






第二章 有关计算机内部信息的表示和处理
前言:我们对计算机系统的探索是从学习计算机本身开始,它由处理器和储存器子系统组成。在核心部分,我们需要方法来表示基本数据类型,比如整数和实数运算的近似值。然后,我们为您考虑机器级指令如何操作这样的数据,以及编译器又如何将C语言程序翻译成这样的指令。这也是我们的学习的一个重点部分,这一章主要就是学习机器内部是如何 存储和处理数据。
一.需要了解的基础知识
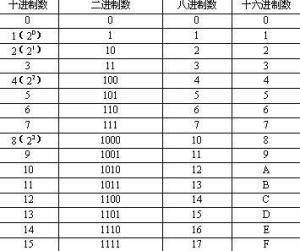
首先,我们要知道的是,所有的数据在机器内部都是以0101的形式表示的
1 进制
计算机内部之所以采用二进制,其主要原因是二进制具有以下优点:
1. 技术上容易实现。用双稳态电路表示二进制数字0和1是很容易的事情。
2. 可靠性高。二进制中只使用0和1两个数字,传输和处理时不易出错,因而可以保障计算机具有很高的可靠性。
3. 运算规则简单。与十进制数相比,二进制数的运算规则要简单得多,这不仅可以使运算器的结构得到简化,而且有利于提高运算速度。
4. 与逻辑量相吻合。二进制数0和1正好与逻辑量“真”和“假”相对应,因此用二进制数表示二值逻辑显得十分自然。
5. 二进制数与十进制数之间的转换相当容易。人们使用计算机时可以仍然使用自己所习惯的十进制数,这给工作带来极大的方便。
1.学习二进制
二进制非常简单,就不赘述了,如果不会的可以自己去网上查资料或者看百科就行
百度百科:二进制数
2.十六进制
十六进制数具有下列两个特点:
英文字母A,B,C,D,E,F分别表示数字10~15。
计数到F后,再增加1个,就进位。
十六进制数是计算机常用的一种计数方法,它可以弥补二进制数书写位数过长的不足,也用于电视机中。
十六进制数的表示方式为0x开头。
示例:0xAF=175
换句话说,十六进制就是在二进制的基础上进行了一定的转换,以每四位二进制化为一个十六进制数
3.相关的基础运算
基础加减的原理和十进制一样,需要借位或进位,稍微进阶一点的就是bool运算了
具体的学习请参考其他博主的文章
机器逻辑运算
布尔代数运算总结
2 字数据的大小
接下来看一下在64位机器内部字数据的大小
| C声明 | 字节数 |
|---|---|
| char | 1 |
| short | 4 |
| int | 4 |
| long | 8 |
| int64_t | 8 |
| char* | 8 |
| float | 4 |
| double | 8 |
注:在64位机器中所有的指针类型都是8个字节!!!
32位机器和64位有点不同,有兴趣的可以看看
64位与32位中数据表示的不同
3 大小端问题
在数据处理过程中,存放在静态存储区的数据由CPU寻址进行读取、译码和操作。问题在于读取之后如何进行值的大小确定,这就涉及了位的权值,依此,我们来介绍大小端的概念。
在内存中,大端模式或小端模式是由计算机的硬件操作系统决定的。
⑴ 大端 Big-endian
指数据的高位存储在低地址中,数据的低位存储在高地址中。即越往下,数据的权值越大;越往上,数据的权值越小。
⑵ 小端 Little-endian
指数据的高位存储在高地址中,数据的低位存储在低地址中。即越往下,数据的权值越小,越往上,数据的权值越大。
4 原码、反码和补码
⑴ 原码:数据的二进制表达形式。
⑵ 反码:正数的反码不变,负数的反码在原码的基础上除了符号位,其他都取反。
⑶ 补码(重点):正数的补码不变,负数的补码在原码的基础上除了符号位取反,并且在最后位上加一。
由于最高位上存储的是数据的符号,我们将除符号位的7位二进制表示的数称为真值;带有符号位的八位二进制表示的数称为形式值。
下面,我们探讨数据在内存中的存储形式:
我们知道,数据在计算机内都是以二进制的形式来表示的,原码、反码和补码都表示同一个数据,问题是,数据究竟是以这三种表示形式中的哪一种被存储进内存的呢?
假设,数据以原码的形式存储:
用原码进行简单的数据运算:1-1=0
在计算机中运行减法运算时,可以将减去一个数转换成加上这个数的负数。因为在数据的二进制表达中,数据的正负是通过最高位的数字来表示的(0表示正数,1表示负数),如果计算机进行运算时对符号位进行辨认后再操作,那么程序就太过复杂了。为了在计算过程中将符号位也带入运算,简化运算步骤,将计算机中的减数都转换成加上这个数的负数。
1-1=1+(-1)=[00000001]原+[10000001]原
=[10000010]原=-2
显然,用原码进行数据运算后的结果是错误的。故在计算机中,数据的存储形式不是原码。
再假设,数据以反码的形式存储:
用反码进行简单的数据运算:1-1=0
1-1=1+(-1)=[00000001]原+[10000001]原
=[00000001]反+[11111110]反
=[11111111]反=[10000000]原
=-0
从真值上看,用反码表示数据时进行的数据运算的结果是可取的,但问题出在0前面的“负号”上。
如果计算机用反码存储数据,那么对于数据0,就有一正一负两种表达形式,显然,这是不可取的。
补码的出现,解决了0的双符号和两个编码的问题:
用补码进行数据存储,进行简单的数值运算:1-1=0
1-1=1+(-1)=[00000001]原+[10000001]原
=[00000001]反+[11111110]反
=[00000001]补+[11111111]补(注:在运算过程中,符号位也参与运算,该进位就进位)
=[00000000]补=[00000000]原(补码的补码等于原码)
=0
附上原文链接
补码是非常重要的一个点,一定要好好学!!!
了解了上述的基础内容之后,就可以正式学习数据的具体表示
二. 数值的具体表示
1.int
(1)我们都知道整型是4个字节(有些编译器不同,可能会是2个),即32位,无符号整型当然也为32位。
(2)既然是32位,无符号整型的取值是32个0-32个1,即:0~4294967295
(3) 我们举个例子:32位有点长,所以我们拿16位的unsigned short int 来举例。
short int 是16位的,无符号的范围是0~65535
就拿十进制的32767(以下的所有举例均拿这个数字来说事了)来说,它的二进制为:
0111 1111 1111 1111
对于无符号的整型32767来说,它的二进制的最高位称为数据位,即那个0就是数据位,数据位是要参与运算的,如果我们把0改成1,即16个1,它的十进制就是65535(就是2的15次方+2的14次方…一直加到2的0次方),这是不同于有符号整型的。
来看一个很简单的例子:
main()
{
unsigned short int a=32767,b=a+1;//定义短整型无符号
printf("a=%u\nb=%u\n",a,b);//以无符号输出
}
定义的时候a=32767,也就是0111 1111 1111 1111,输出的依然是32767,
a+1=32768, 二进制为1000 0000 0000 0000,输入依然为32768。
这个问题又回到了补码的表示那里
如果还是不能理解,有详细一点的版本int 与 unsigned int
例:在进行整数运算时要注意溢出的问题
#include <stdio.h>
#include <stdlib.h>
int sq(int x) {
return x*x;
}
int main(int argc, char *argv[]) {
int i;
for (i = 1; i < argc; i++) {
int x = atoi(argv[i]);
int sx = sq(x);
printf("sq(%d) = %d\n", x, sx);
}
return 0;
}
运行结果如下:
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 12
sq(12) = 144
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 65535
sq(65535) = -131071
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 40000
sq(40000) = 1600000000
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 50000
sq(50000) = -1794967296
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 400000
sq(400000) = 1086210048
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 500000
sq(500000) = 891896832
上面这个程序就发生了溢出,导致负数的出现,因此,我们在写代码的时候要充分考虑到数据的范围,尽量避免因溢出产生错误。
2.浮点数
浮点数有两种,单精度浮点数float和双精度浮点数double
| 类型 | 最小值 | 最大值 |
|---|---|---|
| float | 1.175494351 E – 38 | 3.402823466 E + 38 |
| double | 2.2250738585072014 E – 308 | 1.7976931348623158 E + 308 |
| 数据类型 | 指数 | 尾数 |
|---|---|---|
| float | 8 | 23 |
| double | 11 | 53 |
IEEE754标准规定一个实数V可以用: V=(-1)s×M×2^E的形式表示,说明如下:
(1)符号s(sign)决定实数是正数(s=0)还是负数(s=1),对数值0的符号位特殊处理。
(2)有效数字M是二进制小数,M的取值范围在1≤M<2或0≤M<1。
(3)指数E(exponent)是2的幂,它的作用是对浮点数加权。
最终的运算可以直接套公式。

例:浮点数也要注意精度损失的问题
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define BUFSIZE 256
int main(int argc, char *argv[]) {
char prefix[BUFSIZE];
char next[BUFSIZE];
int i;
float sum = 0.0;
for (i = 1; i < argc; i++) {
float x = atof(argv[i]);
sum += x;
if (i == 1) {
sprintf(prefix, "%.4g", x);
} else {
sprintf(next, " + %.4g", x);
strcat(prefix, next);
printf("%s = %.4g\n", prefix, sum);
}
}
return 0;
}
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out 1e20 -1e20 3.14
1e+20 + -1e+20 = 0
1e+20 + -1e+20 + 3.14 = 3.14
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out -1e20 3.14
-1e+20 + 3.14 = -1e+20
@ubuntu:/mnt/hgfs/share/csapp_code$ ./a.out -1e20 3.14 1e20
-1e+20 + 3.14 = -1e+20
-1e+20 + 3.14 + 1e+20 = 0
上式中3.14相比1e20 太小了,被舍除,结果出现错误。
如果想要了解更加详细的运算过程,请参考另一位大佬的文章浮点数运算原理
总结
第二章到此就差不多结束了,这一章我们学习了机器内部的一些数的表示和运算以及从计算机内部从最底层来找出代码的运行问题所在。下一章我们将继续机器内部的学习,学习程序在机器内部具体是如何存储,调用。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









