






场景连贯,角色统一!阿里In-Context LoRA:影视分镜、品牌设计的影像生成利器!
IN-CONTEXT LORA FOR DIFFUSION TRANSFORMERS
Abstract | HTML | PDF
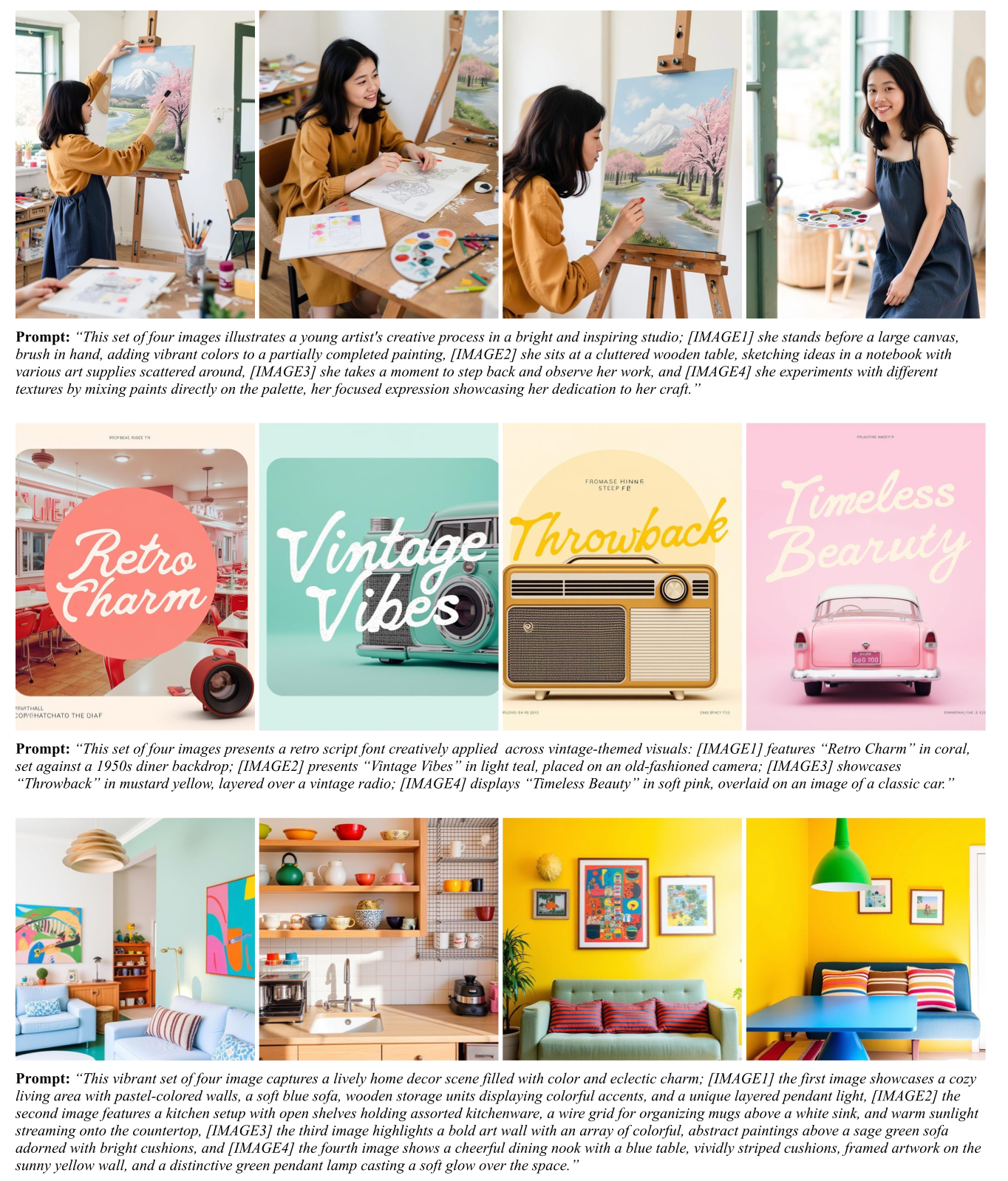
前言:让AI更“聪明”的图像生成技术
想象一下,你在设计一系列儿童绘本的插画,或者在规划一组风格统一的家居产品图片。用现在的AI工具,虽然可以通过输入文字生成单张图片,但要让这些图片保持风格一致并体现复杂的关联,比如角色的表情、动作变化或不同家具的设计统一,却非常困难。这背后是因为现有的文本生成图片技术在处理“复杂关系”的多图任务时还有局限性。为了解决这一问题,研究者们提出了一些新方法。
在这篇研究中,作者发现了一件有趣的事:现有的文本生成图片模型,其实已经悄悄具备了一种称为“上下文学习”的能力。这种能力类似于一个聪明的学生,在看过一些例子后,能够推理出更复杂的任务。作者通过一系列实验验证了这一点,并提出了一个全新的方法——上下文微调(In-Context LoRA,简称IC-LoRA),既简单又高效,能让现有模型在生成高质量图片时如虎添翼。
通过深入分析,作者得出了以下几个重要结论:
- 模型已经具备“上下文学习”能力:现有的文本生成图片模型可以在特定输入的引导下,生成符合复杂需求的图片。只需适当激活这一能力,就能完成更复杂的任务。
- 无需修改模型架构:这些模型已经非常强大,不需要对它们的设计做任何改动。只要调整输入方式,就能充分利用它们的潜力。
- 小数据集也能实现大效果:不需要成千上万的图片数据,仅用20到100组小样本,就能实现高质量的微调。这既省时又省算力。
作者提出了一种全新的方法,将复杂的图片生成任务简化为以下几步:
- 图片拼接:与以往复杂的“特征拼接”不同,这种方法直接将多张图片拼接成一张大图片。这就像将散落的拼图片拼接在一起,让模型“看清全貌”。
- 文字合并:将每张图片对应的描述合并成一条长描述,模型通过这一条“综合说明”生成多张图片,避免了以往方法中图片与描述不匹配的问题。
- 小样本微调:利用一种称为LoRA的技术,用少量数据进行微调,保留模型原有能力的同时,提升特定任务的表现。
此外,为了实现更复杂的“条件生成”(比如根据部分图片推测其他图片),作者设计了一种简单的“图片遮挡补全”策略,利用现有技术(如SDEdit)让模型完成“填空”。
前人工作一览表
| 任务类别 | 方法类别 | 发展创新 | 模型名称 | 方法详情 |
|---|---|---|---|---|
| 特定任务图像生成 | 细粒度控制方法 | 传统文本生成图像方法缺乏对具体属性(如布局、姿态、身份等)的控制能力,细粒度控制方法旨在增强模型在这些方面的可控性。 | - 布局控制:调整生成图像中物体或元素的位置和排列。 - 姿态控制:生成具有特定动作或角度的人物或物体图像。 - 身份控制:确保生成图像中人物或主体的身份特征一致性。 - 颜色/风格控制:生成符合指定调色板或风格的图像。 | |
| 区域特性编辑方法 | 让用户能够对图像的特定区域进行修改或控制,通常结合现有图像和文本描述进行编辑,满足定制化需求。 | SDEdit, Paint by Example | - 区域编辑:通过像素遮挡或调整,实现对图像中特定区域的修改。 - SDEdit:结合已有图像和噪声生成过程进行区域细粒度编辑。 - Paint by Example:使用示例图片对目标区域进行调整和融合。 | |
| 多图生成方法 | 为满足多张图片生成需求,尤其是图片间需要保持语义关联和风格一致性,提出了多图生成方法,支持复杂图像生成场景。 | Group Diffusion Transformer (GDT) | - 多图生成:支持在一次生成任务中输出多张图像,同时保持风格一致性和语义关联。 - GDT:通过拼接多个图片的注意力token实现多图生成,但生成质量仍有不足。 | |
| 任务无关图像生成 | 任务无关框架 | 为提升模型通用性,提出支持多种生成任务的统一框架,允许在不同任务中灵活切换,并扩展到跨模态生成。 | Emu Edit, Emu2, Emu3, TransFusion, OmniGen, Show-o | - Emu Edit:支持多样化图像编辑任务的框架。 - Emu2/3:整合文本、图像与视频生成能力,支持多模态生成。 - TransFusion:通过跨模态注意力机制处理不同任务输入。 - OmniGen:支持复杂场景的多任务生成模型。 |
| 无需架构修改的方法 | 通过调整输入或微调现有模型,挖掘已有模型潜力,无需重新设计模型架构,支持任务无关的高效生成,显著降低开发成本和复杂度。 | IC-LoRA | - IC-LoRA:利用现有模型的上下文学习能力,通过拼接图片和文本提示实现高质量任务无关生成,无需大规模训练或模型修改。 |
方法
问题描述
想象一下,你是一名插画师,正在接一个儿童绘本的设计任务。客户告诉你:“我要画一只小兔子从早到晚的生活场景。”他还补充说:“每一页都要有这只小兔子,保持它的外貌不变,但每一页的背景和动作需要符合不同的时间和情节。”听起来并不复杂,对吧?但如果换成是一台AI,它会怎么理解这个任务?它是否能同时掌握绘本整体风格的统一性和每一页插画的变化细节?这正是这篇论文要解决的问题:如何生成一组内在关联的图片,并确保整体与局部都符合要求。
1、任务定义:从生成单张图片到生成“图片集”
传统的文本生成图片任务往往聚焦于“给一段文字描述,生成一张图片”。举个例子,当你输入“一个穿红色裙子的女孩在海滩散步”,AI会生成一张符合这个描述的图片。然而,在现实应用中,我们常常需要生成一组图片,而这些图片之间是有内在联系的。例如:一组连环画、一整套字体设计,或者一组电影分镜图。每张图片不仅要满足各自的描述,还要与其他图片在风格、语义和细节上保持一致。
为了让AI理解这种需求,论文将图像生成任务重新定义为“生成一个图片集”:生成 ( n \geq 1 ) 张图片,这些图片可能受到另一组 ( m \geq 0 ) 张图片的条件约束,并且需要结合 ( n+m ) 条文本提示进行生成。这种任务形式非常灵活,涵盖了图像翻译(将一张图片转换成不同风格)、风格迁移(统一一组图片的视觉风格)、姿态迁移(改变人物的动作)以及基于主题的生成(让一组图片有共同的主题)等应用。
这一框架的核心在于,“图片集”中的图片不是孤立的,而是通过条件图片和文本提示保持一定的关联性,就像连环画中的每一页是同一个故事的一部分。这样,AI不仅可以生成单张图片,还可以生成具有内在逻辑和风格一致性的图片集。
2、图片之间的隐式关联:如何保持风格一致?
想象一下,你设计的绘本有五页,小兔子穿着一件蓝色外套。如果AI生成的第一页是蓝色外套,但到了第二页突然变成了绿色,是不是显得很突兀?这就说明,生成图片集时,AI必须学会维持图片之间的“隐式关联”。所谓“隐式关联”,就是图片之间的关系不需要人为显式规定,而是通过一些共同的上下文提示自然体现。
论文中提到,这种关联性主要通过“每张图片的提示”来实现。每张图片都会有一个对应的文本提示,同时这些提示会以某种方式共享信息,从而使图片之间产生内在联系。例如:
- 第一页提示:“小兔子穿着蓝色外套,在清晨的森林中散步。”
- 第二页提示:“小兔子仍然穿着蓝色外套,到了中午,它在草地上吃午餐。”
- 第三页提示:“小兔子穿着蓝色外套,黄昏时回到家中休息。”
虽然每张图片有独立的提示,但提示中的共同元素(如“蓝色外套”)会帮助模型保持一致性。这种设计保证了图片生成的灵活性和连贯性之间的平衡。
3、统一提示设计:像客户描述需求那样表达任务
论文进一步改进了提示的设计方式,引入了“统一提示设计”(Unified Prompt Design)。它的灵感来源于现实生活中客户与设计师的沟通方式。比如,客户在描述绘本需求时,往往会先提供一个总体框架:“这是一本关于小兔子一天生活的故事,风格需要温馨治愈。”然后,再为每一页具体补充细节:“第一页是清晨的小兔子,第二页是中午吃饭的小兔子,第三页是黄昏的小兔子。”
这种方法被引入到AI提示设计中:
- 首先,提供一个对整个图片集的概述性提示,定义整体风格和情感基调。比如:“这是一本儿童绘本,讲述小兔子的一天生活,风格要温馨。”
- 然后,为每张图片提供个性化的描述。比如:“图片1是小兔子在森林中散步。图片2是小兔子在草地上吃午餐。”
这种“统一提示设计”有几个显著优势:
- 保持整体风格的一致性:通过概述性提示,模型会将图片集看作一个整体,确保风格上的统一。
- 灵活应对局部变化:单张图片的提示可以包含个性化的细节描述,使得每张图片既符合全局设定,又能表现自身的特性。
- 与现有模型兼容:这种设计方式可以直接应用于现有的文本到图像生成模型,无需对模型架构进行大规模改动,十分高效。
4、现实意义:从学术框架到实际应用
论文的这种框架不仅有助于解决学术研究中的问题,还特别适合实际应用场景。比如:
- 绘本创作:帮助插画师生成一整套连贯的绘本插图。
- 字体设计:为一组字体生成统一风格但具有差异化的字形。
- 广告设计:生成一组风格一致但内容各异的宣传图片。
统一提示设计就像是为AI设计了一套“流程化的需求传递方式”,它模仿了现实中人类的沟通方式,使AI的任务执行更加自然和高效。
Group Diffusion Transformers
在这一节,论文介绍了 Group Diffusion Transformers (GDT),一种革新的图像生成模型,专门设计来同时生成一组图像,并保持这些图像之间的协调性。与传统的单图生成不同,GDT通过扩散过程中的跨图像交互,确保生成的每张图像不仅符合自身要求,还能与其他图像保持一致。以下是这一方法的几个关键技术点的解析。
1、跨图像的协作生成:扩散过程中的图像互动
传统的图像生成模型通常是针对每张图片独立进行生成,而 Group Diffusion Transformers (GDT) 采用了一个突破性的技术——跨图像的协作生成。在GDT中,所有的图像是在同一个扩散过程下生成的。这意味着,模型在生成每一张图像时,实际上是“同时”考虑了其他图像的内容。具体来说,GDT在每个 Transformer 自注意力模块 中,将不同图像的“注意力”信息串联在一起。这种设计使得每张图像都能接触到其他图像的视觉特征,并能在生成过程中与它们进行“互动”。举个例子,当你生成一组关于“海滩日落”的图像时,GDT会确保不同角度的海滩场景在色调和氛围上保持一致,而不仅仅是独立生成每一张图像。
2、文本条件的引入:如何通过文本嵌入进行引导
文本条件是GDT生成高质量图像的另一个关键。每张图像在生成时,会根据其对应的 文本嵌入 进行引导。文本嵌入是模型将文本信息转化为向量表示的过程,它使得每张图像在生成时能够“理解”文本内容的具体含义。例如,假设你给出了一组关于“秋天公园”的图像,每张图像对应的文本提示可以是“秋天的黄昏,落叶铺满小径”。GDT利用文本嵌入,使每张图像能够在生成时融入这一环境氛围的具体细节,例如通过调节光照和色彩呈现出“秋天的温暖与宁静”。
通过这种方式,GDT不仅将图像和文本绑定在一起,还保证了图像生成的精确度和多样性。每个图像都根据文本提示进行精细调节,以达到预期的视觉效果。
3、跨图像的信息共享与增强:增强图像集的内在一致性
GDT的独特之处还在于它能实现跨图像的信息共享。为了确保图像集的内在一致性,模型不仅仅关注单一图像的生成,而是通过每张图像的自注意力机制,将这些图像的信息有效传递到其他图像。例如,在生成一组人物头像时,GDT会确保每个角色在不同的图像中表现出一致的外貌特征,比如发型、服装和表情等,这样即使图像的背景、光线或动作有所变化,人物本身的特征依然是连贯的。
这种信息共享机制,仿佛是让每个图像之间通过“看见”彼此的方式进行合作,确保最终生成的图像集既具备个性,又保持整体风格的一致。
4、零-shot学习:无需额外训练的通用性
GDT在实现过程中,还融入了 零-shot学习 的理念,使得模型能够在没有额外训练的情况下,应对各种新的生成任务。通过在大量的图像集上进行训练,GDT具备了广泛的适应性。这意味着,当我们给出一组新任务(比如某种特定风格的图像生成),模型能够凭借之前学习的知识,迅速生成符合要求的图像集。这种能力大大提升了GDT的灵活性和应用范围。
这种零-shot学习能力不仅是GDT的一大优势,也代表了当前人工智能在图像生成领域的一个重要进步。它消除了每个新任务都需要重新训练模型的繁琐,使得AI能够更加高效地响应各种任务需求。
In-Context LoRA
这一小节介绍了如何通过 In-Context LoRA(低秩适应)来增强 Group Diffusion Transformers (GDT) 模型在图像生成任务中的质量,尤其是其生成效果在与传统文本到图像模型相比时的不足之处。为了提升生成质量,作者提出了激活现有模型的上下文生成能力的策略,避免了大规模训练的需要。这一技术改进的核心是通过少量数据触发模型潜在的能力,使得生成效果得到显著提升。
1、发挥现有模型的潜力:无需大规模训练
想象一下,AI模型像一个有潜力的艺术家,它已经具备一定的能力,比如画出不同风格的图画,但缺乏一些细节的雕琢。作者的核心思想是,基于现有的文本到图像模型,它们已具备一定的“上下文生成能力”,即便不经过大规模训练,模型也能根据给定的上下文描述生成多样化的图像。就像你向画家给出简单的描述,他能够理解大意并作画,只是效果可能不如预期的精致。
这也是论文中提出的一个关键点:不必为每个任务重新训练整个模型。例如,图像生成模型已经能够在接受多个面板描述后生成一组相关图像,这表明它在本质上具备某些任务适应能力。因此,作者提出通过精心设计的 小规模数据,激活和提升模型的能力,从而提高生成质量。
2、合并提示:简化图像生成任务
在图像生成任务中,通常需要为每张图片提供单独的文本提示,且每个提示都必须与相应的图像紧密关联。但这一过程往往繁琐且耗时。这里,作者通过将多个图像的提示合并为 一个统一的文本提示,来简化整个生成过程。
举个例子,假设你要生成一本书的插图,传统方法需要为每一页(图像)写一个单独的提示,而这种方法比较繁琐。现在,通过统一提示设计,你可以为整个系列图像提供一个总的背景描述,再逐一为每个面板添加必要的细节。例如:“这是一组展示小兔子一天活动的插图。第一面板:清晨,小兔子在森林中。第二面板:中午,小兔子在草地上吃午餐。”
这种方法不仅减少了生成的复杂度,还让整个生成过程更加高效。AI根据统一提示生成多个图像时,能够自动保持图像之间的一致性和内在联系,而不需要每次都为每个图像分别调整提示。这就像你给艺术家提供了整体风格和框架,剩下的部分他会根据自己的理解进行细节上的创作。
3、低秩适应(LoRA):提升上下文生成能力
接下来,为了进一步提高图像生成质量,作者提出了 低秩适应(LoRA) 技术。想象一下,你的艺术家已经非常有天赋,但你希望他在某个具体任务上更加精细和专业。你不会让他重新从头学习所有技巧,而是通过一点点有针对性的指导来帮助他提升技能。
LoRA 正是这种方法的体现。它通过对模型中的一小部分参数进行调整,使得模型能够更好地适应特定任务,避免了传统方法中对整个模型进行全面微调的麻烦。简单来说,LoRA 就是通过“低秩调整”来优化模型表现,让它能在新任务上更精准地进行图像生成。
例如,针对图像生成任务,我们并不需要大规模重新训练整个模型,而是通过少量的高质量数据来帮助模型增强其生成能力。这不仅节省了训练时间和计算资源,也能在不改变原有架构的前提下提升效果。这相当于让艺术家在不改变他的整体风格的基础上,变得更加精确和灵活。
4、SDEdit:高效的无训练图像修复inpainting(图像作为条件生成)
为了增强模型在生成任务中的灵活性,论文还提出了 SDEdit 方法,这是一种不需要额外训练的图像修复技术。想象一下,AI已经生成了一幅图像,但某些细节尚未完美,SDEdit 就像一个修图师,能够迅速对图像进行修补,完善那些缺失的部分。
具体来说,SDEdit 会把所有图像拼接成一个大的图像块,然后在这个拼接后的图像中进行修改——无论是补充缺失的部分,还是调整已有的元素。这样做的好处是,所有图像的元素在同一个空间内处理,能够保证每个面板之间的一致性,避免了独立修改时可能出现的风格不匹配或细节不统一的问题。
这个过程不需要额外的训练,因此效率非常高。通过这种方式,AI可以在同一个框架下对多个图像进行协同生成,进一步提高了生成任务的灵活性和多样性,能够处理那些需要协调不同图像元素的任务,比如多面板漫画插图或者广告系列设计。
实验
实验配置
| 实验配置项 | 详细信息 |
|---|---|
| 模型 | FLUX.1-dev 文本到图像模型 (Labs, 2024) |
| 任务范围 | 故事板生成、字体设计、肖像摄影、视觉识别设计、家居装饰、视觉特效、肖像插图、PowerPoint模板设计等 |
| 图像集大小 | 每个任务收集20到100个高质量的图像集 |
| 图像集组成 | 每个图像集被合并成一张单一的复合图像 |
| 标题生成 | 使用多模态大语言模型(MLLMs)生成图像标题 |
| 训练GPU | 单个A100 GPU |
| 训练步数 | 5,000步 |
| 批处理大小 | 4 |
| LoRA秩 | 16 |
| 推理采样步数 | 20 |
| 推理引导尺度 | 3.5(与FLUX.1-dev的蒸馏引导尺度一致) |
| 图像条件生成 | 使用SDEdit进行基于周围图像的图像修复 |
结果
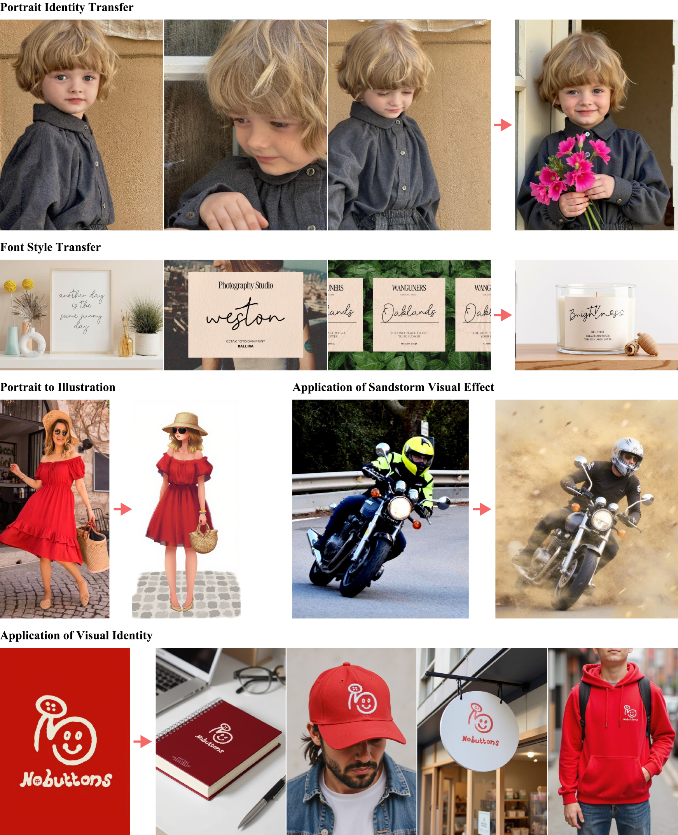
在这一部分,作者展示了其模型在多种任务下的定性结果,展示了模型在不同任务上的适应性和生成质量。由于任务的多样性,作者将统一的定量评估留待未来的工作中进行。
1、无参考图像集生成
在这种设置下,图像集完全通过文本提示生成,没有任何额外的图像输入。作者展示了多个任务的生成示例(见图4到图12),结果表明,他们的方法在各种图像集生成任务中都能产生高质量的结果。这一点非常重要,因为它证明了模型在处理不同类型的图像生成任务时的灵活性和高效性。无论是生成故事板、字体设计还是肖像插图,模型都能够根据给定的文本提示生成具有内在一致性和视觉质量的图片集。
通过这种方法,用户可以仅依赖文本输入,即便没有参考图像,依然能获得连贯且符合预期的图像集。这对于实际应用非常具有吸引力,尤其是在缺少特定参考资料时,AI能够依靠其强大的文本理解能力完成任务。


2、有参考图像集生成
在这种设置下,除了文本提示,输入还包括至少一张参考图像。图像生成过程中,使用了SDEdit技术来对部分图像进行遮罩处理,进而基于其余图像进行修复(即图像内填充)。这种方法允许通过已有的图像内容和背景信息生成新的图像,增强了生成图像的连贯性和视觉一致性。图13展示了基于图像条件的生成结果,而图14则展示了在此方法中的常见失败情况。
尽管该方法在多个任务中效果良好,生成的图像通常仍能保持高水平的一致性,但有时与仅使用文本提示生成的图像相比,图像之间的视觉一致性较低。这种不一致的原因可能与SDEdit的单向依赖关系有关,即遮罩图像与未遮罩图像之间的关系是单向的,导致生成过程中可能缺乏足够的相互调整。而使用纯文本生成时,模型允许图像之间存在双向依赖关系,即通过条件之间的互动来相互调整,从而维持图像集的一致性和质量。
这表明,在未来的研究中,可以通过引入可训练的修复方法来进一步改进这一部分。通过优化图像间的双向依赖或引入更智能的修复机制,模型在基于参考图像生成图像集时的表现有很大的提升空间。


















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











