







查询气温
(1)气温数据文件temperature.txt的内容
hadoop@ddai-desktop:~$ vim temperature.txt
hadoop@ddai-desktop:~$ more temperature.txt
1990 21
1990 18
1991 21
1992 30
1992 999
1990 23
(2)查找每年最高气温
grunt> copyFromLocal temperature.txt /test
grunt> records = load '/test/temperature.txt' USING PigStorage(' ')
as (year: chararray,temperature:int);
grunt> valid_records = filter records by temperature!=999;
grunt> grouped_records = group valid_records by year;
grunt> max_temperature = foreach grouped_records
generate group,MAX(valid_records.temperature);
grunt> dump max_temperature;

或者脚本来查询
hadoop@ddai-desktop:~$ vim max_temp.pig
records = load '/test/temperature.txt' USING PigStorage(' ')
as (year: chararray,temperature:int);
valid_records = filter records by temperature!=999;
grouped_records = group valid_records by year;
max_temperature = foreach grouped_records
generate group,MAX(valid_records.temperature);
dump max_temperature;
hadoop@ddai-desktop:~$ pig max_temp.pig

编写用户自定义函数
编写自定义过滤函数
打开Ecplise工具,新建“Map/Reduce Project”项目“TempFilter”,新建“IsValidTemp”类,添加jar包。

import java.io.IOException;
import org.apache.pig.FilterFunc;
import org.apache.pig.backend.executionengine.ExecException;
import org.apache.pig.data.Tuple;
public class IsValidTemp extends FilterFunc {
@Override
public Boolean exec(Tuple tuple) throws IOException {
if(tuple ==null ||tuple.size()==0)
return false;
try {
Object obj=tuple.get(0);
if (obj==null)
return false;
int temperature=(Integer)obj;
return temperature!=999;
}catch(ExecException e) {
throw new IOException(e);
}
}
}
右击“TempFilter”→“src”→“IsValidTemp”,选择“Export”→“java”→“JAR file”,输入“IsValidTemp”,导出jar包

运行自定义过滤函数包
grunt> copyFromLocal /home/hadoop/workspace/IsValidTemp.jar /test
grunt> register hdfs://ddai-master:9000/test/IsValidTemp.jar;
grunt> records = load '/test/temperature.txt' USING PigStorage(' ') as (year: chararray,temperature:int);
grunt> valid_records = filter records by IsValidTemp(temperature);
grunt> dump valid_records;

编写自定义运算函数
打开Ecplise工具,新建“Map/Reduce Project”项目“EvalTemp”,新建“EvalTemp”类,添加jar包(同上)
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
public class EvalTemp extends EvalFunc<String> {
@Override
public String exec(Tuple tuple) throws IOException {
if (tuple == null || tuple.size() == 0)
return null;
try {
Object object = tuple.get(0);
int temperature = (Integer)object;
if (temperature >= 30){
return "Hot";
}
else if(temperature >=10){
return "Moderate";
}
else {
return "Cool";
}
} catch(Exception e) {
throw new IOException(e);
}
}
}

导出EvalTemp.jar包,运行自定义运算函数包

grunt> copyFromLocal /home/hadoop/workspace/EvalTemp.jar /test
grunt> register hdfs://ddai-master:9000/test/EvalTemp.jar;
grunt> result1 = foreach valid_records generate year,temperature,EvalTemp(temperature);
grunt> dump result1;

自定义加载函数
打开Eclipse工具,新建“Map/Reduce Project”项目“WordCountLoad”,新建“WordCountLoad”类,添加jar包。(同上)
import java.io.IOException;
import java.util.List;
import java.util.ArrayList;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.pig.LoadFunc;
import org.apache.pig.backend.executionengine.ExecException;
import org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.PigSplit;
import org.apache.pig.data.BagFactory;
import org.apache.pig.data.DataBag;
import org.apache.pig.data.Tuple;
import org.apache.pig.data.TupleFactory;
public class WordCountLoad extends LoadFunc {
protected RecordReader reader;
TupleFactory tupleFactory = TupleFactory.getInstance();
BagFactory bagFactory = BagFactory.getInstance();
@Override
public InputFormat getInputFormat() throws IOException {
return new TextInputFormat();
}
@Override
public Tuple getNext() throws IOException {
try {
if (!reader.nextKeyValue()) return null;
Text value = (Text)reader.getCurrentValue();
String line = value.toString();
String[] words = line.split("\\s+");
List<Tuple> tuples = new ArrayList<Tuple>();
Tuple tuple = null;
for (String word : words) {
tuple= tupleFactory.newTuple();
tuple.append(word);
tuples.add(tuple);
}
DataBag bag = bagFactory.newDefaultBag(tuples);
Tuple result = tupleFactory.newTuple(bag);
return result;
} catch (InterruptedException e) {
throw new ExecException(e);
}
}
@Override
public void prepareToRead(RecordReader reader,PigSplit arg1) throws IOException {
this.reader = reader;
}
@Override
public void setLocation(String location, Job job) throws IOException {
FileInputFormat.setInputPaths(job,location);
}
}
导出WordCountLoad.jar包,运行自定义加载函数包

grunt> cat /input/a1.txt
hello world
grunt> cat /input/a2.txt
good hadoop
注册自定义加载包
grunt> copyFromLocal /home/hadoop/workspace/WordCountLoad.jar /test
grunt> register hdfs://ddai-master:9000/test/WordCountLoad.jar;
运行加载包
grunt> records = load 'hdfs://ddai-master:9000/input' USING WordCountLoad() as (words:bag{word: (chararray)});
grunt> dump records;

计数
grunt> flatten_records = foreach records generate flatten($0);
grunt> grouped_records = group flatten_records by words::w;
待解决bug
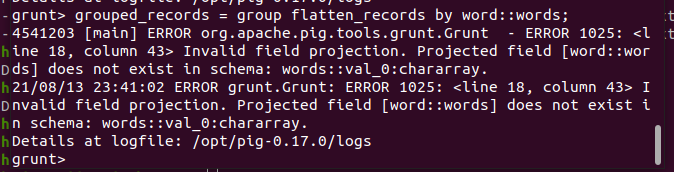
result= foreach grouped_records generate group,COUNT(flatten_records);
final_result= order result by $1 desc,$0;
dump final_result;
编写自定义函数和客户端程序
打开Eclipse工具,新建“Map/Reduce Project”项目“WordPig”,新建“WordUpper”类,添加jar包(同上)
导出WordUpper.jar包,并上传到HDFS,并测试运行
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
public class WordUpper extends EvalFunc<String> {
public String exec(Tuple input) throws IOException {
if (input == null || input.size() == 0)
return null;
try{
reporter.progress();
String str = (String)input.get(0);
return str.toUpperCase();
}catch(Exception e){
throw new IOException(e);
}
}
}
grunt> copyFromLocal /home/hadoop/workspace/WordUpper.jar /test
grunt> register hdfs://ddai-master:9000/test/WordUpper.jar;
grunt> records = load 'hdfs://ddai-master:9000/input' USING PigStorage('\n') as (line:chararray);
grunt> dump records;

grunt> result = foreach records generate WordUpper(line);
grunt> dump result;

编写客户端程序WordClient.java
hadoop@ddai-desktop:~$ vim WordClient.java
import org.apache.pig.PigServer;
public class WordClient {
public static void main(String[] args) throws Exception{
PigServer pigServer=new PigServer("mapreduce");
pigServer.registerJar("hdfs://ddai-master:9000/test/WordUpper.jar");
pigServer.registerQuery("A = load 'hdfs://ddai-master:9000/input'using PigStorage('\\n') as (line:chararray);");
pigServer.registerQuery("B = foreach A generate WordUpper(line);");
pigServer.store("B", "hdfs://ddai-master:9000/output/all");
}
}
hadoop@ddai-desktop:~$ vim w.sh
#!/bin/bash
HADOOP_HOME=/opt/hadoop-2.8.5
PIG_HOME=/opt/pig-0.17.0
CLASSPATH=.:$PIG_HOME/conf:$(hadoop classpath)
for i in ${PIG_HOME}/lib/*.jar ; do
CLASSPATH=$CLASSPATH:$i
done
CLASSPATH=$CLASSPATH:$PIG_HOME/pig-0.17.0-core-h2.jar
java -cp $CLASSPATH WordClient
运行
hadoop@ddai-desktop:~$ javac -cp /opt/pig-0.17.0/pig-0.17.0-core-h2.jar WordClient.java
hadoop@ddai-desktop:~$ sh w.sh

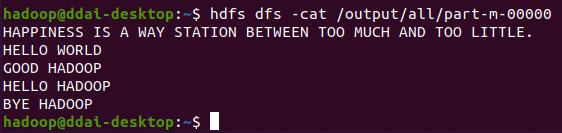
hadoop@ddai-desktop:~$ hdfs dfs -cat /output/all/part-m-00000
















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











