






MySQL索引详解
一、什么是索引?为什么要建立索引?
索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,而不必查看所有数据,那么将会节省很大一部分时间。
打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是一个人力三轮车。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
二、MySQL中索引的优缺点及使用原则
优点:
1、所有的MySql列类型(字段类型)都可以被索引,也就是可以给任意字段设置索引
2、大大加快数据的查询速度
缺点:
1、创建索引和维护索引要耗费时间,并且随着数据量的增加所耗费的时间也会增加
2、索引也需要占空间,我们知道数据表中的数据也会有最大上线设置的,如果我们有大量的索引,索引文件可能会比数据文件更快达到上线值
3、当对表中的数据进行增加、删除、修改时,索引也需要动态的维护,降低了数据的维护速度。
使用原则:
通过上面说的优点和缺点,我们应该可以知道,并不是每个字段度设置索引就好,也不是索引越多越好,而是需要自己合理的使用。
1、对经常更新的表就避免对其进行过多的索引,对经常用于查询的字段应该创建索引,
2、数据量小的表最好不要使用索引,因为由于数据较少,可能查询全部数据花费的时间比遍历索引的时间还要短,索引就可能不会产生优化效果。
3、在一同值少的列上(字段上)不要建立索引,比如在学生表的"性别"字段上只有男,女两个不同值。相反的,在一个字段上不同值较多可以建立索引。
三、Explain执行器名词解释
1、作用
- 复杂sql语句的读取顺序
- sql中有哪些索引可以使用
- sql中哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
2、使用方法
- EXPLAIN + 查询sql
- 如:EXPLAIN SELECT * FROM test_index;
3、基本字段解读

4、Explain字段详解
id
select查询的序列号,并不是单纯的从上到下或者从下向上执行,共有三种情况
- id相同:按照从上到下的顺序执行
- id不同:按照id值由大到小的顺序执行
- id既有相同又有不同:先执行id值大的,然后相同值的从上到下执行
select_type
分别用来表示查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
值如下:
- SIMPLE:简单查询,不包含子查询和UNION查询
- PRIMARY:主查询,如包含子查询的sql中的父查询
- SUBQUERY:查询sql中的子查询
- DERIVED:衍生查询(在from列表中的子查询,Mysql递归这些子查询,结果放到临时表中)
- UNION:联合查询,t1 UNION t2 中的t2
- UNION RESULT:从UNION表获取结果的SELECT分别用来表示查询的类型


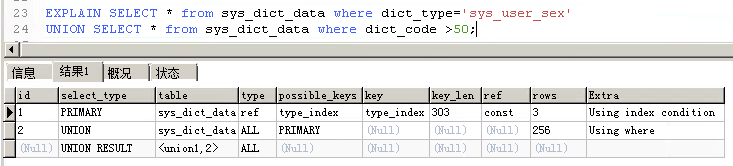
table
一般指查询的表,对于带尖括号的,表示select_type + id的指向。
partitions
如果查询是基于分区表的话,会显示查询将访问的分区。
type
type所显示的是查询使用了哪种类型
查询速度:null > syetem > const > eq_ref > ref > range > index > all
- null:甚至不需要访问索引表,例如主键作为条件超过当前表主键最大值;
- system:const的特殊情况,只有一条数据的系统表
- const:使用唯一索引等价查询,仅能匹配到一条数据
- eq_ref:使用唯一索引作为关联条件,匹配多条不重复数据
- ref:普通索引等价
- range:检索给定范围的索引 , > 、< 、>= 、<=、between and
- index:仅查询索引表
- all:遍历全表以找到匹配的行
possible_keys
显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,
但不一定被查询实际使用
key
查询中实际使用到的索引,小于等于possible_keys
key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度,在不损失精确性的情况下,长度越短越好。
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。

ref
表示查询中的连接匹配条件,即哪些列或常量被用于查找索引列上的值
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,也就是说,用的越少越好
filtered
按表条件过滤的行百分比
Extra
查询结果的备注信息,很重要
Using index:性能提升,索引覆盖,此查询仅查询索引不需要回表查询
Using where:该查询中使用了where条件过滤
Using index, Using where:双条件,表明索引被用来执行索引键值的查找
Using filesort:性能消耗大,需要额外一次排序(查询)
Using temporary:性能消耗大,用到临时表,常见于order by和group by
Using join buffer 连接缓存
impossible where:where子句的值总是false,不能用来获取任何元组
distinct:优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
四、索引的分类
注意:索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引
存储引擎种类:

查看当前版本存储引擎信息:

两种在实际开发中使用最多的两种引擎【MyISAM】和【InnoDB】。
MyISAM和InnoDB存储引擎:只支持BTREE索引, 也就是说默认使用BTREE,不能够更换。
MEMORY/HEAP存储引擎:支持HASH和BTREE索引。
MySQL目前主要有以下几种索引类型:
1、 普通索引
这是最基本的索引,它没有任何限制。它有以下几种创建方式:
(1)直接创建索引
CREATE INDEX index_name ON table(column(length))
(2)修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
(3)创建表的时候同时创建索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
INDEX index_name (title(length))
)
2、 唯一索引
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。它有以下几种创建方式:
(1)创建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length))
(2)修改表结构
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))
(3)创建表的时候直接指定
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
UNIQUE indexName (title(length))
);
3、 主键索引
是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一般是在建表的时候同时创建主键索引:
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) NOT NULL ,
PRIMARY KEY (`id`)
);
4、 组合索引
组合索引就是在多个字段上创建一个索引,如:
ALTER TABLE `table` ADD INDEX name_city_age (name,city,age);


最左前缀原则:只有当查询条件为name,name and city,name and city and age三种情况下才会走索引name_city_age。在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
5、全文索引
主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。fulltext索引配合match against操作使用,而不是一般的where语句加like。它可以在create table,alter table ,create index使用,不过目前只有char、varchar,text 列上可以创建全文索引。值得一提的是,在数据量较大时候,现将数据放入一个没有全局索引的表中,然后再用CREATE index创建fulltext索引,要比先为一张表建立fulltext然后再将数据写入的速度快很多。

以上就是MySQL索引的介绍,如果有不当之处或者遇到什么问题,欢迎在文章下面留言~
如果你想了解更多关于MySQL的内容,可以查看:MySQL学习目录
转载请注明:https://blog.csdn.net/weixin_44662961/article/details/106287127















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









