









 本文介绍了网络爬虫的基础概念,包括其定义、类型、合法性及工作原理。探讨了Python作为爬虫开发的首选语言的原因,以及爬虫在数据时代的重要作用。
本文介绍了网络爬虫的基础概念,包括其定义、类型、合法性及工作原理。探讨了Python作为爬虫开发的首选语言的原因,以及爬虫在数据时代的重要作用。
爬虫初见
1.爬虫的定义
网络爬虫是一种按照一定规则自动抓取网络信息的程序或者脚本。简单的可以这样说,网络爬虫就是根据一定的算法实现编程开发,主要通过URL实现对数据的抓取和发掘。
在数据大时代的今天,数据的规模越来越庞大,但是数据的价值普遍偏低,为了能够从庞大的数据中获取到有价值的东西,于是延伸出了网络爬虫,数据分析等职位,而近几年的网络爬虫需求更是巨大,往往供不应求。
而对于网络爬虫而言,实际上有许多语言都可以实现,比如Java,C++,Python,但是相比较而言 Python 是一门更合适的语言,其中有许多库为我们提供了接口,我们只需要使用这些库便可以实现对数据的抓取和保存,同时对代码的重构也十分方便。
2. 爬虫的类型
爬虫根据系统结构和开发技术大致分为 4 种类型:通用网络爬虫,聚焦网络爬虫,增量式网络爬虫和深层网络爬虫。
- 通用网络爬虫
又名全网爬虫,常见的有百度,Google,必应等搜索引擎,爬行对象为一些初始的 URL 到整个网站,主要为门户站点搜索引擎和大型网站服务采集数据
- 聚焦网络爬虫
又名主题网络爬虫,是选择性的爬取根据需求的主题相关页面的网络爬虫,只爬取与主题相关的页面,不需要广泛的覆盖无关的网页。
- 增量式网络爬虫
对已下载网页采取增量式更新和只爬取新产生或者已经发生变化的网页,能够在一定程度上保证所爬取的网页尽可能是新的网页
- 深层网络爬虫
该爬虫可以通过一定的技术手段,对大部分不能通过静态 URL 获取的,隐藏在表单之后,只有用户提交后才能获得的网络页面
3. 爬虫的合法性
网络爬虫在绝大多数情况下是合法的,在生活中网络爬虫几乎都有爬虫的应用,比如搜索引擎搜索到的内容都是通过爬虫爬取到的信息,因此网络爬虫作为一门技术是不违法的,而且在很多情况下都可以放心的使用,但是如果使用爬虫来进行违法行为,但是是违法触规的,主要有以下两个:
- 利用爬虫技术与黑客技术结合,攻击网站后台,从而盗取后台数据
- 利用爬虫恶意攻击网站,造成网站系统的瘫痪
4.爬虫的工作原理
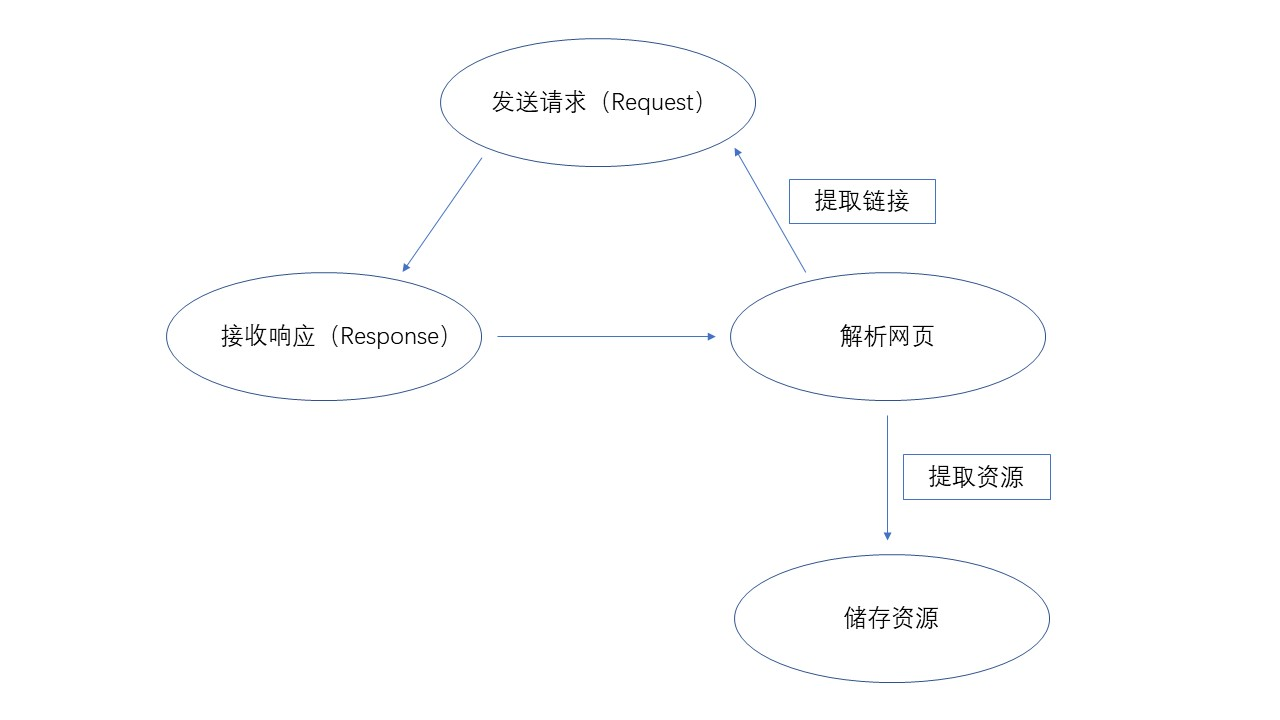
下面这张图片很好的展示了爬虫的基本原理
 1
1
主要步骤是:
- 向服务器(Web)发送请求
- 接受服务器的响应,获取对应的 html 等资源
- 对获取到的资源进行解析,并同时获取其中的链接再进行第一步(该步有时可无)
- 将解析到的资源进行存储,可以以文本形式,也可以存储到数据库中
5. 爬虫的规范
对于一个网页而言,可能拥有自己的对于爬虫的一份规定–robots协议,我们可以在一个域名后面输入robots.txt来查看对应的协议,一般而言,我们要遵循这些协议,不过如果爬虫速度访问与人差不多,也可以使用爬虫来爬取,下面是上海交通大学镜像网的 robots.txt,可在此 查看,具体内容如下:
# robots.txt for http://ftp.sjtu.edu.cn/
User-agent: *
Disallow: /logs/
Use-agent: 限定爬取的用户,在上面 * 表示所有的用户, 有时会指定特殊的用户,比如百度(Baiduspider),Google(Googlebot)等等Disallow: 表示不允许爬取的内容Allow: 表示可以爬取的内容(此案例无)
爬虫的简单介绍就到这里,下一小节具体学习如何配置相关环境

图片来源于网络 ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









