







一、正则匹配规则
| ^ | 匹配字符串的开始位置 |
|---|---|
| $ | 匹配输入字符串的结束位置 |
| + | 匹配一个或者多个,表示前面的字符至少出现一次(1次或者多次) |
| * | 匹配的字符出现0次或者多次 |
| ? | 前面的字符最多只能出现一次(0次或者1次) |
| .* | 贪婪模式,匹配所有 |
| .*? | 非贪婪模式,只匹配最近的 |
二、正则匹配应用
说明:将字符串中的color值提取出来
代码如下(示例):
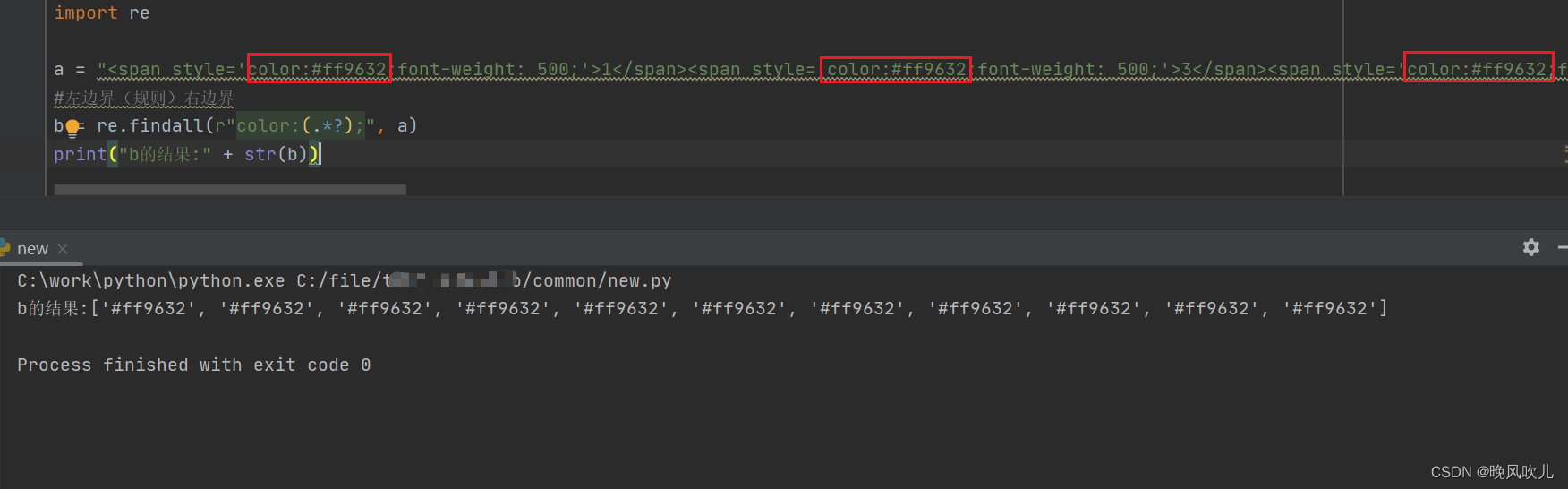
import re
a = "<span style='color:#ff9632;font-weight: 500;'>1</span><span style='color:#ff9632;font-weight: 500;'>3</span><span style='color:#ff9632;font-weight: 500;'>3</span><span style='color:#ff9632;font-weight: 500;'>2</span><span style='color:#ff9632;font-weight: 500;'>0</span><span style='color:#ff9632;font-weight: 500;'>2</span><span style='color:#ff9632;font-weight: 500;'>8</span><span style='color:#ff9632;font-weight: 500;'>5</span><span style='color:#ff9632;font-weight: 500;'>5</span><span style='color:#ff9632;font-weight: 500;'>8</span><span style='color:#ff9632;font-weight: 500;'>2</span>"
b = re.findall(r"color:(.*?);", a)
print("b的结果:" + str(b))
返回结果:















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









