






这里只是对代码的解析,我在写这个解析的时候并没有看后面的内容,只能大概猜一下可能是要干嘛的
首先是import相关工具,这里使用pytorch
%matplotlib inline
import torch
from d2l import torch as d2l
torch.set_printoptions(2) # 精简输出精度1.生成锚框
接下来是第一个难点,这个代码生啃确实得整理一下,不然很多细节都不知道。
大家可以参考https://zh-v2.d2l.ai/chapter_computer-vision/anchor.html#subsec-predicting-bounding-boxes-nms
的计算公式,其实沐神的公式没啥问题,归一化之后的结果就是下面: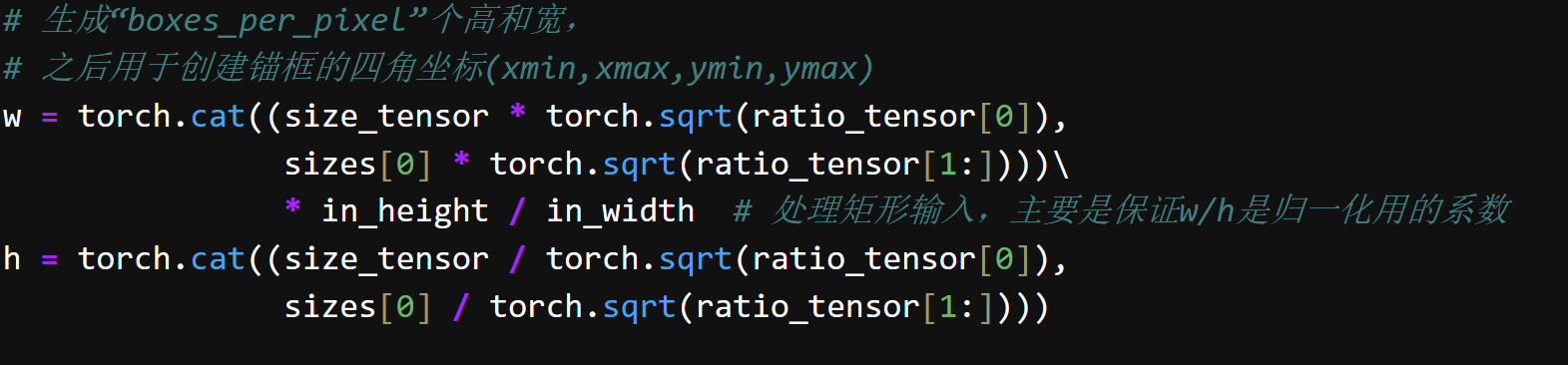
很多人不明白为什么w归一化之后要乘以一个in_height/in_width,假如没有这个的话
最后的锚框宽为w * in_width, 高为 h * in_height, 这里面发现只有高能对上
如果w = w * in_height/in_width, author_w = (w*in_height/in_width) * in_width = w * in_height
这样是不是发现最后的锚框宽高是不是就满足归一化的成比例关系了,此时r就是锚框的宽高比
不过这个地方,具体问题具体分析吧,我觉得没有 * in_height/in_width也无所谓,毕竟这样也改变了面积。
归根结底是在准确的锚框都是训练出来的,最后都是会把物体框住
#@save
def multibox_prior(data, sizes, ratios):
"""生成以每个像素为中心具有不同形状的锚框"""
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
# shift_y, shift_x都是笛卡尔坐标系下的值
# 例如有四个点(1, 0), (2, 0), (1, 1), (2, 1)
# 输出为 [0, 0], [1, 1] 和 [1, 1], [2, 2] / reshape(-1)后也是中心点的总个数
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # 处理矩形输入,主要是保证w/h是归一化用的系数
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
# 因为要和中心点相加,所以这里除以2
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次, 根据想要生成的锚框的种类来算
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)
img = d2l.plt.imread('./catdog.jpg')
h, w = img.shape[:2]
print(h, w)
X = torch.rand(size=(1, 3, h, w))
Y = multibox_prior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
Y.shape2.显示边框
这里没什么好说的
def show_bboxes(axes, bboxes, labels=None, colors=None):
"""显示所有边界框"""
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
d2l.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5'])3.iou
下面的代码我举了例子,其实还好理解,唯一我觉得对不上的地方,这个坐标不是左下角和右上角吗,和文章里说的不一样,不过意思也是一个意思
如果左上和右下:
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])这两行的max和min应该换一下
def box_iou(boxes1, boxes2):
"""计算两个锚框或边界框列表中成对的交并比"""
box_area = lambda boxes: ((boxes[:, 2] - boxes[:, 0]) *
(boxes[:, 3] - boxes[:, 1]))
# boxes1,boxes2,areas1,areas2的形状:
# boxes1:(boxes1的数量,4),
# boxes2:(boxes2的数量,4),
# areas1:(boxes1的数量,),
# areas2:(boxes2的数量,)
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
# inter_upperlefts,inter_lowerrights,inters的形状:
# (boxes1的数量,boxes2的数量,2)
# print(boxes1[:, None, :2].shape, boxes2[:, :2].shape)
# print(boxes1[:, None, :2])
# print(boxes2[:, :2])
inter_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
# print(inter_upperlefts)
inter_lowerrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
inters = (inter_lowerrights - inter_upperlefts).clamp(min=0)
# inter_areasandunion_areas的形状:(boxes1的数量,boxes2的数量)
inter_areas = inters[:, :, 0] * inters[:, :, 1]
union_areas = areas1[:, None] + areas2 - inter_areas
return inter_areas / union_areas
boxes1 = torch.tensor([
[0.00, 0.10, 0.20, 0.30],
[0.15, 0.20, 0.40, 0.40],
[0.63, 0.05, 0.88, 0.98],
[0.66, 0.45, 0.80, 0.80],
[0.57, 0.30, 0.92, 0.90]
])
boxes2 = torch.tensor([
[0.10, 0.08, 0.52, 0.92],
[0.55, 0.20, 0.90, 0.88]
])
print(boxes1.shape, boxes2.shape)
box_iou(boxes1, boxes2)4.分配接近的锚框
#@save
def assign_anchor_to_bbox(ground_truth, anchors, device, iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框"""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# 位于第i行和第j列的元素x_ij是锚框i和真实边界框j的IoU
jaccard = box_iou(anchors, ground_truth)
# print(jaccard)
# 对于每个锚框,分配的真实边界框的张量
anchors_bbox_map = torch.full((num_anchors,), -1, dtype=torch.long,
device=device)
# 根据阈值,决定是否分配真实边界框
max_ious, indices = torch.max(jaccard, dim=1)
# print(max_ious, indices)
anc_i = torch.nonzero(max_ious >= iou_threshold).reshape(-1)
# print(anc_i)
box_j = indices[max_ious >= iou_threshold]
anchors_bbox_map[anc_i] = box_j
# print(anchors_bbox_map)
col_discard = torch.full((num_anchors,), -1)
row_discard = torch.full((num_gt_boxes,), -1)
for _ in range(num_gt_boxes):
max_idx = torch.argmax(jaccard)
box_idx = (max_idx % num_gt_boxes).long()
anc_idx = (max_idx / num_gt_boxes).long()
anchors_bbox_map[anc_idx] = box_idx
jaccard[:, box_idx] = col_discard
jaccard[anc_idx, :] = row_discard
return anchors_bbox_map
anchors = torch.tensor([
[0.00, 0.10, 0.20, 0.30],
[0.15, 0.20, 0.40, 0.40],
[0.63, 0.05, 0.88, 0.98],
[0.66, 0.45, 0.80, 0.80],
[0.57, 0.30, 0.92, 0.90]
])
ground_truth = torch.tensor([
[0.10, 0.08, 0.52, 0.92],
[0.55, 0.20, 0.90, 0.88]
])
assign_anchor_to_bbox(ground_truth, anchors, "cpu")
def offset_boxes(anchors, assigned_bb, eps=1e-6):
"""对锚框偏移量的转换"""
c_anc = d2l.box_corner_to_center(anchors)
c_assigned_bb = d2l.box_corner_to_center(assigned_bb)
offset_xy = 10 * (c_assigned_bb[:, :2] - c_anc[:, :2]) / c_anc[:, 2:]
offset_wh = 5 * torch.log(eps + c_assigned_bb[:, 2:] / c_anc[:, 2:])
offset = torch.cat([offset_xy, offset_wh], axis=1)
return offset
#@save
def multibox_target(anchors, labels):
"""使用真实边界框标记锚框"""
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
batch_offset, batch_mask, batch_class_labels = [], [], []
device, num_anchors = anchors.device, anchors.shape[0]
for i in range(batch_size):
label = labels[i, :, :]
# 获取anchors对应真实labels的索引
# 例如[-1, 0, 1, -1, 1],表示锚框1和label0最相近,锚框2和label1最相近
# label[:, 0]代表类
anchors_bbox_map = assign_anchor_to_bbox(
label[:, 1:], anchors, device)
# 这里面把预测到的对应label的变成一个mask矩阵
# 例如[-1, 0, 1, -1, 1]
# [0., 0., 0., 0.],
# [1., 1., 1., 1.],
# [1., 1., 1., 1.],
# [0., 0., 0., 0.],
# [1., 1., 1., 1.]
bbox_mask = ((anchors_bbox_map >= 0).float().unsqueeze(-1)).repeat(
1, 4)
print(bbox_mask)
# 将类标签和分配的边界框坐标初始化为零
class_labels = torch.zeros(num_anchors, dtype=torch.long,
device=device)
assigned_bb = torch.zeros((num_anchors, 4), dtype=torch.float32,
device=device)
# 使用真实边界框来标记锚框的类别。
# 如果一个锚框没有被分配,标记其为背景(值为零)
print(anchors_bbox_map)
# 获取anchors_bbox_map中的哪些锚框是预测出来类了
indices_true = torch.nonzero(anchors_bbox_map >= 0)
print(indices_true)
# 根据上面获得的锚框idx,再次获得这些锚框预测的哪一个类
bb_idx = anchors_bbox_map[indices_true]
print(bb_idx)
# 分别填上预测的类和锚框坐标
# label中写死了,第一个索引list里面的idx值就是种类值,+1是因为,这里认为背景是0
class_labels[indices_true] = label[bb_idx, 0].long() + 1
assigned_bb[indices_true] = label[bb_idx, 1:]
# 偏移量转换, 传入生成的anchors和label锚框
# 注意这里只比较预测对的,不预测的都按0算, 所以×了一个bbox_mask
offset = offset_boxes(anchors, assigned_bb) * bbox_mask
batch_offset.append(offset.reshape(-1))
batch_mask.append(bbox_mask.reshape(-1))
batch_class_labels.append(class_labels)
bbox_offset = torch.stack(batch_offset)
bbox_mask = torch.stack(batch_mask)
class_labels = torch.stack(batch_class_labels)
return (bbox_offset, bbox_mask, class_labels)
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
print(ground_truth.shape, anchors.shape)
labels = multibox_target(anchors.unsqueeze(dim=0),
ground_truth.unsqueeze(dim=0))5.nms
#@save
def offset_inverse(anchors, offset_preds):
"""根据带有预测偏移量的锚框来预测边界框"""
anc = d2l.box_corner_to_center(anchors)
pred_bbox_xy = (offset_preds[:, :2] * anc[:, 2:] / 10) + anc[:, :2]
pred_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anc[:, 2:]
pred_bbox = torch.cat((pred_bbox_xy, pred_bbox_wh), axis=1)
predicted_bbox = d2l.box_center_to_corner(pred_bbox)
return predicted_bbox
#@save
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
B = torch.argsort(scores, dim=-1, descending=True)
keep = [] # 保留预测边界框的指标
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
iou = box_iou(boxes[i, :].reshape(-1, 4),
boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
inds = torch.nonzero(iou <= iou_threshold).reshape(-1)
B = B[inds + 1]
return torch.tensor(keep, device=boxes.device)
#@save
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5,
pos_threshold=0.009999999):
"""使用非极大值抑制来预测边界框"""
# print(cls_probs.shape, offset_preds.shape, anchors.shape)
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
# print(anchors)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
out = []
for i in range(batch_size):
cls_prob, offset_pred = cls_probs[i], offset_preds[i].reshape(-1, 4)
# print(offset_pred)
# class_id是类别预测的tesnor, 例如
# [
# [0, 0, 0, 0],
# [0.9, 0.8, 0.7, 0.1],
# [0.1, 0.2, 0.3, 0.9],
# ]
# 代表第0类(背景)所有锚框都预测不出来,第一类四个锚框预测为第一类的概率为[0.9, 0.8, 0.7, 0.1]
# 下面的操作会把所有锚框里面,不管是什么种类,只要是预测最大,都给展现出来,还有这个最大的概率是哪个种类
# class_id = [0, 0, 0, 1]
conf, class_id = torch.max(cls_prob[1:], 0)
# print(cls_prob, conf, class_id)
predicted_bb = offset_inverse(anchors, offset_pred)
# keep 返回置信度最高, 但是互相不相关的索引(锚框id, 小于num_anchors)
# eg. keep = [0, 3], 第0个和第一个锚框置信度比较高,但是他们不相关,是两个class
keep = nms(predicted_bb, conf, nms_threshold)
# print(keep)
# 找到所有的non_keep索引,并将类设置为背景
# 例如num_anchors = 4, all_idx=[0, 1, 2, 3]
all_idx = torch.arange(num_anchors, dtype=torch.long, device=device)
# eg.上面的例子中 keep = [0, 3], combined = [0, 3, 0, 1, 2, 3], 明显可以看到置信度最高的锚框个数会多一个
combined = torch.cat((keep, all_idx))
# print(combined)
# 因为一共四个锚框,uniques=[0, 1, 2, 3], counts=[2, 1, 1, 2]
uniques, counts = combined.unique(return_counts=True)
# print(uniques, counts)
# counts == 1 等价于[False, True, True, False]
# 此时non_keep = [1, 2]
non_keep = uniques[counts == 1]
# print(non_keep)
# 这里面就把置信度最高的锚框放在最前面,[0, 3, 1, 2], 不重要的在后面了
all_id_sorted = torch.cat((keep, non_keep))
# print(class_id, all_id_sorted)
# class_id是四个锚框的预测最大概率的种类,non_keep是不要的锚框
# 因为non_keep = [1, 2],表示第一个和第二个锚框已经丢弃了,换成背景就可以了
class_id[non_keep] = -1
# print(class_id)
# 换完之后 -1 的锚框就都丢到后面了,all_id_sorted就是索引
# 此时class_id = [0, 1, -1, -1]
class_id = class_id[all_id_sorted]
# print(class_id)
# 同理conf,和predicted_bb也要同样移动位置
# conf:[0.9, 0.8, 0.7, 0.9] --> [0.9, 0.9, 0.8, 0.7]
# predicted_bb: [[aucher0的坐标], [aucher1的坐标], [aucher2的坐标], [aucher3的坐标]]
# -->[[aucher0的坐标], [aucher3的坐标], [aucher1的坐标], [aucher2的坐标]]
conf, predicted_bb = conf[all_id_sorted], predicted_bb[all_id_sorted]
# pos_threshold是一个用于非背景预测的阈值
# 小于pos_threshold。 不管前面怎么计算,就彻底是背景了
# 这是因为计算nms的时候,可能一个类,有多个预测还可以的锚框。
# 比如人的上半身是一个auchor,下半身是一个,nms有可能把这两个都筛选出来
below_min_idx = (conf < pos_threshold)
# 标记为背景
class_id[below_min_idx] = -1
# 既然是背景,目标类的概率 + 背景类的概率 = 1, 所以背景类的概率为 1 - 目标类的概率
conf[below_min_idx] = 1 - conf[below_min_idx]
# 拼接起来,分别是该锚框是哪个类,预测概率和锚框坐标 [0.00, 0.90, 0.10, 0.08, 0.52, 0.92]
pred_info = torch.cat((class_id.unsqueeze(1),
conf.unsqueeze(1),
predicted_bb), dim=1)
out.append(pred_info)
return torch.stack(out)
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
output = multibox_detection(cls_probs.unsqueeze(dim=0),
offset_preds.unsqueeze(dim=0),
anchors.unsqueeze(dim=0),
nms_threshold=0.5)
print(output)
fig = d2l.plt.imshow(img)
for i in output[0].detach().numpy():
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)














 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









