




小红书开源StoryMaker:让图像生成中的角色与背景完美融合,个性化与一致性兼得
StoryMaker: Towards Holistic Consistent Characters in Text-to-image Generation
Abstract | HTML | PDF

前言:生成你的故事,StoryMaker 为图像赋予连贯性!
在生成图像时,我们常常希望不仅角色的面孔一致,还希望服饰、发型甚至身体特征都能保持一致。然而,现有的图像生成方法往往在多角色或复杂场景下无法实现全局的角色连贯性,难以构建出真正完整的叙事场景。
为了解决这一问题,小红书团队推出了 StoryMaker,一种创新的个性化图像生成解决方案。它不仅关注面部一致性,还在服装、发型和身体特征方面实现了全面统一。StoryMaker 能通过文本提示生成具有一致角色特征的图像序列,同时允许背景、姿势和风格多样化,使得讲述一个连贯故事变得轻松可能,StoryMaker 的技术亮点包括:
- 全局一致性控制:整合角色的面部特征、服装、发型和身体特征。
- 精准特征融合:通过“位置感知感知器重采样器(PPR)”提取和整合角色特征,避免角色间或与背景的混淆。
- 多样性与精细度兼备:通过条件化训练和专属插件(如 LoRA),实现更高质量、更灵活的图像生成。
StoryMaker 不仅在实验中表现出色,还支持角色换装、图像变化等多种应用场景,是实现个性化叙事图像的强大工具。它的开源代码已发布,未来将为创作者带来更多可能性。
前人工作一览表
| 任务类别 | 方法类别 | 模型名称 | 方法详情 |
|---|---|---|---|
| 文本驱动的图像生成 | 扩散生成方法 | DALL-E, Imagen, Stable Diffusion | - 基于扩散模型,通过逐步去噪过程生成图像。 - 支持从文本生成高度真实的图像,但在个性化生成方面有挑战。 - 无法精准处理特定人物特征和一致性问题。 |
| 主体驱动的图像生成 | 测试时微调方法 | Avrahami 等, Gal 等, Kumari 等, Ruiz 等 | - 在测试时针对特定输入进行微调,优化模型生成特定主体图像。 - 需要大量计算资源和时间来进行微调,过程相对缓慢。 - 泛化能力有限,依赖于有限的训练图像集。 |
| 无微调方法 | Ma 等, Wei 等, Xiao 等, Li 等 | - 通过视觉编码器直接融合图像信息,无需微调,提升生成效率。 - 以保持主体特征为目标,特别是面部一致性,但在整体一致性上仍有不足。 - 适用于快速生成一致性较高的图像,但细节处理存在缺陷。 | |
| 适应性模块集成方法 | Subject-Diffusion, ELITE, FastComposer, Blip-Diffusion, IP-Adapter, MoA, SSR-Encoder | - Subject-Diffusion:通过适配器模块将主体文本描述转化为图像嵌入,融入细粒度图像特征。 - ELITE、FastComposer、Blip-Diffusion:通过训练额外的网络来将图像映射到文本嵌入,从而增强生成一致性和图像质量。 - IP-Adapter:分离文本和图像特征,在跨注意力中独立处理图像特征。 - MoA:通过混合注意力机制将主体与背景分离,增强图像质量。 - SSR-Encoder:通过跨注意力将分割信息融入文本特征,提升特征提取的灵活性和选择性。 | |
| 身份一致性驱动的人像生成 | 基于ID特征提取的单一身份生成 | FaceStudio, IP-Adapter-FaceID, FlashFace, PhotoMaker | - 通过ID嵌入(如Arcface)确保面部特征的一致性,适用于精细的人脸合成应用。 - 生成高质量的人脸,特别注重面部的保真度和一致性。 |
| 引入新网络的单一身份生成 | InstantID | - 通过IdentityNet引入面部关键点控制面部结构,精确保证面部相似性。 - 强调面部特征的保持,适用于多种图像生成任务,尤其是人脸合成。 | |
| 布局驱动的多身份生成 | Wei 等, He 等, Jang 等, Avrahami 等 | - 通过跨注意力图约束确保不同主体的独立性和一致性。 - 部分方法采用预定义布局,确保每个主体的正确位置和关系,但适应性较差。 | |
| 无布局的多身份生成 | MM-diff, UniPortrait | - MM-diff:避免了预定义布局,通过跨注意力图约束实现灵活的多身份生成。 - UniPortrait:通过ID路由模块统一处理多身份,避免身份混合,适应复杂场景。 - 适合生成多个角色的自然场景,避免身份混合问题。 | |
| 故事驱动的图像生成 | 无需训练生成方法 | StoryDiffusion, ConsiStory, DreamStory | - StoryDiffusion:使用一致性自注意力机制(self-attention)确保角色在连续图像中的一致性。 - ConsiStory:采用共享注意力块(shared attention block),只从被遮挡的角色中获取信息,确保图像中的角色一致性。 - DreamStory:结合大型语言模型(LLM)来理解和引导图像生成,确保图像内容与文本描述一致。 - 适合没有明确角色参考图像的场景,如漫画和连续图像生成。 |
| 训练模块的生成方法 | OneActor, StoryMaker | - OneActor:通过簇条件生成(cluster-conditioned generation)来控制角色生成的一致性,调节适配器(adapter)来注入修改后的提示信息。 - StoryMaker:使用参考图像来提取角色特征,并通过调整适配器和位置感知重采样(Positional-aware Perceiver Resampler)来保持角色一致性。 - 适用于需要更高精度的多角色和复杂图像生成任务。 |
方法流程
StoryMaker是结构如图所示,首先通过人脸编码器提取角色的面部信息(即身份),并通过角色图像编码器提取他们的衣服、发型和身体特征。接着,我们使用提出的位置感知感知重采样器(Positional-aware Perceiver Resampler)对这些信息进行精细化处理。为了控制生成网络的核心部分,我们将处理后的信息注入到由IP-Adapter提出的解耦交叉注意力模块中。为了避免多个角色与背景相互干扰,我们对角色和背景的交叉注意力作用区域进行分别约束。此外,我们使用ID损失(ID loss)来确保角色的身份不发生改变。
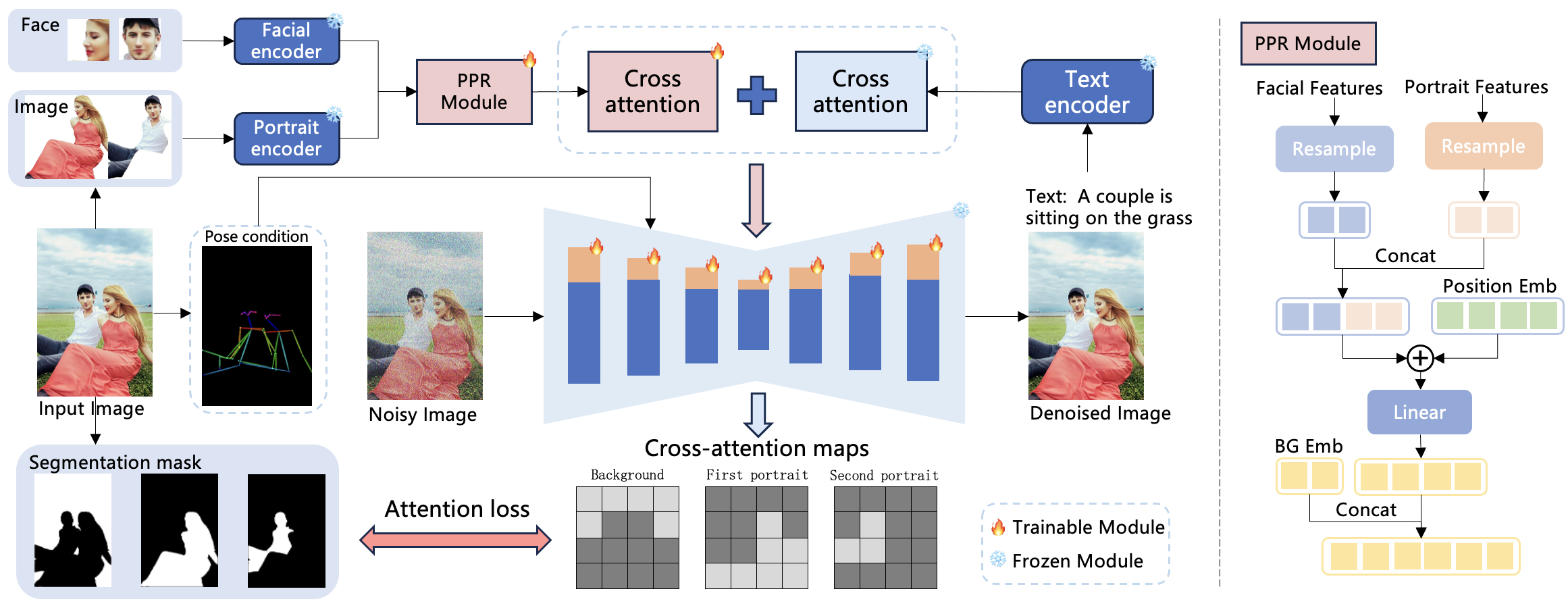
参考信息提取 (Reference Information Extraction)
这一部分的核心目标是提取图像中的面部特征,并将其用于生成一致性更强的图像。具体来说,论文通过以下两个步骤来处理参考信息:一是提取人脸特征,二是提取其他身体特征(如发型和衣物)。接下来,我们将逐步解读这一过程。
- 面部特征提取 - ArcFace人脸识别模型
首先,论文提到使用了ArcFace人脸识别模型来提取面部特征。ArcFace模型是基于深度学习的一个人脸识别模型,它能够精确地捕捉图像中的面部细节,并通过“人脸嵌入”(face embeddings)这一概念来表示人脸的特征。人脸嵌入是一种高维的向量表示,能够较好地表达面部的独特性。为了确保面部特征的提取具有一致性,论文还特别提到在提取时进行对齐处理(alignment),即对参考图像中的人脸进行标准化,使得其位置、角度等因素统一。通过这些对齐后的面部嵌入,可以提高生成图像时的面部一致性,避免不同生成图片中的人物面部差异过大。
- 发型、衣物和身体特征提取 - CLIP视觉编码器
在处理面部特征的同时,为了保持图像中其他特征的一致性,论文采用了CLIP视觉编码器来提取发型、衣服和身体等特征。CLIP是一个由OpenAI开发的多模态模型,它能够同时处理文本和图像,并从中提取丰富的内容和风格特征。使用CLIP的好处在于它具备较强的通用性,能够高效地处理各种视觉内容。在本研究中,CLIP编码器被用于提取角色的发型、衣服和身体部分的特征信息,从而确保生成的图像不仅在面部上有一致性,其他方面也能够保持统一。
- 模型训练和特征提取的稳定性
论文中提到,为了提高特征提取的稳定性,在训练过程中,ArcFace人脸编码器和CLIP编码器的参数被“冻结”。冻结参数意味着这些模型在训练过程中不会被更新,从而避免了它们的特征提取过程受到训练过程中其他部分的影响。这一策略有助于在生成图像时保持这些特征提取模块的稳定性。
接下来,我们聚焦于如何在代码中实现这一参考信息提取的过程,特别是与ArcFace和CLIP的结合使用。
- 加载预训练模型
在代码的开头,使用了from_pretrained方法加载了多个预训练模型,包括ArcFace、CLIP以及图像编码器。
image_encoder = CLIPVisionModelWithProjection.from_pretrained(args.image_encoder_path)
这里,image_encoder加载了一个CLIP视觉编码器,它负责从图像中提取视觉特征。from_pretrained方法加载了预先训练好的模型,这样就可以直接利用这些模型在特征提取任务中的优势。
- 冻结模型参数
在代码中,特意将ArcFace人脸识别模型、CLIP编码器等模型的参数冻结:
image_encoder.requires_grad_(False)
这行代码意味着,在训练过程中,image_encoder的参数不会被更新。冻结参数是为了保证特征提取过程的稳定性,避免它们受到其他模块的训练影响。
- 图像和人脸特征提取
代码还包含了针对输入图像和面部的处理逻辑。例如,使用ArcFace提取面部特征:
from arcface import get_model
facenet = get_model('r34', fp16=False)
facenet.load_state_dict(torch.load(arcface_path))
此段代码加载了一个ArcFace模型,并通过load_state_dict加载预训练的权重。这个模型在训练过程中用于提取人脸特征。
- 面部一致性损失计算
在训练过程中,通过比较生成的面部与参考图像中的面部特征的相似度,来度量生成图像与参考图像的面部一致性。
grid = F.affine_grid(face_kps_abs[i:i+1], size=[1, 3, 112, 112])
gt_face = F.grid_sample(img_gt, grid=grid, mode="bilinear", padding_mode="zeros", align_corners=False)
noise_face = F.grid_sample(noise_img, grid=grid, mode="bilinear", padding_mode="zeros", align_corners=False)
loss_id += get_each_face_and_faceid_loss(gt_face, noise_face)
参考信息的精细化处理 (Reference Information Refinement by Positional-aware Perceiver Resampler)
在这一部分,论文通过一种名为位置感知感知重采样器(Positional-aware Perceiver Resampler)的新方法来进一步优化和提升参考信息的质量,尤其是面部和角色特征的处理。论文的核心目标是将角色的各种特征(面部特征、角色特征、背景等)转换成高维的“嵌入”向量,通过细化处理让模型能更好地理解这些特征,从而在生成图像时保证更加细致、一致的结果。
1. 面部嵌入与角色嵌入的生成:
- 论文首先介绍了如何通过两个独立的重采样模块(Resampler)将面部特征和角色特征分别转换为嵌入表示。这些特征通过重采样模块处理后,变成高维的向量(即面部嵌入和角色嵌入)。
- 面部嵌入( E 1 E_1 E1)通过公式表示:
E
1
=
R
1
(
F
face
)
E_{1} = R_{1}(F_{\text{face}})
E1=R1(Fface)
其中,$ F_{\text{face}} $ 代表输入的面部特征,$ R_1 $ 是重采样模块,经过该模块,面部特征被转换成嵌入向量
E
1
E_1
E1。
- 角色嵌入( E 2 E_2 E2)的计算方法与面部嵌入类似,通过另外一个重采样模块 $ R_2 $ 处理角色特征 $ F_{\text{character}} $:
E
2
=
R
2
(
F
character
)
E_{2} = R_{2}(F_{\text{character}})
E2=R2(Fcharacter)
这里的 $ F_{\text{character}} $ 包括了角色的各种视觉特征,例如发型、衣服等。
2. 位置嵌入的引入与整合:
- 论文进一步提升了生成图像的细节和一致性,通过引入位置嵌入( E pos E_{\text{pos}} Epos)来区分角色和背景之间的空间关系。位置嵌入是一个包含空间位置信息的向量,用于帮助模型理解各个元素(如人物和背景)在图像中的相对位置。通过将面部嵌入、角色嵌入和位置嵌入进行拼接(Cat),并经过多层感知机(MLP)处理,最终得到精细化的嵌入向量:
E
i
=
MLP
(
Cat
(
E
1
,
E
2
)
+
E
pos
)
E_{i} = \text{MLP}(\text{Cat}(E_{1}, E_{2}) + E_{\text{pos}})
Ei=MLP(Cat(E1,E2)+Epos)
其中,
E
1
E_{1}
E1 和
E
2
E_{2}
E2 分别是面部和角色嵌入,
E
pos
E_{\text{pos}}
Epos 是位置嵌入。通过这种方式,模型能够在生成图像时,更加细致地表达角色间的位置差异,增强图像生成时的空间一致性。
3. 背景嵌入的处理:
- 为了进一步优化角色与背景之间的关系,论文提出了一个背景嵌入( E bg E_{\text{bg}} Ebg)。该嵌入是可学习的,并且可以与最终的嵌入进行拼接。这一策略使得模型能够区分前景角色和背景之间的不同,保证图像生成时前景与背景的关系更加自然。
- 最终,背景嵌入与其他嵌入一起,经过处理后形成了一个“交叉注意力的图像提示嵌入”,公式为:
c
i
=
Cat
(
E
bg
,
Reshape
(
E
i
,
(
N
×
L
,
D
)
)
)
c_{i} = \text{Cat}(E_{\text{bg}}, \text{Reshape}(E_{i}, (N \times L, D)))
ci=Cat(Ebg,Reshape(Ei,(N×L,D)))
这里,
N
N
N表示参考图像中的角色数,
L
L
L表示嵌入的维度,
D
D
D是每个嵌入的维度。通过将背景嵌入与最终的角色嵌入拼接,模型能够在生成过程中更好地区分背景和角色,从而产生更加和谐的图像效果。
在这一部分,论文介绍了如何通过位置感知感知重采样器(Positional-aware Perceiver Resampler)来精细化处理参考信息,特别是面部嵌入和角色嵌入的生成过程。接下来,我们将从代码角度逐步讲解这一过程。
1. 面部嵌入与角色嵌入的生成:
在代码中,面部嵌入和角色嵌入的生成是通过FacePerceiverResampler模块实现的。这个模块通过重采样方法,将输入的特征(面部特征和角色特征)转换为嵌入表示。首先,我们来看如何处理面部特征:
class FacePerceiverResampler(torch.nn.Module):
def __init__(self, embedding_dim, dim, output_dim):
super().__init__()
self.proj_in = torch.nn.Linear(embedding_dim, dim)
self.proj_out = torch.nn.Linear(dim, output_dim)
- 这段代码定义了一个输入和输出的线性变换层。
proj_in用于将输入特征(如面部特征)映射到一个新的维度,proj_out则是将变换后的特征映射回所需的输出维度。
def forward(self, latents, x):
x = self.proj_in(x)
- 这里,
forward方法中的x代表输入特征。首先,x通过proj_in映射到指定的维度。
for attn, ff in self.layers:
latents = attn(x, latents) + latents
latents = ff(latents) + latents
- 接下来,
x经过多个注意力层(attn)和前馈网络层(ff),其中每一层都会对特征进行进一步处理,并通过残差连接(+ latents)保留原始特征信息。
latents = self.proj_out(latents)
return latents
- 最后,
latents通过proj_out进行映射,得到最终的面部嵌入。
2. 位置嵌入与角色嵌入的处理:
在这一部分,位置嵌入的作用是将面部和角色的空间信息加入到嵌入中,以便在图像生成时能区分不同角色之间的位置关系。代码中使用了Cat操作将嵌入拼接,下面是如何实现的:
self.pos_embed = torch.nn.Parameter(torch.zeros(3, 4+16, cross_attention_dim)) # maxperson=3
B = clip_embeds.shape[0]
cat = torch.cat([out, clip], dim=1)+self.pos_embed[:B] # B, 20, 2048
3. 背景嵌入的处理:
为了进一步增强前景与背景的区分度,论文还引入了背景嵌入(E_bg)。在代码中,背景嵌入通常在最后与其他嵌入拼接,代码如下:
bg_embed = torch.zeros_like(self.bg_embed) if id_embeds.sum().abs() < 1e-2 else self.bg_embed
- 这行代码判断输入的
id_embeds是否接近零(即没有有效的角色信息),如果是,则将背景嵌入置为零。否则,使用预定义的背景嵌入。
res = torch.cat([self.bg_embed, res], dim=0)
- 这里,背景嵌入被拼接到最终结果中,确保背景信息能够在生成过程中起到作用。
4. 最终结果的生成与返回:
最后,所有的嵌入经过一系列处理后,通过proj_out进行线性变换,得到最终的嵌入向量。代码如下:
res = self.norm_out(self.proj_out(cat)) + cat
- 这里,
cat是将所有嵌入拼接后的结果,proj_out将其映射到指定的维度,norm_out则进行标准化,最终返回处理后的嵌入。
解耦交叉注意力(Decoupled Cross-attention)
在这部分内容中,论文提出了解耦交叉注意力(Decoupled Cross-attention)的方法,旨在将参考信息(如面部特征)有效地嵌入到文本到图像的生成模型中。该方法借鉴了IP-Adapter的思路,优化了交叉注意力机制,避免了不同类型特征之间的信息干扰。
解耦交叉注意力的基本思想:交叉注意力是一个在图像生成中常见的机制,它通过将图像的特征与文本描述中的信息进行对齐,从而在生成过程中确保图像与文本描述之间的相符。然而,传统的交叉注意力会将所有的信息混合在一起处理,这可能导致图像和文本之间的干扰,影响生成图像的一致性和精度。为了解决这一问题,论文提出了解耦交叉注意力的概念,即将不同的特征(如图像和文本特征)分开处理,避免它们之间的相互干扰。
**解耦交叉注意力的核心思想是:**文本和图像的注意力计算应该独立进行。这样,文本信息可以与文本特征进行匹配,而图像信息则可以独立地与图像特征匹配,从而避免不同模态的信息在注意力计算过程中互相影响。简而言之,解耦的过程让每种信息“独立发声”,从而使得图像和文本的生成更加精准。
1. 图像参考信息的嵌入
首先,代码中使用了一个关键的模型来嵌入参考信息,即self.image_proj_model。它接收来自多个来源的特征(如面部特征、图像特征等),并将这些特征进行合并,最终生成交叉注意力的嵌入向量。具体来说,代码如下:
ip_tokens = self.image_proj_model(faceid_embeds, image_embeds, face_embeds=face_embeds, is_training=1)# 多人ip-embeds need reshape, batchsize must be 1
这一行代码实现了图像参考信息的嵌入。faceid_embeds、image_embeds和face_embeds是输入的不同类型的特征,代表了面部特征、图像特征等信息。is_training=1则意味着这一过程是针对训练阶段进行的,模型会根据这些特征生成对应的交叉注意力嵌入。
随后,代码通过ip_tokens对嵌入向量的维度进行了重塑操作:
B, C, D = ip_tokens.shape
ip_tokens = ip_tokens.view(1, B*C, D)
这一步将ip_tokens的形状调整为(1, B*C, D),使得嵌入的特征可以适应后续模型的输入要求。这里的B、C和D分别代表批量大小、通道数和特征维度。通过这种方式,嵌入向量被有效地转换为适合网络处理的格式。
2. 嵌入向量与隐藏状态的结合
在解耦交叉注意力过程中,接下来需要将参考信息的嵌入向量与模型的隐藏状态(encoder_hidden_states)进行合并。具体的代码实现如下:
encoder_hidden_states = torch.cat([encoder_hidden_states, ip_tokens], dim=1)
这一行代码通过torch.cat将之前生成的嵌入向量ip_tokens与现有的隐藏状态encoder_hidden_states按通道维度(dim=1)进行拼接。这样一来,参考信息就能够与原始输入信息共同参与后续的生成过程。
3. 图像生成的预测
在完成嵌入和信息融合后,模型会进入生成阶段,即通过UNet(UNet2DConditionModel)模型生成最终的噪声预测。代码如下:
noise_pred = self.unet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
在这一行代码中,self.unet接受了包含参考信息的隐藏状态、噪声潜变量(noisy_latents)以及时间步长(timesteps)。此外,如果控制网络生成了残差样本,这些样本也会被传递到UNet模型中进行进一步的图像生成。最终,sample方法生成的噪声预测(noise_pred)作为图像生成的基础,完成了整个图像生成过程。
- unet的IPAttnProcessor模型块中进行解耦交叉注意力
在该模块中,首先对文本和图像信息进行单独的线性变换。具体来说,模型使用了线性变换层,分别处理文本和图像的query(查询)、key(键)和value(值)。这些层的引入,使得文本特征和图像特征能够分别以不同的方式与注意力机制进行交互。
例如,query 是通过对输入隐藏状态(hidden states)进行线性变换得到的:
query = attn.to_q(hidden_states)
这个过程不仅对原始输入的隐藏状态进行了普通的线性变换(attn.to_q),还通过LoRA层进行额外的特征变换,增加了模型对细节的捕捉能力。
- 分开处理图像和文本信息
一旦文本和图像的query、key和value分别通过LoRA变换得到,模型就可以开始进行交叉注意力的计算。为了确保图像和文本特征的解耦,模型将这两种特征的注意力计算分开进行,避免两者在计算过程中互相干扰。首先,文本特征的交叉注意力计算如下:
hidden_states = F.scaled_dot_product_attention(query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False)
然后,对于图像参考信息,模型采用另一套处理机制。通过to_k_ip和to_v_ip层,图像参考特征(如人脸嵌入等)被映射到相同的空间:
ip_key = self.to_k_ip(ip_hidden_states)
ip_value = self.to_v_ip(ip_hidden_states)
这里的ip_hidden_states代表了图像的参考信息,模型通过这些层提取图像特征并与query计算交叉注意力:
ip_hidden_states = F.scaled_dot_product_attention(query, ip_key, ip_value, attn_mask=None, dropout_p=0.0, is_causal=False)
这一操作确保了图像信息和文本信息的独立性,每种信息的交叉注意力计算是独立进行的,从而避免了信息之间的干扰。
- 合并图像和文本的注意力输出
在图像和文本的交叉注意力计算完成后,下一步是将两者的输出加权融合。这一步通过以下公式实现:
hidden_states = hidden_states + self.scale * ip_hidden_states
这里,hidden_states 是来自文本特征的注意力输出,ip_hidden_states 则是来自图像参考特征的注意力输出。两者加权后得到最终的融合结果。通过这种方式,模型能够在生成图像时同时参考图像和文本特征,同时确保它们之间的干扰降到最低。
从角色图像中解耦姿势(Pose Decoupling from Character Images)
在这一部分,论文提出了一种解耦姿势和角色图像特征的方法,主要使用了Pose-ControlNet。其目标是防止生成模型因过度依赖参考图像中的姿势,而导致生成的角色总是保持相同的姿势。为了实现这一目标,论文中设计了一个训练过程,能够将姿势信息与角色图像的其他特征解耦,从而在推理阶段提供更多的姿势控制自由。下面,我们将详细解读这一部分的代码实现。
1. 加载并准备姿势控制信息
首先,为了使用Pose-ControlNet,需要准备与姿势相关的信息。在代码中,controlnet_image存储了参考图像中的姿势数据,batch["images_ref"]是输入图像数据。此时,controlnet_image通过将参考图像转化为适合控制网络使用的格式来准备姿势信息。
controlnet_image = batch["images_ref"].to(dtype=weight_dtype)
这行代码的作用是将参考图像转换为合适的数据类型(weight_dtype),以便在后续步骤中进行处理。
2. 使用Pose-ControlNet进行姿势控制
接下来,代码通过调用Pose-ControlNet来处理姿势数据。controlnet是Pose-ControlNet模型的实例,它根据提供的controlnet_image(包含姿势信息)进行图像生成过程中的姿势调整。若controlnet存在,则会进行姿势调整。
if controlnet:
down_block_res_samples, mid_block_res_sample = controlnet(
noisy_latents,
timesteps,
encoder_hidden_states=ip_tokens,
added_cond_kwargs=added_cond_kwargs,
controlnet_cond=controlnet_image,
return_dict=False,
)
else:
down_block_res_samples, mid_block_res_sample = None, None
在这段代码中,controlnet的输入包含了噪声数据noisy_latents、时间步timesteps、以及一些额外的条件added_cond_kwargs。其中,controlnet_cond=controlnet_image将提供的姿势信息(controlnet_image)作为条件输入,用于控制生成的角色的姿势。controlnet模型会基于这些信息调整生成的图像。
3. 解耦姿势与角色特征
重要的是,Pose-ControlNet不仅仅改变角色的姿势,它还能确保角色的其他视觉特征(如面部表情、服装等)保持不变。通过这种方式,姿势和其他角色特征被解耦了,使得生成的图像能够更灵活地控制姿势,同时不影响角色的其他重要特征。
noise_pred = self.unet(
noisy_latents,
timesteps,
encoder_hidden_states=encoder_hidden_states,
added_cond_kwargs=added_cond_kwargs,
down_block_additional_residuals=None if down_block_res_samples is None else [ sample.to(dtype=weight_dtype) for sample in down_block_res_samples ],
mid_block_additional_residual=None if down_block_res_samples is None else mid_block_res_sample.to(dtype=weight_dtype),
).sample
一致性 LoRA 集成
LoRA (Low-Rank Adaptation) 是一种通过插入低秩增量参数( Δ W \Delta W ΔW)来高效优化深度学习模型的方法。在本文中,LoRA 被集成到扩散模型的每一个交叉注意力层中,目的是增强生成图像的 ID 一致性、保真度和质量。LoRA 的核心思想是冻结模型的主要参数(例如 U-Net 的权重),仅训练 Δ W \Delta W ΔW 部分,从而减少训练计算成本,同时提升模型的表达能力。接下来,结合代码,我们逐步解析其实现方式。
LoRA 的实现依赖于重构交叉注意力层的核心计算。具体来说,LoRA 为每个注意力权重(如 Q , K , V Q, K, V Q,K,V)添加了低秩的增量权重 Δ W \Delta W ΔW,使得模型可以在原始权重的基础上进行微调,而无需重新训练整个模型。
在代码中,我们首先看到 LoRA 在查询( Q Q Q)、键( K K K)和值( V V V)矩阵上定义了额外的线性变换。这部分对应于以下核心代码:
self.to_q_lora = LoRALinearLayer(hidden_size, hidden_size, rank, network_alpha)
self.to_k_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
self.to_v_lora = LoRALinearLayer(cross_attention_dim or hidden_size, hidden_size, rank, network_alpha)
这里的 LoRALinearLayer 是实现
Δ
W
\Delta W
ΔW 的关键组件。它是一个线性层,其作用是将输入特征投影到低秩子空间中。通过这种方式,我们可以高效地表示模型需要学习的特征变化,避免直接优化高维权重。
接下来是具体的公式操作,代码中对查询向量(query)、键向量(key)和值向量(value)进行了增量计算:
query = attn.to_q(hidden_states) + self.lora_scale * self.to_q_lora(hidden_states)
key = attn.to_k(encoder_hidden_states) + self.lora_scale * self.to_k_lora(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states) + self.lora_scale * self.to_v_lora(encoder_hidden_states)
这一部分的作用是将 LoRA 增量权重 ( Δ W q , Δ W k , Δ W v \Delta W_q, \Delta W_k, \Delta W_v ΔWq,ΔWk,ΔWv) 添加到原始权重 ( W q , W k , W v W_q, W_k, W_v Wq,Wk,Wv) 上,具体对应于公式:
Q
=
Z
(
W
q
+
Δ
W
q
)
Q = Z(W_q + \Delta W_q)
Q=Z(Wq+ΔWq)
K
t
=
c
t
(
W
k
t
+
Δ
W
k
t
)
K_t = c_t(W_k^t + \Delta W_k^t)
Kt=ct(Wkt+ΔWkt)
V
t
=
c
t
(
W
v
t
+
Δ
W
v
t
)
V_t = c_t(W_v^t + \Delta W_v^t)
Vt=ct(Wvt+ΔWvt)
其中, Z Z Z 是输入特征, c t c_t ct 是特征标定因子,用于调整文本模态的特征。类似地,对于图像模态,也有 K i K_i Ki 和 V i V_i Vi 的调整:
K
i
=
c
i
(
W
k
i
+
Δ
W
k
i
)
K_i = c_i(W_k^i + \Delta W_k^i)
Ki=ci(Wki+ΔWki)
V
i
=
c
i
(
W
v
i
+
Δ
W
v
i
)
V_i = c_i(W_v^i + \Delta W_v^i)
Vi=ci(Wvi+ΔWvi)
代码中,c_t 和 c_i 的实现体现在对不同模态权重的拆分处理上,从而确保文本和图像特征的交互独立性。
注意力计算的核心部分是通过点积操作来完成的。在代码中,这一部分对应于以下实现:
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
上述代码利用 torch 的内置函数完成了点积注意力的计算,其输出是与查询向量(query)对应的加权特征表示。
在计算完注意力得分后,LoRA 对输出的特征进行了投影,以确保最终的维度与模型预期一致。这部分代码如下:
hidden_states = attn.to_out[0](hidden_states) + self.lora_scale * self.to_out_lora(hidden_states)
这一部分对应于公式中的输出投影,确保经过 LoRA 增量调整后的特征可以与原始特征无缝融合。
最后,值得注意的是,LoRA 的训练仅优化增量权重 Δ W \Delta W ΔW,而冻结了主模型的所有权重。这种方法在代码中通过以下实现得以体现:
hidden_states = hidden_states + residual
hidden_states = hidden_states / attn.rescale_output_factor
通过对残差连接(residual connection)的巧妙使用,LoRA 在不改变主模型权重的情况下,实现了特征的增强。
总结来说,LoRA 的核心在于通过低秩适配器( Δ W \Delta W ΔW)优化交叉注意力层的特征计算。其实现分为增量权重定义、特征投影和注意力计算三大步骤。这种方法有效降低了训练成本,同时显著提升了图像生成模型在模态融合和特征表达上的能力。
背景和计算注意力间损失
在这一小节中,作者提出了一种方法,通过引入背景嵌入来分离前景和背景,并利用交叉注意力图的均方误差(MSE)损失来进行优化。其核心思想是在每个图像中,通过计算背景和前景的交叉注意力图,并对这些图与实际分割掩码之间的差异进行约束,提升模型的前景与背景分离效果。接下来,我们将逐个解读论文中的数学公式和代码实现,揭示它们是如何紧密结合的。
1. 背景嵌入与前景分离: 引入背景嵌入以促进前景和背景的分离
在论文中,作者提出的关键点是通过引入一个可学习的背景嵌入,将背景信息与前景信息区分开来。这一点通过以下公式进行表达:
A = ∑ k = 1 L P k A = \sum_{k=1}^L P_k A=k=1∑LPk
其中 P k P_k Pk 是每个token的注意力权重, L L L 是每个角色的token数量。公式中的 A A A 表示每个角色的交叉注意力图,模型通过将前** L L L** 个token作为背景嵌入,后续的每组 L L L 个token表示每个角色。
代码讲解:
mask_gt = mask_gt.permute(0,3,1,2)
tmp = F.interpolate(tmp, size=(lsh//dr, lsw//dr), mode='bilinear',)
mask_gt = tmp.permute(0,2,3,1)
这里的代码首先对分割掩码进行维度变换,然后使用双线性插值对掩码进行缩放。这样做的目的是为后续计算交叉注意力图时提供合适的输入尺寸。
mask_person = mask_gt.sum(dim=-1).clamp(0,1)
mask_bg = 1 - mask_person
这段代码计算前景区域(mask_person)和背景区域(mask_bg)。其中,前景区域是通过对掩码的最后一维求和得到的,背景区域则是通过反转前景掩码得到的。
2. 交叉注意力图的计算: 通过交叉注意力计算图像区域的相关性
在计算交叉注意力时,模型会首先计算每个角色的注意力图,然后通过加权求和得到每个角色的最终交叉注意力图。公式如下:
P = Softmax ( Q K T / d ) P = \text{Softmax}(QK^T / \sqrt{d}) P=Softmax(QKT/d)
其中,Q 和 K 是查询(query)和键(key),d 是它们的维度。Softmax函数用于归一化计算得到的相似度。
代码讲解:
attn_probs = unet.attn_processors[name].attn_probs # 获取注意力概率
B, tlen, attn_ls = attn_probs.shape
if attn_ls != ls:
attn_probs = attn_probs.view(B, tlen, th, tw)
attn_probs = F.interpolate(attn_probs, size=(lsh, lsw), mode='bilinear',)
这里的代码从U-Net的注意力处理器中获取注意力概率 a t t n p r o b s attn_probs attnprobs,然后根据需要调整其尺寸以匹配目标图像的尺寸。如果图像尺寸不一致,使用双线性插值将其调整为目标尺寸。
3. 计算MSE损失与分割掩码: 通过MSE损失来优化前景和背景分离
为了增强前景和背景的分离效果,论文中提出了计算交叉注意力图与分割掩码之间的均方误差损失 L a t t n \mathcal{L}_{attn} Lattn。该损失函数通过对每个角色的交叉注意力图和其对应的分割掩码计算MSE来进行优化:
L a t t n = 1 N + 1 ∑ k = 1 N + 1 ∥ A k − M k ∥ 2 2 \mathcal{L}_{attn} = \frac{1}{N+1} \sum_{k=1}^{N+1} \| A_k - M_k \|_2^2 Lattn=N+11k=1∑N+1∥Ak−Mk∥22
其中, A k A_k Ak 是第k个角色的交叉注意力图, M k M_k Mk 是其对应的分割掩码, N N N 是参考图像中的角色数量,+1 表示考虑背景。
代码讲解:
loss_ip = 0; res = []
for i, attn in enumerate(attn_list):
attn_mask = attn / 60 # 归一化处理
cur_loss = F.mse_loss(attn_mask.float(), mask_gt[:,:,:,i].float(), reduction="none")
loss_ip += cur_loss.sum() / max(mask_area, 1e-5)
这段代码计算每个角色的交叉注意力图与其对应分割掩码之间的均方误差损失。每个注意力图通过 attn/60 进行归一化处理,之后计算其与实际掩码之间的MSE。最终,将每个角色的损失加和,并通过最大化区域大小来避免除以零的错误。
if step % 1000 == 0:
print(step, i, attn_mask.min().item(), attn_mask.max().item(), [B, lsh, lsw, img_num], args.ip_attn_len, loss_ip)
每当训练步数达到1000的倍数时,代码会打印出当前的损失值以及注意力图的最小和最大值,帮助监控训练过程。
4. 计算背景的损失: 对背景区域进行MSE损失计算
在计算前景损失的同时,背景区域的损失也被计算并加入总损失中,进一步增强背景分离的效果。其背景损失计算代码如下:
if i == 0: # 顺便计算背景损失
attn_bg = attn_bg / 60
cur_loss = F.mse_loss(attn_bg.float(), mask_bg.float(), reduction="mean")
loss_ip += cur_loss
这段代码通过计算背景注意力图和背景掩码之间的MSE损失,来优化背景区域的处理。背景注意力图 a t t n b g attn_bg attnbg 经过归一化处理后,与背景掩码 m a s k b g mask_bg maskbg 进行MSE损失计算。
4.8 总体损失(Overall Loss)
在训练过程中,作者提出了一个综合的损失函数,将交叉注意力损失( L a t t n \mathcal{L}_{attn} Lattn)与扩散模型的损失( L S D \mathcal{L}_{SD} LSD)结合起来,以便优化模型的表现。这个综合损失函数如下所示:
L = L S D + λ M ∑ l = 1 M L a t t n \mathcal{L} = \mathcal{L}_{SD} + \frac{\lambda}{M} \sum_{l=1}^M \mathcal{L}_{attn} L=LSD+Mλl=1∑MLattn
其中, L \mathcal{L} L 是最终的训练目标函数, L S D \mathcal{L}_{SD} LSD 是扩散模型的损失, L a t t n \mathcal{L}_{attn} Lattn 是交叉注意力损失, M M M 是模型的层数, λ \lambda λ 是一个加权系数。
1. 扩散损失( L S D \mathcal{L}_{SD} LSD):
扩散模型是一种生成模型,它通过逐步将噪声添加到数据中,并通过训练模型去逆向推断这些噪声,从而生成数据。在训练过程中, L S D \mathcal{L}_{SD} LSD 代表的是这种逆向过程的损失函数,通常通过均方误差(MSE)来计算模型的预测与真实噪声之间的差异。
在代码中,扩散损失通常是这样计算的:
loss = F.mse_loss(noise_pred.float(), noise.float(), reduction="mean")
这段代码通过计算模型预测的噪声与真实噪声之间的均方误差,得到了扩散损失 L S D \mathcal{L}_{SD} LSD。它是训练中的主要损失部分,目标是让模型能够生成与真实噪声相匹配的预测。
2. 交叉注意力损失( L a t t n \mathcal{L}_{attn} Lattn):
交叉注意力损失是作者在前面小节中引入的损失,它的目的是对前景和背景进行更好的区分。每个角色的交叉注意力图和实际分割掩码之间的均方误差(MSE)被作为损失进行计算,从而优化模型在处理前景与背景分离方面的能力。
公式中的交叉注意力损失 L a t t n \mathcal{L}_{attn} Lattn 可以通过以下代码计算:
loss_ip = 0
for i, attn in enumerate(attn_list):
attn_mask = attn / 60
cur_loss = F.mse_loss(attn_mask.float(), mask_gt[:,:,:,i].float(), reduction="none")
loss_ip += cur_loss.sum() / max(mask_area, 1e-5)
这段代码是对每个图像的交叉注意力图进行计算,得到与实际掩码之间的损失。通过加权平均,可以得到每一层的 L a t t n \mathcal{L}_{attn} Lattn。
3. 总体损失的加权(加权系数 λ \lambda λ):
为了将扩散损失和交叉注意力损失进行有效结合,作者引入了一个加权系数 λ \lambda λ。这个系数控制着交叉注意力损失在总体损失中的比重。
公式中的 λ M \frac{\lambda}{M} Mλ 使得每个层的交叉注意力损失 L a t t n \mathcal{L}_{attn} Lattn 被平均到 M M M 层,并乘以加权系数 λ \lambda λ。通过这种方式,作者可以调节交叉注意力损失对训练的影响程度。
在代码中,最终的损失函数是通过将这两个损失函数加权求和得到的:
loss = loss + loss * mask_gt * args.mask_loss_weight # 添加掩码损失
loss = loss.mean() # 扩散损失的均值
在这段代码中,loss 包含了扩散损失和加权后的交叉注意力损失,它们会被结合在一起并参与最终的优化。具体的加权操作是通过 args.mask_loss_weight 控制的,这个权重的调整会影响交叉注意力损失对最终模型训练的贡献。
4. 总体训练目标( L \mathcal{L} L):
综合来看,最终的训练目标 L \mathcal{L} L 由两个部分组成:
- 扩散损失( L S D \mathcal{L}_{SD} LSD):这是一个标准的损失项,目标是优化模型生成噪声预测的准确性。
- 交叉注意力损失( L a t t n \mathcal{L}_{attn} Lattn):这部分损失用于优化前景和背景的分离,改善图像生成的质量。
最终的目标损失函数是将这两部分加权组合,得到以下总损失:
L = L S D + λ M ∑ l = 1 M L a t t n \mathcal{L} = \mathcal{L}_{SD} + \frac{\lambda}{M} \sum_{l=1}^M \mathcal{L}_{attn} L=LSD+Mλl=1∑MLattn
这个目标函数的意义在于平衡了生成图像的质量和分割任务的效果。通过调整 λ \lambda λ,可以控制扩散损失与交叉注意力损失之间的平衡,从而优化模型在不同任务上的表现。
实验效果
实验配置
| 实验设置项 | 详细描述 |
|---|---|
| 数据集 | - 500K 张图像:300K 张单角色图像,200K 张双角色图像。 - 使用 CogVLM([Wang et al., 2023])自动生成图像字幕。 |
| 基础模型 | 使用 Stable Diffusion XL([Rombach et al., 2022])进行训练。 |
| 面部识别模型 | 使用 buffalo_l([Deng et al., 2019])作为面部识别模型。 |
| 图像编码器 | 使用 OpenCLIP ViT-H/14([Ilharco et al., 2021])作为图像编码器。 |
| LoRA 权重 | LoRA 权重秩设置为 128。 |
| 冻结层 | 冻结基础模型的原始权重,仅训练 PPR 模块和 LoRA 权重。 |
| 权重初始化 | IP-Adapter-FaceID 和 IP-Adapter 的 resample 模块权重分别从 FaceID 和角色模型中初始化。 |
| 训练设备 | 使用 8 张 NVIDIA A100 GPU,每张 GPU 批量大小为 8。 |
| 训练步骤 | 总训练步骤 8k 步。 |
| 优化器与学习率 | - 优化器:AdamW - 学习率:前 4k 步使用 1e-4,后 4k 步使用 5e-5。 |
| λ | 设置为 0.1。 |
| 图像分辨率 | 训练图像调整为 1024×1024 分辨率。 |
| 数据增强 | - 文本描述随机丢弃 10%。 - 裁剪后的角色图像随机丢弃 5%。 |
| 推理设置 | - 采样器:使用 UniPC 采样器([Zhao et al., 2024])进行推理,步数设为 25。 - 分类器无指导:设置为 7.5。 |
评估指标
| 评估项 | 描述 |
|---|---|
| 评估设置 | 在单角色设置中进行评估,使用 40 个角色数据集,结合 FastComposer([Xiao et al., 2023])中的 20 个文本提示,每个提示生成 4 张图像。 |
| CLIP 图像相似度 (CLIP-I) | 与参考图像进行比较,评估生成图像的质量,参考 FastComposer([Xiao et al., 2023])和 MM-Diff([Wei et al., 2024])的方法。 |
| 身份保持 (Face Sim.) | 使用 buffalo_l([Deng et al., 2019])模型计算两张人脸图像之间的余弦相似度。 |
| 图像-文本相似度 (CLIP-T) | 通过 CLIP 计算图像与文本之间的相似度,评估图像和文本的匹配程度。 |
定量分析

定性分析





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











