






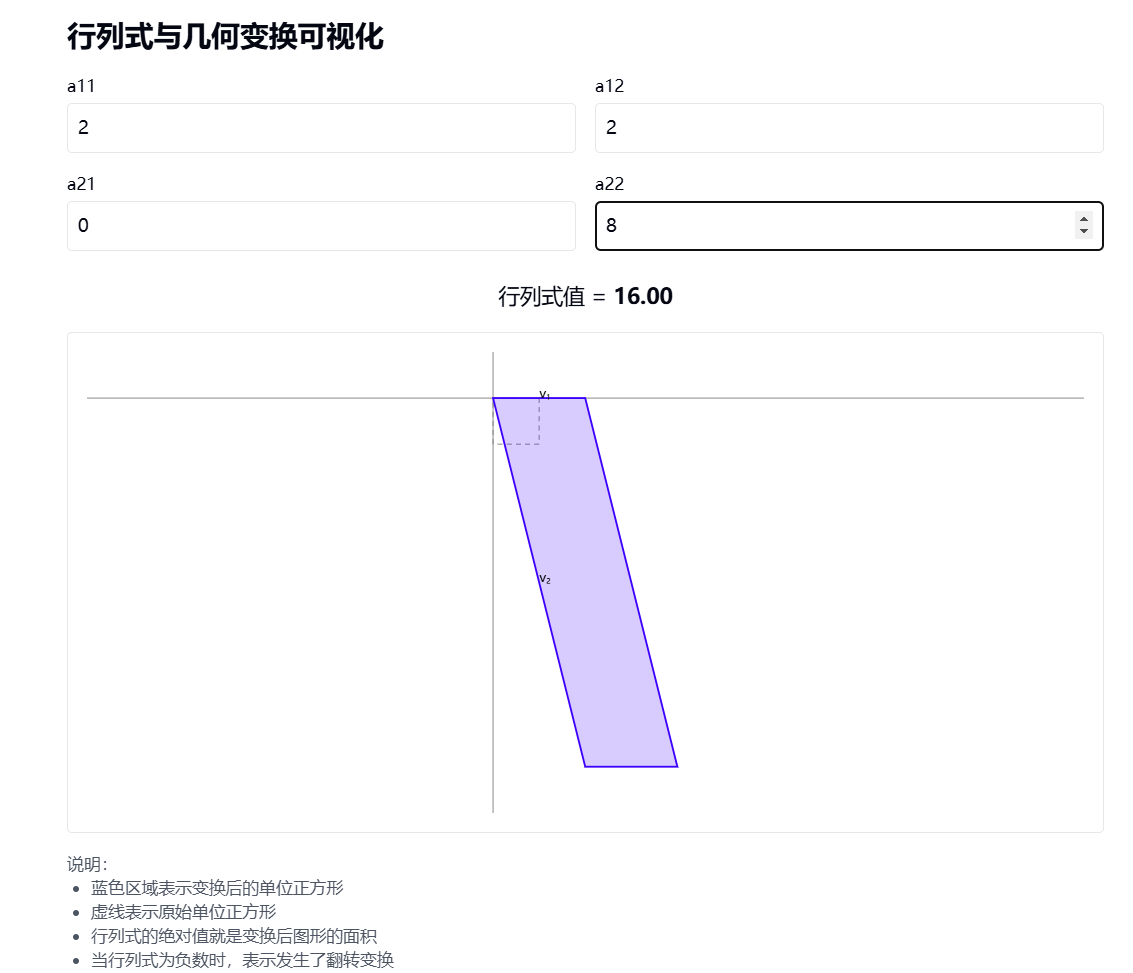
1. 二维行列式的意义
对于2×2矩阵 A = ( a 11 a 12 a 21 a 22 ) \begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix} (a11a21a12a22)
这两个向量是:
- v₁ = ( a 11 , a 21 ) (a_{11}, a_{21}) (a11,a21) (第一列向量)
- v₂ = ( a 12 , a 22 ) (a_{12}, a_{22}) (a12,a22) (第二列向量)
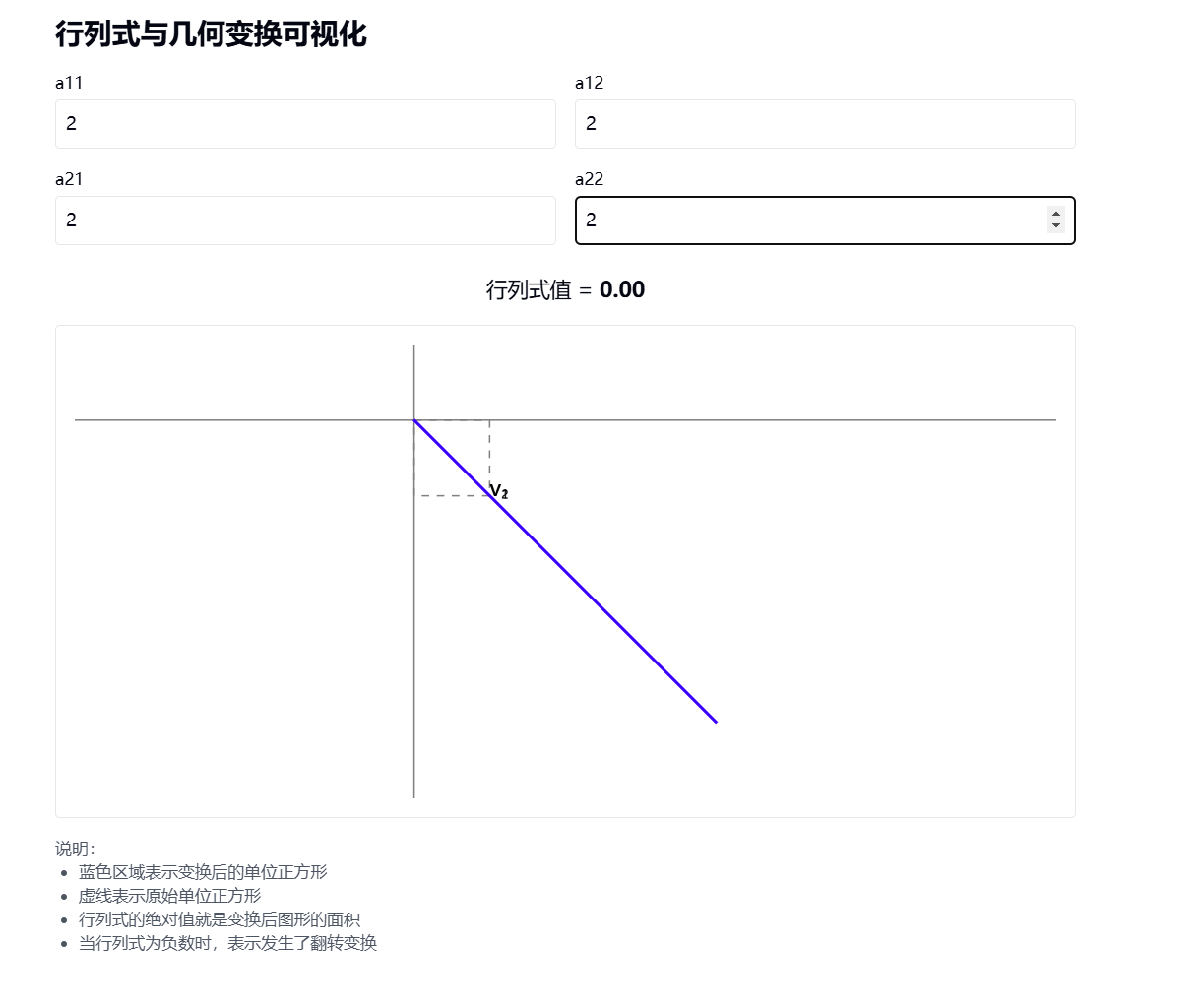
行列式的绝对值 |det(A)| = |a_{11}a_{22} - a_{12}a_{21}| 正好等于这两个向量围成的平行四边形的面积。
我们可以通过叉积(cross product)来理解这一点:
- 两个向量围成的平行四边形面积 = v₁和v₂的叉积的长度
- |v₁ × v₂| = |a_{11}a_{22} - a_{12}a_{21}|


2. 为什么二维行列式会取列向量? 而不是行向量?
- 列向量视角(最常用):
A = [a11 a12]
[a21 a22]
- 第一列向量 v₁ = (a11, a21)
- 第二列向量 v₂ = (a12, a22)
- 这表示基向量的变换:把单位向量 e₁=(1,0) 变成 v₁,把 e₂=(0,1) 变成 v₂
- 行列式 = v₁和v₂围成的面积
- 行向量视角:
A = [a11 a12]
[a21 a22]
- 第一行向量 w₁ = (a11, a12)
- 第二行向量 w₂ = (a21, a22)
- 这表示坐标变换:一个点 (x,y) 在新基下的坐标
- 行列式值相同!因为 |A| = a11a22 - a12a21
让我创建一个可视化来展示这两种视角的等价性:
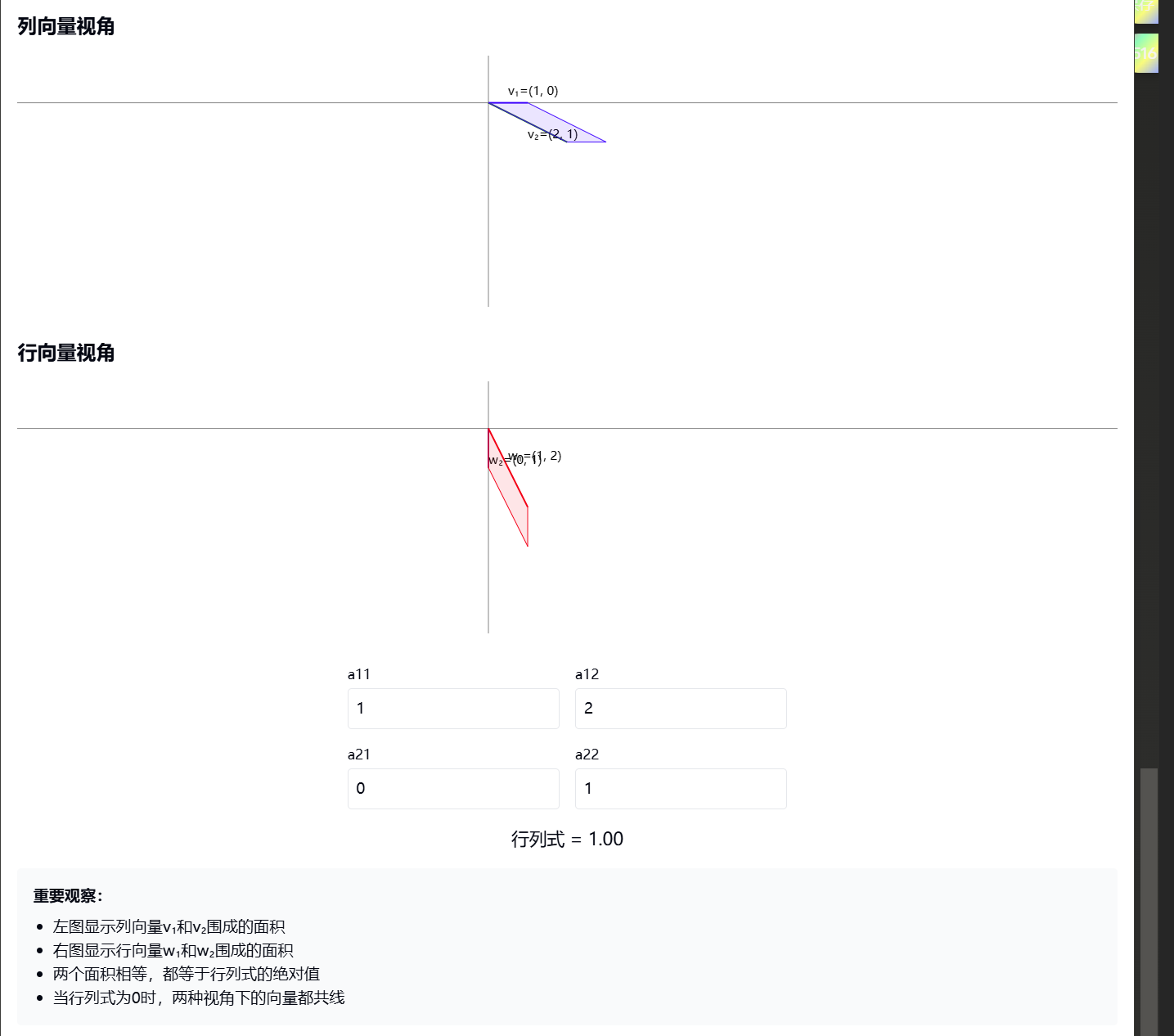

这个新的可视化展示了重要的几点:
-
列向量观点(左图):
- 展示了矩阵如何变换基向量
- v₁ = (a11, a21) 是第一列
- v₂ = (a12, a22) 是第二列
- 蓝色区域表示面积
-
行向量观点(右图):
- 展示了坐标变换的视角
- w₁ = (a11, a12) 是第一行
- w₂ = (a21, a22) 是第二行
- 红色区域表示面积
-
关键性质:
- 两种视角下计算出的行列式值相同
- |det(A)| = |a11a22 - a12a21|
- 当行列式为0时,两种视角下的向量都会共线
选择用哪种视角主要取决于具体应用场景:
- 在研究线性变换时,列向量视角更自然
- 在研究坐标变换时,行向量视角可能更直观
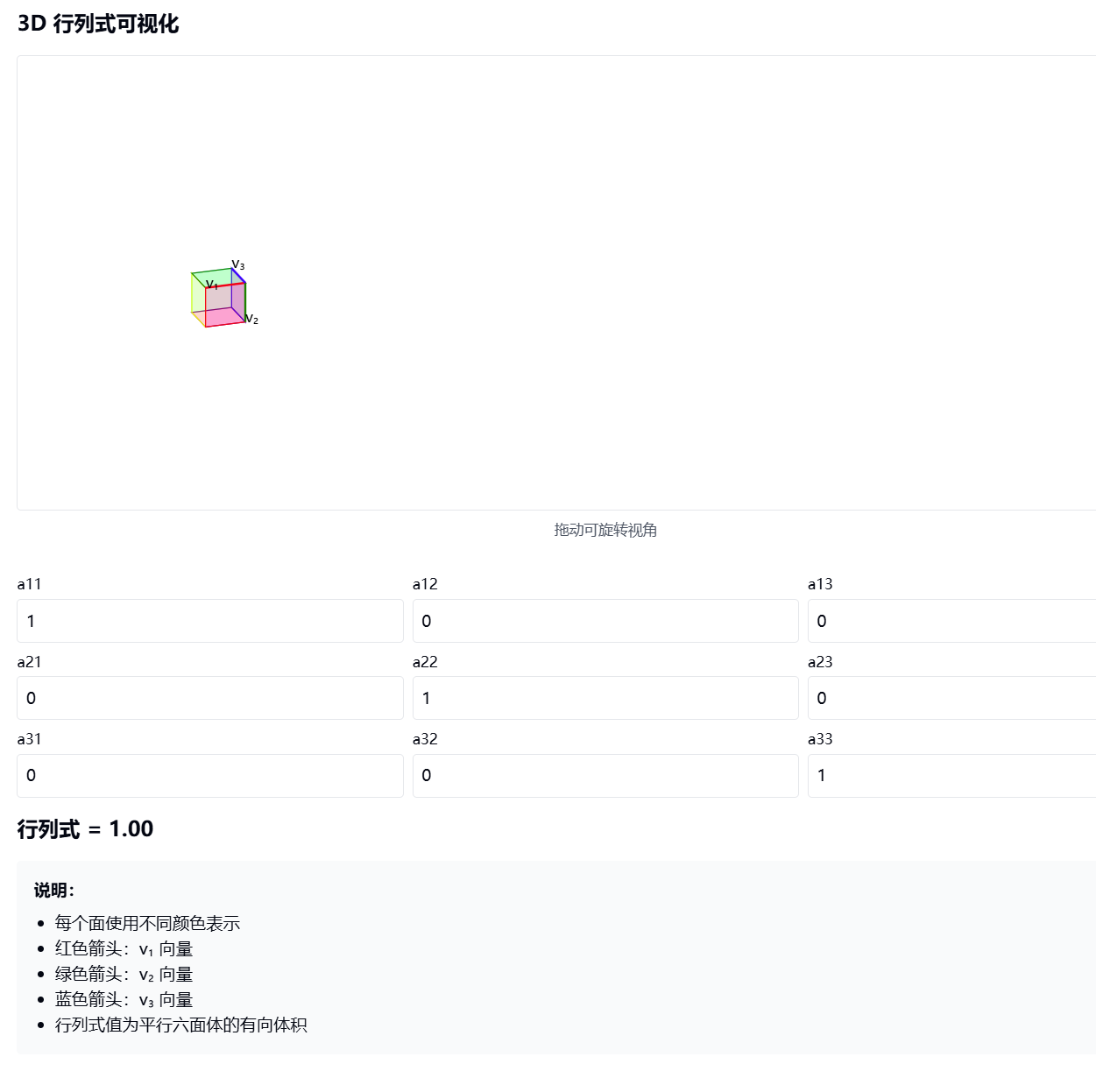
3. 三维矩阵的行列式的意义
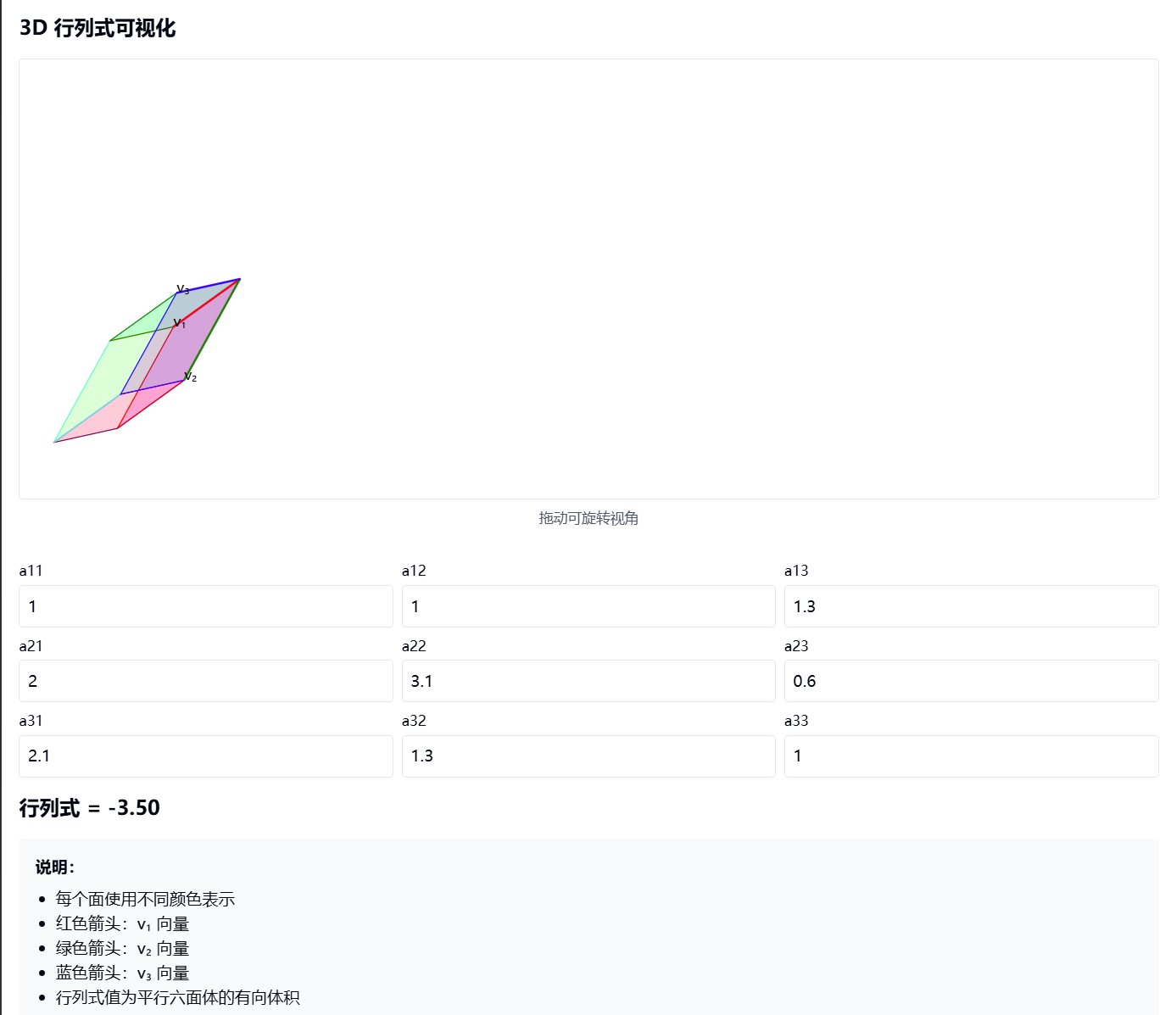
-
基本概念:
- 三维行列式是由三个向量 v₁, v₂, v₃ 围成的平行六面体的有向体积
- v₁ = (a11, a21, a31) 第一列向量
- v₂ = (a12, a22, a32) 第二列向量
- v₃ = (a13, a23, a33) 第三列向量
-
几何意义:
- |det(A)| = 平行六面体的体积
- det(A) > 0:三个向量构成右手系
- det(A) < 0:三个向量构成左手系
- det(A) = 0:三个向量共面或共线(体积为0)
-
计算公式:
det(A) = a11(a22a33 - a23a32)
- a12(a21a33 - a23a31)
+ a13(a21a32 - a22a31)
4. 案例背景:图像人脸识别中的特征提取
假设我们有一个人脸图像数据集,每张图片是64×64像素的灰度图,我们需要进行特征提取和降维来提高识别效率。
让我详细解释这个案例的各个方面:
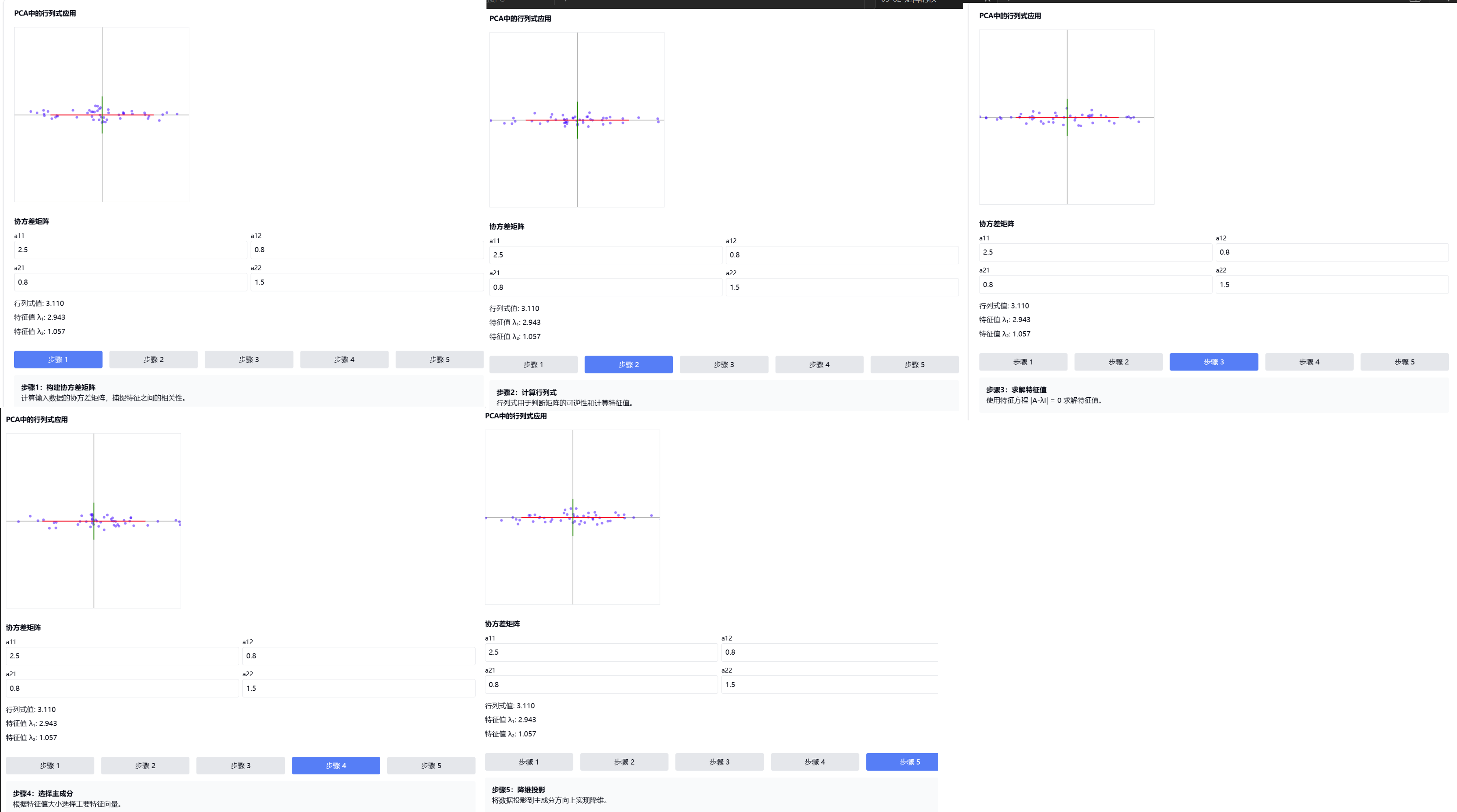
1. 为什么选用行列式
在PCA中,行列式具有多重重要作用:
-
可逆性判断:
- 行列式为0表示矩阵不可逆,存在线性相关性
- 这帮助我们发现数据中的冗余特征
-
特征值计算:
- 特征方程 |A-λI| = 0 中使用行列式
- 特征值反映了数据在各个方向上的方差
-
体积解释:
- 行列式的几何意义是变换后的体积
- 帮助理解数据分布的"扩展程度"
2. 使用行列式的思路和技巧
-
分解策略:
# 对于2×2矩阵 def get_eigenvalues(A): trace = A[0,0] + A[1,1] # 迹 det = A[0,0]*A[1,1] - A[0,1]*A[1,0] # 行列式 sqrt_term = np.sqrt(trace**2 - 4*det) return (trace + sqrt_term)/2, (trace - sqrt_term)/2 -
数值稳定性:
- 使用SVD代替直接求行列式
- 处理大矩阵时避免直接计算行列式
-
降维思路:
- 根据特征值大小排序
- 选择最大的k个特征值对应的特征向量
3. 完整使用过程
-
数据预处理:
# 中心化 X_centered = X - X.mean(axis=0) # 计算协方差矩阵 cov_matrix = np.cov(X_centered.T) -
特征值分解:
# 计算特征值和特征向量 eigenvals, eigenvecs = np.linalg.eigh(cov_matrix) -
选择主成分:
# 排序并选择前k个 k = 2 # 降到2维 idx = eigenvals.argsort()[::-1] top_eigenvecs = eigenvecs[:, idx[:k]] -
数据投影:
# 降维 X_reduced = X_centered.dot(top_eigenvecs)
4. 注意事项
-
数值稳定性:
- 大矩阵行列式计算可能不稳定
- 考虑使用对数行列式
- 使用SVD等替代方法
-
维度灾难:
- 高维空间中行列式计算开销大
- 需要考虑稀疏矩阵优化
-
特征选择:
- 不要机械地选择特征值最大的
- 结合实际问题和方差贡献率
-
数据预处理:
- 中心化和标准化很重要
- 异常值会显著影响行列式
-
解释性:
- 保持对行列式几何意义的理解
- 结合具体业务解释结果


















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











