θ ( r ) ) n_r-size(\sigma_\theta(r)) nr−size(σθ(r)) |
3.连接的结果的大小估计
笛卡尔积
r
×
s
r\times s
r×s包含
n
r
∗
n
s
n_r*n_s
nr∗ns个元组,而每个元组占用
l
r
+
l
s
l_r+l_s
lr+ls个字节,因此可计算出笛卡尔积的大小。
更难以估算的是自然连接的大小,需要分情况讨论,令
r
(
R
)
r(R)
r(R)和
s
(
S
)
s(S)
s(S)为两个关系:

对于所有的 θ \theta θ连接,对于估计上的方法与执行策略无关,直接将其化为 σ θ ( r × s ) \sigma_\theta(r\times s) σθ(r×s),对一次选择和一次笛卡尔积做估计即可。
4. 其他运算结果集的大小估计
| 操作名称 | 描述 | 结果 |
|---|---|---|
| ∏ A ( r ) \prod_A(r) ∏A(r) | 去除了重复元组 | V ( A , r ) V(A,r) V(A,r) |
| A G F ( r ) _A\mathcal{G}_F(r) AGF(r) | 对A的任意一个不同取值在其中总有且只有一个元组与其对应 | V ( A , r ) V(A,r) V(A,r) |
| 集合运算 | 将所有的几个运算携程关系谓词的合取/析取形式 |















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









