






PCA(主成分分析算法)出现的比较早。
PCA算法依赖于一个基本假设:一类图像具有某些相似的特征(如人脸),在整个图像空间中呈现出聚类性,因而形成一个子空间,即所谓特征子空间,PCA变换是最佳正交变换,利用变换基的线性组合可以描述、表达和逼近这一类图像,因此可以进行图像识别,PCA包含训练和识别两个阶段。
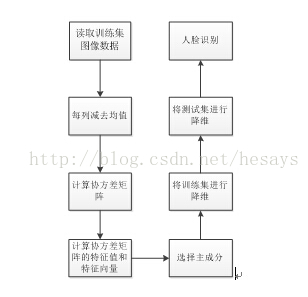
训练阶段:
1)计算平均脸
2)计算差值脸
3)构建协方差矩阵
4)计算矩阵的特征值和特征向量
5)将每幅人脸的差值脸投影到特征空间W上,就可以得到每幅人脸的P的特征。
识别阶段:
1)将待检测的人脸图像T的差值脸投影到特徵空间,得到人脸T的特征
2)从训练集中一次取出每张人脸的特征脸U。利用U与U的欧氏距离做相似性判定T是已知人脸或未知人脸。
根据Kyungnam Kim在其论文 Face Recognition using Principle Component Analysis 中所陈述,PCA人脸识别的基本思想是“…express the large 1-D vector of pixelsconstructed from 2-D facial image into the compact principal components of thefeature space(eigenspace projection).” 也就是从人脸图像中找出最能代表人脸的特征空间。一个单个的人脸图片映射到这个特征空间得到这个特征空间的一组系数(这张人脸图片的特征脸特征)。如果两张人脸图片映射到这个特征空间的系数差不多,就表示这两张人脸是同一个人。从论文中我们也知道了特征空间的计算方法“Eigenspace is calculated byidentifying the eigenvectors of the covariance matrix derived from a set offacial images(vectors). ”
流程图
数据库:
测试数据库为ORL_92x112,其中含40个人,每人10张图片,共400张图片。
下图为40个人的第一张图片。

训练阶段
1.1 一张人脸图片在计算机表示为一个像素矩阵,即是一个二维数组,现在把这个二维数组变成一维数组,即把第一行后面的数全部添加到第一行。这样一张图片就能表示为一个向量d=(x1,x2......xn)。xn表示像素。
1.2 现在训练库里有m张人脸图片,把这些图片都表示成上述的向量形式,即d1,d2,。。。dm,把这m个向量取平均值得向量avg=(y1,y2......yn)。
得到平均图像:

1.3 用d1,d2...........dm分别减去avg后组成一个矩阵A,即矩阵A的第一行为d1-avg,后面类似。A的大小为m×n。因为找特征空间不能基于一张图片,而要在所有的人脸图片提取出共同特征,所以要取各个人脸向量到平均人脸向量的向量差。依据这个每个人脸图片跟平均脸向量的向量差组成矩阵A,然后依据矩阵A来求解最特征空间。
1.4.矩阵A乘以A的逆矩阵A‘得A的协方差矩阵B,B的大小m×m,求B的特征向量。取最大的K个特征向量组成新的矩阵T,T的大小m×k。
1.5 使用A’乘以T得到特征脸C,C的大小n×k。
1.6 用图片向量d乘以C得到图片向量d在特征脸的投影向量pn,有多少张图片就有多少个pn。pn的大小1×k
探究各特征值所占有的能量数
2.1 第n个特征值占所有特征值之和的百分比 (特征值从小到大排列)。
2.2前n个特征值占所有特征值之和的百分比 (特征值从小到大排列)。
在实验中,要求保留90%的能量,所以当取前57个特征值得时候就可以满足要求了。
测试阶段
3.1.一张新的图片也表示为d的向量,记为D,D的大小1×n
3.2. D乘以上面训练得到的特征脸C得到这个图片向量D在C下的投影向量P,p的大小1×k。
3.3.计算p与上面所有的pn的向量距离,与p最小的那个向量所对应的人脸图片跟这张新人脸图片最像。
3.4.判别图像的相似性有两种方法:一种是计算N维空间中图像间的距离,另一种是测量图像间的相似性。当测量距离时,距离应尽可能的小,一般选择距离测试图像最近的训练图像作为它所属的类别,识别的方法和最初的图像匹配方法类似:将测试集中的每一幅降维图像与降维的训练集进行匹配,然后将其分类到距离最小的训练集头像中,如果两个头像表示一个人,表示识别成功。而测量相似性时,图像应尽可能的相似,也就是说具有最大相似性的训练图像类被认为是测试图像所属的类别。本程序采用三阶近邻法。核心代码如下
运行程序后,将读取40个人的后5张图片,并进行比对,代码附录给出。
可得到识别率为accuracy =0.8500;
参考文献
[1]Kyungnam Kim. Face Recognition using Principle Component Analysis [J] . IEEESignal Processing Society,2002,9(2):40-42.
[2] 罗韵. 用Matlab进行PCA人脸识别 [N/OL] . 网易LOFTER,[2013-04-12] .http://blog.163.com/luoyun_dreamer/blog/static/215529070201331281538309/?suggestedreading
[3]haitao111313 . 基于PCA的人脸检测 [N/OL] . CSDN博客 , [2012-08-16] .http://blog.csdn.net/haitao111313/article/details/7875392
[4] Turk,M.A. ; Media Lab., MIT, Cambridge, MA, USA ; Pentland, A.P. Face Recognitionusing Eigenfaces [J] . IEEE Signal Processing Society,1991,7
http://blog.csdn.net/hesays/article/details/39498375
附录1.基于PCA的人脸识别的Matlab实现代码
function FaceRecognition
clear % calc xmean,sigma and its eigen decomposition
close all
allsamples=[];%所有训练图像
for i=1:40
for j=1:5
if(i<10)
a=imread(strcat('E:\ORL_92x112\00',num2str(i),'0',num2str(j),'.bmp'));
else
a=imread(strcat('E:\ORL_92x112\0',num2str(i),'0',num2str(j),'.bmp'));
end
b=a(1:112*92); % b是行矢量 1×N,其中N=10304,提取顺序是先列后行,即从上到下,从左到右
b=double(b);
allsamples=[allsamples; b]; % allsamples 是一个M * N 矩阵,allsamples 中每一行数据代表一张图片,其中M=200
end
end
samplemean=mean(allsamples); % 平均图片,1 × N
figure%平均图
imshow(mat2gray(reshape(samplemean,112,92)));
for i=1:200
xmean(i,:)=allsamples(i,:)-samplemean; % xmean是一个M × N矩阵,xmean每一行保存的数据是“每个图片数据-平均图片”
end;
% figure%平均图
% imshow(mat2gray(reshape(xmean(1,:),112,92)));
sigma=xmean*xmean'; % M * M 阶矩阵
[v,d]=eig(sigma);
d1=diag(d);
[d2,index]=sort(d1); %以升序排序
cols=size(v,2);% 特征向量矩阵的列数
for i=1:cols
vsort(:,i) = v(:, index(cols-i+1) ); % vsort 是一个M*col(注:col一般等于M)阶矩阵,保存的是按降序排列的特征向量,每一列构成一个特征向量
dsort(i) = d1( index(cols-i+1) ); % dsort 保存的是按降序排列的特征值,是一维行向量
end %完成降序排列 %以下选择90%的能量
dsum = sum(dsort);
dsum_extract = 0;
p = 0;
while( dsum_extract/dsum < 0.9)
p = p + 1;
dsum_extract = sum(dsort(1:p));
end
a=1:1:200;
for i=1:1:200
y(i)=sum(dsort(a(1:i)) );
end
figure
y1=ones(1,200);
plot(a,y/dsum,a,y1*0.9,'linewidth',2);
grid
title('前n个特征特占总的能量百分比');
xlabel('前n个特征值');
ylabel('占百分比');
figure
plot(a,dsort/dsum,'linewidth',2);
grid
title('第n个特征特占总的能量百分比');
xlabel('第n个特征值');
ylabel('占百分比');
i=1; % (训练阶段)计算特征脸形成的坐标系
while (i<=p && dsort(i)>0)
base(:,i) = dsort(i)^(-1/2) * xmean' * vsort(:,i); % base是N×p阶矩阵,除以dsort(i)^(1/2)是对人脸图像的标准化,特征脸
i = i + 1;
end % add by wolfsky 就是下面两行代码,将训练样本对坐标系上进行投影,得到一个 M*p 阶矩阵allcoor
%
% for i=1:20
% figure%平均图
% b=reshape(base(:,i)',112,92);%
% imshow(mat2gray(b));
% end
allcoor = allsamples * base; accu = 0; % 测试过程
for i=1:40
for j=6:10 %读入40 x 5 副测试图像
if(i<10)
if(j<10)
a=imread(strcat('E:\ORL_92x112\00',num2str(i),'0',num2str(j),'.bmp'));
else
a=imread(strcat('E:\ORL_92x112\00',num2str(i),num2str(j),'.bmp'));
end
else
if(j<10)
a=imread(strcat('E:\ORL_92x112\0',num2str(i),'0',num2str(j),'.bmp'));
else
a=imread(strcat('E:\ORL_92x112\0',num2str(i),num2str(j),'.bmp'));
end
end
b=a(1:10304);
b=double(b);
tcoor= b * base; %计算坐标,是1×p阶矩阵
for k=1:200
mdist(k)=norm(tcoor-allcoor(k,:));
end; %三阶近邻
[dist,index2]=sort(mdist);
class1=floor( index2(1)/5 )+1;
class2=floor(index2(2)/5)+1;
class3=floor(index2(3)/5)+1;
if class1~=class2 && class2~=class3
class=class1;
elseif class1==class2
class=class1;
elseif class2==class3
class=class2;
end;
if class==i
accu=accu+1;
end;
end;
end;
accuracy=accu/200 %输出识别率

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









