







超越Sora,长时1080p视频生成!清华生数推出视频大模型Vidu,开创高一致性新纪元!
Vidu: A Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models
Abstract | HTML | PDF

简介
我们推出了Vidu,一款高性能文本生成视频模型,能够在单次生成中产出时长长达16秒、分辨率为1080p的视频。Vidu基于扩散模型,采用U-ViT作为主干网络,突破了长视频生成的瓶颈,实现了卓越的可扩展性和一致性表现。它不仅能生成逼真的视频,还能产出富有想象力的内容,并对摄影技巧如转场、镜头运动、光效和情感呈现有一定的理解,其效果媲美目前最强的文本生成视频模型Sora。同时,Vidu还在可控视频生成方向进行了初步探索,包括Canny到视频、视频预测、多主体一致性生成等,均展现出令人期待的结果。
方法
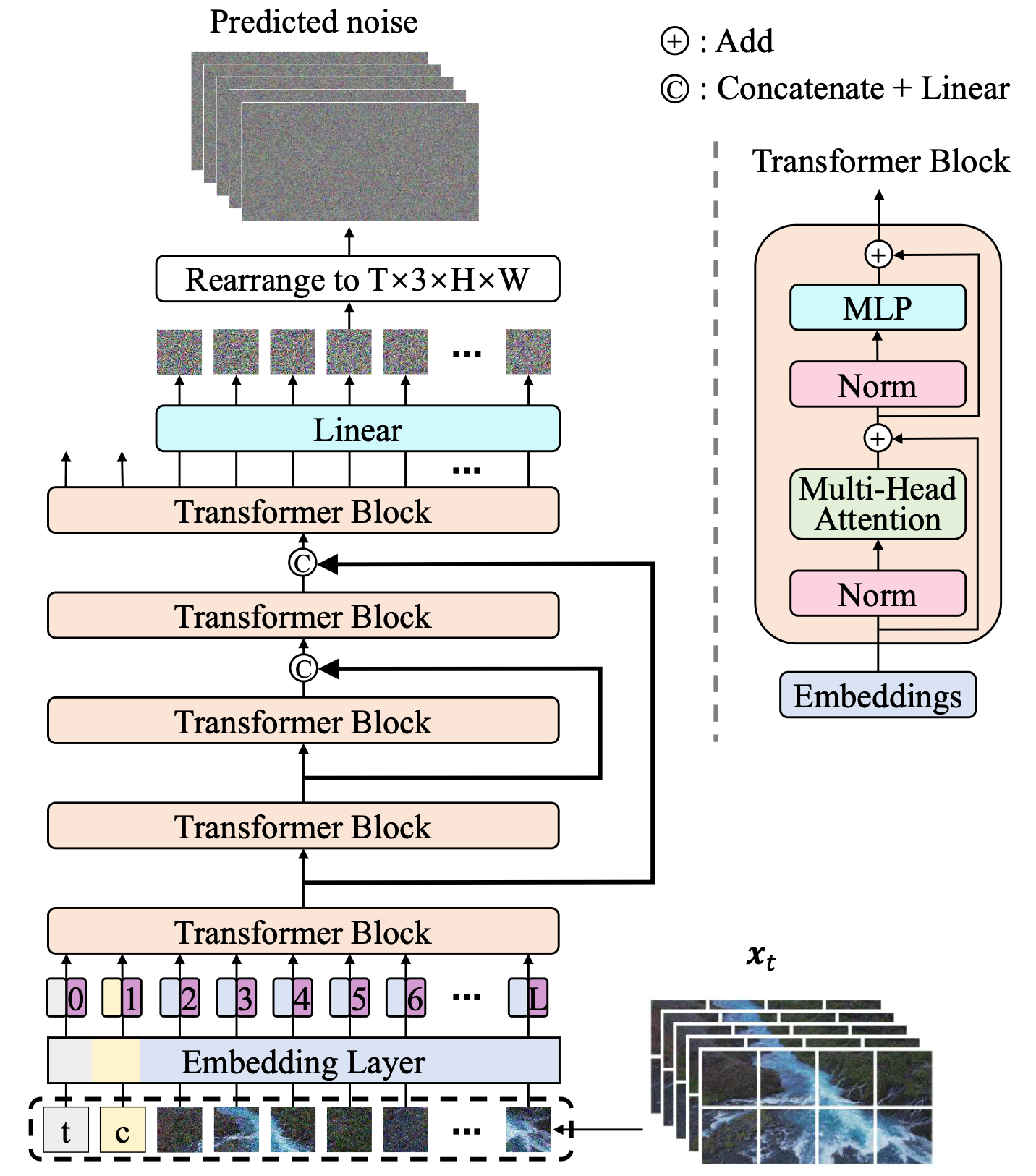
想象一下,Vidu 就像一个巧妙的魔术师,把原本复杂的视频变得既小又精简,方便后续的处理。首先,Vidu 采用了一种视频自动编码器,能够将视频的空间和时间维度进行压缩,这就好比把一个巨大的拼图重新装进一个小盒子里,这样一来,训练和推理就更加高效了。接着,Vidu 使用了一种叫做 U-ViT 的模型来进行噪声预测。U-ViT 作为整个魔术表演的核心,可以将视频分割成一个个 3D 小块(类似把拼图拆成小块),把时间信息、文本条件以及带有噪声的小块都当成积木一样的“积木块”,然后通过 Transformer 这种积木大师来组装出最终的完整视频。
U-ViT 的内部结构可以说是精妙而强大。它的基本构成包括一系列 Transformer Block,每个 Block 都像是一个聪明的助手,帮助处理视频中的各种信息。每个 Transformer Block 中都包含多头注意力机制(Multi-Head Attention),能够同时关注视频的不同部分,就像有多个聚光灯照亮整个场景中的各个细节。此外,U-ViT 还包含多层感知器(MLP),这些感知器帮助整合和加工信息,使得每个视频帧之间的关系更加紧密。
U-ViT 中的一个重要设计就是“长跳跃连接”,这种连接将浅层的特征传递到深层,确保模型能够同时利用到低层次和高层次的信息。这些跳跃连接就好像是桥梁,将模型的不同部分紧密联系在一起,使得模型在生成视频时既能保持细节,又能理解整体的动态逻辑。
在这个过程中,U-ViT 通过一些特别设计的“长跳跃连接”将浅层和深层的积木块巧妙结合起来,就像建造一座摩天大楼时用到的支撑结构,使得生成的视频更加稳定一致。因为 Transformer 擅长处理各种长度的序列,所以 Vidu 可以生成各种时长的视频,非常灵活。
Vidu 的训练数据可是海量的文本和视频对,但并不是所有的视频都有人帮忙加上描述。为了解决这个问题,我们专门训练了一个视频字幕生成器,能准确理解视频中的动态信息,自动为这些视频加上描述,这就像给无数的拼图都配上了说明书。在推理的时候,我们还用了一种叫重描述的技术,能够把用户的输入变成更适合模型理解的形式,这样 Vidu 就能更好地生成你想要的视频。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











