






1. 矩阵的乘法
矩阵乘法的定义
1. 基本定义与条件
两个矩阵相乘必须满足:
- 左矩阵的列数 = 右矩阵的行数
- 结果矩阵的维度:左矩阵的行数 × 右矩阵的列数
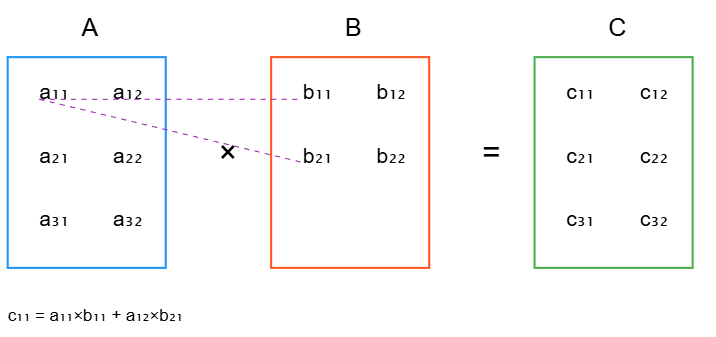
矩阵乘法的计算规则
1. 计算公式
对于矩阵 A m × n A_{m×n} Am×n 和 B n × p B_{n×p} Bn×p 的乘积 C m × p = A × B C_{m×p} = A × B Cm×p=A×B:
c i j = ∑ k = 1 n a i k b k j c_{ij} = \sum_{k=1}^n a_{ik}b_{kj} cij=k=1∑naikbkj
其中:
- c i j c_{ij} cij 是结果矩阵C中第i行第j列的元素
- a i k a_{ik} aik 是矩阵A中第i行第k列的元素
- b k j b_{kj} bkj 是矩阵B中第k行第j列的元素
2. 具体例子
假设有两个矩阵:
A = [ 1 2 3 4 ] , B = [ 5 6 7 8 ] A = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}, B = \begin{bmatrix} 5 & 6 \\ 7 & 8 \end{bmatrix} A=[1324],B=[5768]
计算步骤:
- c 11 = a 11 b 11 + a 12 b 21 = 1 × 5 + 2 × 7 = 19 c_{11} = a_{11}b_{11} + a_{12}b_{21} = 1×5 + 2×7 = 19 c11=a11b11+a12b21=1×5+2×7=19
- c 12 = a 11 b 12 + a 12 b 22 = 1 × 6 + 2 × 8 = 22 c_{12} = a_{11}b_{12} + a_{12}b_{22} = 1×6 + 2×8 = 22 c12=a11b12+a12b22=1×6+2×8=22
- c 21 = a 21 b 11 + a 22 b 21 = 3 × 5 + 4 × 7 = 43 c_{21} = a_{21}b_{11} + a_{22}b_{21} = 3×5 + 4×7 = 43 c21=a21b11+a22b21=3×5+4×7=43
- c 22 = a 21 b 12 + a 22 b 22 = 3 × 6 + 4 × 8 = 50 c_{22} = a_{21}b_{12} + a_{22}b_{22} = 3×6 + 4×8 = 50 c22=a21b12+a22b22=3×6+4×8=50
结果:
C = [ 19 22 43 50 ] C = \begin{bmatrix} 19 & 22 \\ 43 & 50 \end{bmatrix} C=[19432250]
矩阵乘法的重要性质
-
不满足交换律
- A × B ≠ B × A A×B ≠ B×A A×B=B×A (一般情况下)
- 顺序很重要
-
满足结合律
- ( A × B ) × C = A × ( B × C ) (A×B)×C = A×(B×C) (A×B)×C=A×(B×C)
- 可以改变计算顺序
-
满足分配律
- A × ( B + C ) = A × B + A × C A×(B+C) = A×B + A×C A×(B+C)=A×B+A×C
- ( B + C ) × A = B × A + C × A (B+C)×A = B×A + C×A (B+C)×A=B×A+C×A
-
单位矩阵
- A × I = I × A = A A×I = I×A = A A×I=I×A=A
- I是单位矩阵
矩阵乘法的应用场景
-
线性变换
- 旋转
- 缩放
- 反射
-
图像处理
- 图像变换
- 滤波操作
- 特征提取
-
神经网络
- 层间连接
- 权重计算
- 特征映射
-
数据分析
- 降维处理
- 特征转换
- 协方差计算
注意事项
-
计算效率
- 大矩阵乘法计算量大
- 考虑使用优化算法
- 注意内存使用
-
数值精度
- 浮点数累积误差
- 需要合适的精度控制
- 可能需要数值稳定性处理
-
特殊情况
- 稀疏矩阵的优化
- 特殊结构矩阵的简化
- 并行计算的考虑
-
错误防范
- 检查维度匹配
- 处理异常情况
- 验证计算结果
通过这些内容,我们可以看到矩阵乘法是线性代数中一个非常基础但重要的运算,在实际应用中有着广泛的用途。掌握矩阵乘法的规则和性质,对理解更复杂的数学概念和解决实际问题都很有帮助。
2. 矩阵乘法计算的思路和技巧
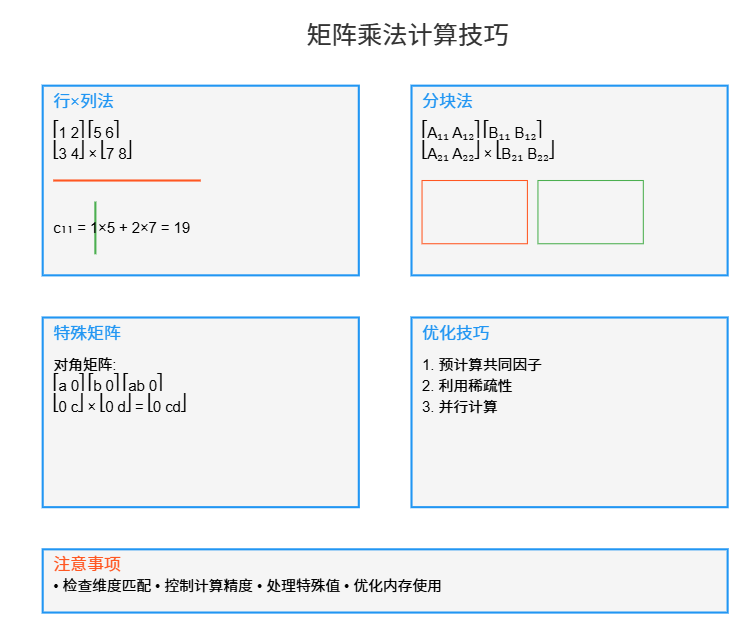
1. 基本计算思路
1.1 行×列法
- 记忆口诀:“左行右列一一对”
- 计算步骤:
- 取左矩阵的一行
- 取右矩阵的一列
- 对应元素相乘后求和
def multiply_row_col(row, col): return sum(a * b for a, b in zip(row, col))
1.2 分块法
- 适用于大型矩阵
- 将矩阵分成小块处理
[ A 11 A 12 A 21 A 22 ] × [ B 11 B 12 B 21 B 22 ] \begin{bmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{bmatrix} \times \begin{bmatrix} B_{11} & B_{12} \\ B_{21} & B_{22} \end{bmatrix} [A11A21A12A22]×[B11B21B12B22]
2. 计算技巧
2.1 心算技巧
-
找规律
- 观察相同的乘数
- 提取公因子
- 利用数字特性
-
按位分解
23 × 机制分解: 20 × 矩阵 + 3 × 矩阵 -
利用特殊值
- 0 和 1 的特性
- 对角矩阵的简化
- 单位矩阵的性质
2.2 编程技巧
# 高效的矩阵乘法实现
def matrix_multiply(A, B):
m, n = len(A), len(A[0])
n, p = len(B), len(B[0])
C = [[0] * p for _ in range(m)]
# 优化循环顺序
for i in range(m):
for k in range(n):
if A[i][k] != 0: # 跳过零元素
for j in range(p):
C[i][j] += A[i][k] * B[k][j]
return C
3. 优化策略
3.1 计算优化
-
提前计算
- 合并相同的乘积
- 预处理常用值
- 缓存中间结果
-
并行计算
- 分块并行
- GPU加速
- 多线程处理
3.2 内存优化
-
原地计算
- 避免创建临时矩阵
- 重用内存空间
- 使用迭代器
-
稀疏矩阵优化
- 只存储非零元素
- 压缩存储格式
- 专门的稀疏算法
4. 特殊情况处理
4.1 特殊矩阵
-
对角矩阵
[ a 0 0 b ] × [ c 0 0 d ] = [ a c 0 0 b d ] \begin{bmatrix} a & 0 \\ 0 & b \end{bmatrix} \times \begin{bmatrix} c & 0 \\ 0 & d \end{bmatrix} = \begin{bmatrix} ac & 0 \\ 0 & bd \end{bmatrix} [a00b]×[c00d]=[ac00bd] -
三角矩阵
- 利用零元素减少计算
- 保持三角形状
4.2 数值稳定性
-
精度控制
def safe_multiply(a, b, precision=1e-10): result = a * b if abs(result) < precision: return 0 return result -
溢出处理
- 检查数值范围
- 使用适当的数据类型
- 处理特殊值
5. 常见错误避免
-
维度检查
def check_dimensions(A, B): if len(A[0]) != len(B): raise ValueError("矩阵维度不匹配") -
零除处理
- 检查除数
- 设置阈值
- 异常处理
-
边界条件
- 空矩阵
- 单元素矩阵
- 非方阵
掌握这些思路和技巧可以帮助我们:
6. 提高计算效率
7. 减少计算错误
8. 优化程序性能
9. 处理特殊情况
在实际应用中,应根据具体问题选择合适的计算方法和优化策略。
3. 图像滤波器的实现与优化
1. 案例背景
我们正在开发一个图像处理系统,需要实现多种滤波器(如模糊、锐化等)来处理医疗图像。关键需求:
- 支持不同大小的滤波核
- 实时处理高分辨率图像
- 保证数值精确度
- 优化内存使用
import numpy as np
from scipy import signal
import cv2
from typing import List, Tuple, Union
class ImageFilter:
def __init__(self):
# 预定义常用的滤波核
self.kernels = {
'blur_3x3': np.ones((3, 3)) / 9,
'blur_5x5': np.ones((5, 5)) / 25,
'sharpen': np.array([
[0, -1, 0],
[-1, 5, -1],
[0, -1, 0]
]),
'edge_detect': np.array([
[-1, -1, -1],
[-1, 8, -1],
[-1, -1, -1]
])
}
def optimize_kernel(self, kernel: np.ndarray) -> np.ndarray:
"""优化滤波核的数值稳定性"""
# 归一化处理
if np.abs(kernel.sum()) > 1e-10:
kernel = kernel / kernel.sum()
# 处理数值精度
kernel[np.abs(kernel) < 1e-10] = 0
return kernel
def pad_image(self,
image: np.ndarray,
kernel_size: Tuple[int, int],
mode: str = 'reflect') -> np.ndarray:
"""对图像进行填充"""
pad_h = kernel_size[0] // 2
pad_w = kernel_size[1] // 2
return np.pad(
image,
((pad_h, pad_h), (pad_w, pad_w)),
mode=mode
)
def apply_filter_optimized(self,
image: np.ndarray,
kernel: np.ndarray,
batch_size: int = 1000) -> np.ndarray:
"""优化的滤波器应用函数"""
# 参数检查
if image.ndim != 2:
raise ValueError("仅支持单通道图像")
# 优化滤波核
kernel = self.optimize_kernel(kernel)
kernel_h, kernel_w = kernel.shape
# 填充图像
padded_image = self.pad_image(image, kernel.shape)
# 准备输出
result = np.zeros_like(image)
h, w = image.shape
# 分批处理以优化内存使用
for i in range(0, h, batch_size):
batch_end = min(i + batch_size, h)
batch_result = np.zeros((batch_end - i, w))
# 对每个批次应用滤波器
for j in range(i, batch_end):
for k in range(w):
# 提取图像块
block = padded_image[j:j+kernel_h, k:k+kernel_w]
# 应用滤波器
batch_result[j-i, k] = np.sum(block * kernel)
result[i:batch_end] = batch_result
return result
def apply_filter_parallel(self,
image: np.ndarray,
kernel: np.ndarray) -> np.ndarray:
"""并行化的滤波器应用函数"""
from concurrent.futures import ThreadPoolExecutor
import multiprocessing
def process_chunk(chunk_data):
chunk, kernel = chunk_data
return signal.convolve2d(chunk, kernel, mode='valid')
# 分割图像为多个块
num_cores = multiprocessing.cpu_count()
chunks = np.array_split(image, num_cores)
# 并行处理每个块
with ThreadPoolExecutor(max_workers=num_cores) as executor:
chunk_results = list(executor.map(
process_chunk,
[(chunk, kernel) for chunk in chunks]
))
# 合并结果
return np.vstack(chunk_results)
def apply_multiple_filters(self,
image: np.ndarray,
kernels: List[np.ndarray]) -> List[np.ndarray]:
"""应用多个滤波器"""
results = []
for kernel in kernels:
if image.shape[0] * image.shape[1] > 1000000: # 大图像使用并行处理
filtered = self.apply_filter_parallel(image, kernel)
else:
filtered = self.apply_filter_optimized(image, kernel)
results.append(filtered)
return results
# 使用示例
def process_medical_image(image_path: str) -> dict:
# 初始化滤波器
image_filter = ImageFilter()
# 读取图像
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 应用多个滤波器
kernels = [
image_filter.kernels['blur_5x5'],
image_filter.kernels['sharpen'],
image_filter.kernels['edge_detect']
]
# 处理图像
results = image_filter.apply_multiple_filters(image, kernels)
# 返回处理结果
return {
'blurred': results[0],
'sharpened': results[1],
'edges': results[2]
}
# 性能评估
def evaluate_performance(image_path: str) -> dict:
import time
filter_obj = ImageFilter()
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
kernel = filter_obj.kernels['blur_5x5']
# 测试优化版本
start_time = time.time()
result_opt = filter_obj.apply_filter_optimized(image, kernel)
opt_time = time.time() - start_time
# 测试并行版本
start_time = time.time()
result_parallel = filter_obj.apply_filter_parallel(image, kernel)
parallel_time = time.time() - start_time
return {
'optimized_time': opt_time,
'parallel_time': parallel_time,
'speed_up': opt_time / parallel_time if parallel_time > 0 else 0
}
2. 为什么选用矩阵乘法
-
数学基础
- 卷积操作可以转化为矩阵乘法
- 便于并行化处理
- 优化手段丰富
-
性能优势
- 可以利用硬件加速
- 内存访问连续
- 便于向量化
-
灵活性
- 支持不同大小的滤波核
- 易于扩展新的滤波器
- 便于组合多个操作
3. 使用矩阵乘法的思路和技巧
-
数据预处理
def preprocess_image(image): # 归一化 image = image.astype(np.float32) / 255.0 # 填充边界 return np.pad(image, pad_width=1, mode='reflect') -
优化策略
- 使用滑动窗口
- 分块处理大图像
- 利用稀疏性质
-
内存管理
- 使用生成器处理大图像
- 重用中间结果
- 及时释放内存
4. 完整使用过程
-
初始化阶段
# 创建滤波器实例 filter_obj = ImageFilter() # 准备滤波核 kernel = filter_obj.kernels['blur_5x5'] kernel = filter_obj.optimize_kernel(kernel) -
处理阶段
# 处理单张图像 result = filter_obj.apply_filter_optimized(image, kernel) # 批量处理 results = filter_obj.apply_multiple_filters(image, kernels) -
结果验证
# 检查结果质量 if np.any(np.isnan(result)): raise ValueError("结果包含无效值") # 保存结果 cv2.imwrite("filtered_image.png", result)
5. 使用注意事项
- 数值稳定性
def ensure_stability(kernel):
# 检查和处理数值稳定性
if np.abs(kernel.sum()) > 1e-10:
kernel = kernel / kernel.sum()
return kernel
- 边界处理
- 选择适当的填充方式
- 处理特殊边界情况
- 避免边缘伪影
- 性能优化
- 使用适当的批处理大小
- 根据图像大小选择算法
- 监控内存使用
- 错误处理
def safe_filter(image, kernel):
try:
result = apply_filter(image, kernel)
if not np.isfinite(result).all():
raise ValueError("结果包含无限值")
return result
except Exception as e:
logging.error(f"滤波器应用失败: {e}")
return None
- 资源管理
- 及时释放大型数组
- 使用上下文管理器
- 控制并行度
通过这个案例,我们可以看到:
15. 矩阵乘法在图像处理中的实际应用
16. 如何优化大规模计算
17. 如何处理实际工程中的各种问题
这种实现方式既保证了计算效率,又维持了代码的可维护性和扩展性。在处理大规模医疗图像时,特别要注意数值精度和性能优化。
4. 用户-物品评分预测系统
1. 案例背景
我们在开发一个电商推荐系统,需要:
- 预测用户对未购买商品的可能评分
- 处理大规模稀疏评分数据
- 实时生成个性化推荐
- 支持冷启动场景
import numpy as np
from scipy.sparse import csr_matrix
from typing import Dict, List, Tuple
import pandas as pd
class MatrixFactorizationRecommender:
def __init__(self,
n_factors: int = 50,
learning_rate: float = 0.01,
regularization: float = 0.02,
n_epochs: int = 20):
self.n_factors = n_factors
self.learning_rate = learning_rate
self.regularization = regularization
self.n_epochs = n_epochs
self.user_factors = None
self.item_factors = None
self.user_bias = None
self.item_bias = None
self.global_bias = None
def fit(self,
ratings: pd.DataFrame,
user_col: str = 'user_id',
item_col: str = 'item_id',
rating_col: str = 'rating') -> None:
"""训练模型"""
# 构建用户和物品的映射
self.user_map = {uid: idx for idx, uid
in enumerate(ratings[user_col].unique())}
self.item_map = {iid: idx for idx, iid
in enumerate(ratings[item_col].unique())}
n_users = len(self.user_map)
n_items = len(self.item_map)
# 初始化模型参数
np.random.seed(42)
self.user_factors = np.random.normal(0, 0.1, (n_users, self.n_factors))
self.item_factors = np.random.normal(0, 0.1, (n_items, self.n_factors))
self.user_bias = np.zeros(n_users)
self.item_bias = np.zeros(n_items)
self.global_bias = ratings[rating_col].mean()
# 转换数据格式
rating_data = [(self.user_map[row[user_col]],
self.item_map[row[item_col]],
row[rating_col])
for _, row in ratings.iterrows()]
# 训练模型
self._optimize(rating_data)
def _optimize(self, rating_data: List[Tuple[int, int, float]]) -> None:
"""优化模型参数"""
for epoch in range(self.n_epochs):
np.random.shuffle(rating_data)
epoch_loss = 0
for user_idx, item_idx, rating in rating_data:
# 计算预测评分
predicted = self._predict_single(user_idx, item_idx)
error = rating - predicted
# 计算梯度
user_vector = self.user_factors[user_idx]
item_vector = self.item_factors[item_idx]
# 更新用户和物品向量
self.user_factors[user_idx] += self.learning_rate * (
error * item_vector - self.regularization * user_vector
)
self.item_factors[item_idx] += self.learning_rate * (
error * user_vector - self.regularization * item_vector
)
# 更新偏置项
self.user_bias[user_idx] += self.learning_rate * (
error - self.regularization * self.user_bias[user_idx]
)
self.item_bias[item_idx] += self.learning_rate * (
error - self.regularization * self.item_bias[item_idx]
)
epoch_loss += error ** 2
# 打印训练进度
if (epoch + 1) % 5 == 0:
print(f"Epoch {epoch + 1}, Loss: {epoch_loss:.4f}")
def _predict_single(self, user_idx: int, item_idx: int) -> float:
"""预测单个评分"""
prediction = self.global_bias
prediction += self.user_bias[user_idx]
prediction += self.item_bias[item_idx]
prediction += np.dot(self.user_factors[user_idx],
self.item_factors[item_idx])
return prediction
def recommend_items(self,
user_id: int,
n_items: int = 10,
exclude_rated: bool = True) -> List[Tuple[int, float]]:
"""为用户推荐物品"""
if user_id not in self.user_map:
return self._recommend_popular_items(n_items)
user_idx = self.user_map[user_id]
# 计算所有物品的预测评分
predictions = np.dot(self.item_factors,
self.user_factors[user_idx]) + \
self.item_bias + \
self.user_bias[user_idx] + \
self.global_bias
# 获取推荐物品
item_scores = [(iid, predictions[idx])
for iid, idx in self.item_map.items()]
item_scores.sort(key=lambda x: x[1], reverse=True)
return item_scores[:n_items]
def _recommend_popular_items(self, n_items: int) -> List[Tuple[int, float]]:
"""推荐热门物品(用于冷启动)"""
item_avg_scores = self.item_bias + self.global_bias
item_scores = [(iid, item_avg_scores[idx])
for iid, idx in self.item_map.items()]
item_scores.sort(key=lambda x: x[1], reverse=True)
return item_scores[:n_items]
def evaluate(self,
test_ratings: pd.DataFrame,
user_col: str = 'user_id',
item_col: str = 'item_id',
rating_col: str = 'rating') -> Dict[str, float]:
"""评估模型性能"""
predictions = []
actuals = []
for _, row in test_ratings.iterrows():
if row[user_col] in self.user_map and row[item_col] in self.item_map:
user_idx = self.user_map[row[user_col]]
item_idx = self.item_map[row[item_col]]
pred = self._predict_single(user_idx, item_idx)
predictions.append(pred)
actuals.append(row[rating_col])
# 计算评估指标
rmse = np.sqrt(np.mean(np.array(predictions) - np.array(actuals)) ** 2)
mae = np.mean(np.abs(np.array(predictions) - np.array(actuals)))
return {
'rmse': rmse,
'mae': mae
}
# 使用示例
def run_recommendation_system():
# 准备示例数据
ratings_data = pd.DataFrame({
'user_id': [1, 1, 2, 2, 3],
'item_id': [1, 2, 2, 3, 3],
'rating': [5, 3, 4, 5, 1]
})
# 初始化并训练模型
recommender = MatrixFactorizationRecommender(n_factors=20)
recommender.fit(ratings_data)
# 为用户生成推荐
user_id = 1
recommendations = recommender.recommend_items(user_id, n_items=5)
print(f"\nTop 5 recommendations for user {user_id}:")
for item_id, score in recommendations:
print(f"Item {item_id}: Predicted rating = {score:.2f}")
# 评估模型
test_data = pd.DataFrame({
'user_id': [1, 3],
'item_id': [3, 1],
'rating': [4, 2]
})
metrics = recommender.evaluate(test_data)
print("\nModel performance:")
for metric, value in metrics.items():
print(f"{metric}: {value:.4f}")
if __name__ == "__main__":
run_recommendation_system()
2. 为什么选用矩阵乘法
-
数学表示优势
- 用户-物品评分可以自然表示为矩阵
- 矩阵分解可以发现潜在特征
- 便于处理稀疏数据
-
计算效率
- 可以利用并行计算
- 适合大规模数据处理
- 预测速度快
-
模型特性
- 可解释性强
- 易于扩展
- 支持增量更新
3. 使用矩阵乘法的思路和技巧
-
数据预处理
def preprocess_ratings(ratings_df): # 转换为稀疏矩阵 users = ratings_df['user_id'].values items = ratings_df['item_id'].values ratings = ratings_df['rating'].values return csr_matrix((ratings, (users, items))) -
矩阵分解优化
- 使用随机梯度下降
- 添加正则化项
- 处理缺失值
-
预测优化
- 批量预测
- 缓存中间结果
- 使用向量化操作
4. 完整使用过程
-
数据准备
# 加载评分数据 ratings = pd.read_csv('ratings.csv') # 划分训练集和测试集 train, test = train_test_split(ratings, test_size=0.2) -
模型训练
# 初始化并训练模型 recommender = MatrixFactorizationRecommender() recommender.fit(train) -
生成推荐
# 为用户生成推荐 user_recommendations = recommender.recommend_items(user_id)
5. 使用注意事项
- 内存管理
def batch_predict(self, users, batch_size=1000):
predictions = []
for i in range(0, len(users), batch_size):
batch = users[i:i+batch_size]
batch_pred = self._predict_batch(batch)
predictions.extend(batch_pred)
return predictions
- 数值稳定性
- 处理评分范围
- 归一化特征向量
- 控制学习率
- 冷启动处理
def handle_cold_start(self, user_id):
if user_id not in self.user_features:
return self.popular_items
return self.recommend_items(user_id)
- 性能优化
- 使用稀疏矩阵存储
- 实现增量更新
- 优化预测计算
这个案例与上一个图像处理案例的主要区别在于:
- 应用领域
- 本案例:推荐系统
- 上一案例:图像处理
- 数据特征
- 本案例:稀疏评分矩阵
- 上一案例:密集图像数据
- 算法重点
- 本案例:矩阵分解和预测
- 上一案例:卷积操作
- 优化方向
- 本案例:处理稀疏性和冷启动
- 上一案例:提高卷积效率
通过这个案例,我们可以看到矩阵乘法在推荐系统中的重要应用,以及如何处理大规模稀疏数据的挑战。特别是在处理用户-物品交互数据时,矩阵运算提供了高效且可扩展的解决方案。


















 950
950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











