







1.1 大数据处理框架
集群环境给编程带来的挑战:
- 并行化:并行化的方式重写应用程序,为了利用更大范围节点的计算能力
- 单节点失败的处理
- 集群环境一般是被多个用户分享,动态的分配计算资源
针对集群环境出现了大量的大数据编程框架,比如MapReduce:简单通用,自动容错,批处理计算模型。缺点:不适合交互式和流式计算,因为MR不能实现在并行计算的各个阶段进行有效的数据共享!
1.2 Spark大数据处理框架
- 针对MR不能进行数据共享,提出RDD概念:一种新的抽象的弹性数据集;
- Spark不严谨的可以视为:RDD+MR
1.2.1 RDD表达能力
- 迭代算法
- 关系型查询
- MapReduce批处理
- 流式处理
1.2.2 Spark子系统
按照大数据处理场景划分,大数据处理分为下面三种:
- 复杂的批量数据处理,时间跨度为数十分钟到数小时
- 基于历史的交互式查询:时间跨度为数十秒到数分钟
- 基于实时数据流的数据处理:时间跨度为数百毫秒到数秒
下面是可以同时处理上面三种情形的统一大数据处理平台:

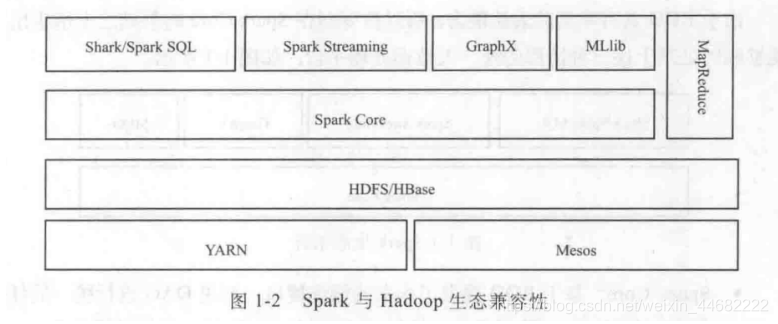
- Spark Core:基于RDD提供了丰富的操作接口,利用DAG进行统一的任务规划,使得Spark可以灵活处理类似于MR的批处理作业
- Shark/Spark SQL:兼容Hive的接口HQL
- Spark Streaming:将流式计算分解成一系列的短小的批处理作业
- GraphX:基于Spark的图计算框架
- MLlib:机器学习算法库
Spark和Hadoop生态
使用Scala编写的














 1739
1739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









