







一、项目介绍
python爬取XKCD漫画图片。XKCD是一个流行的极客漫画网站, 它的漫画内容通常是关于科学、技术、数学、计算机科学等主题的幽默漫画。如下:

使用python脚本批量性地自动下载漫画图片,可以节约大量的时间。
程序需要完成以下任务:
(1)加载XKCD主页
(2)保存该页的漫画图片
(3)转入前一张漫画的链接
(4)重复直到第一张漫画
则意味着代码需要执行以下操作:
(1)利用requests模块下载页面
(2)利用Beautiful Soup找到页面中漫画图像的URL
(3)利用iter_content()下载漫画图像,并保存到硬盘
(4)找到前一张漫画的URL链接,然后重复
二、程序设计
(1)下载网页
import requests, os, bs4
url = 'https://xkcd.tw/57' #这里我从57号图片开始,往前下载
os.makedirs('XKCD', exist_ok=True) #创建XKCD文件夹,保存图片
while not url.endswith('#'):
print('Download page %s……' % url)
res = requests.get(url) #加载页面,发送请求
res.raise_for_status() #检查响应状态码,若错误则抛出异常
soup = bs4.BeautifulSoup(res.text, 'html.parser') #解析HTML文档,提取数据
# TODO:find the URL of the comic image
# TODO: download the image
# TODO: save the image to ./XKCD
# TODO: get the prev button's url
print('Done!')(2)寻找和下载漫画图片
import requests, os, bs4
--snip--
# find the url of the comic image
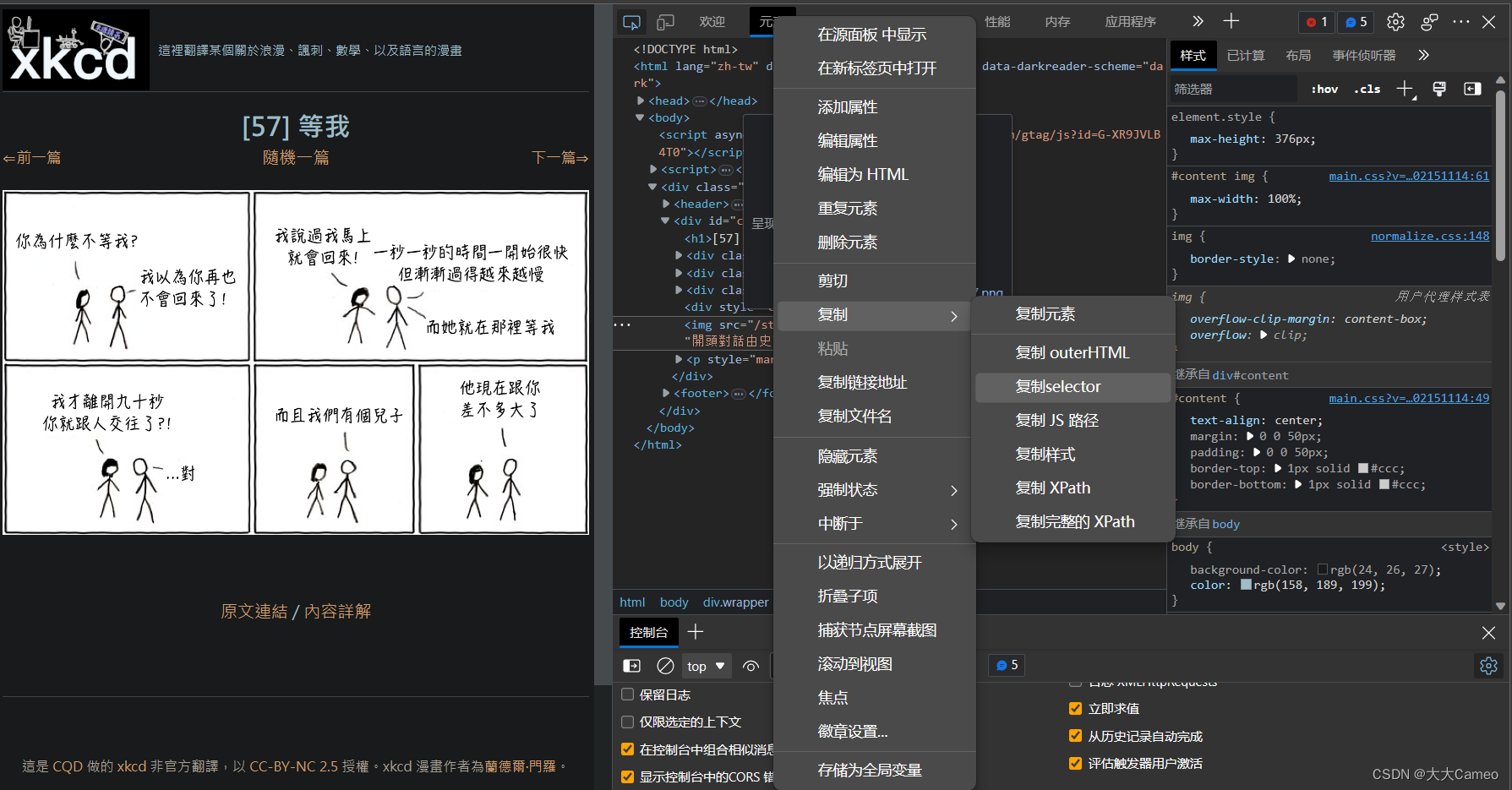
comicElem = soup.select('#content > img') #selector选择器元素定位
if comicElem == []:
print('Could not find the image')
else:
comicUrl = 'https://xkcd.tw' + comicElem[0].get('src') #漫画图片url
# Download the images
print('Download image %s……' % (comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
# save the image to ./OKCD
# get the pre button's url
print('Done!')这一步关键在于图片的元素定位,可以右键点击检查,进行如下操作:
(3)保存图像,找到前面一张漫画
import requests, os, bs4
--snip--
# save the image to ./XKCD
imageFile = open(os.path.join('OKCD', os.path.basename(comicUrl)), 'wb')#写入文件夹
for chunk in res.iter_content(100000):#将图像数据写入文件(每次10万字节)
imageFile.write(chunk)
imageFile.close()
# get the prev button's url
prevLink = soup.select('#content > div.prevLink > a')[0] #定位‘前一篇’按钮
url = 'https://xkcd.tw' + prevLink.get('href')
print('Done!')(4)完整程序
import requests, os, bs4
url = 'https://xkcd.tw/57'
os.makedirs('XKCD', exist_ok=True)
while not url.endswith('#'):
print('Download page %s……' % url)
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'html.parser')
# find the url of the comic image
comicElem = soup.select('#content > img')
if comicElem == []:
print('Could not find the image')
else:
comicUrl = 'https://xkcd.tw' + comicElem[0].get('src')
# Download the image
print('Download image %s……' % (comicUrl))
res = requests.get(comicUrl)
res.raise_for_status()
# save the image to ./XKCD
imageFile = open(os.path.join('XKCD', os.path.basename(comicUrl)), 'wb')
for chunk in res.iter_content(100000):
imageFile.write(chunk)
imageFile.close()
# get the pre button's url
prevLink = soup.select('#content > div.prevLink > a')[0]
url = 'https://xkcd.tw' + prevLink.get('href')
print('Done!')
运行截图:
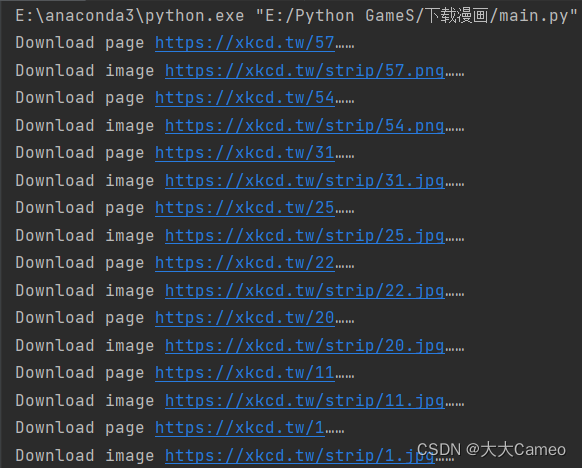
保存图片:

可以通过阅读Beautiful Soup文档,了解更多自动化数据收集和分析的功能。
最后附上一张有趣的XKCD漫画 














 7857
7857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









