






pandas是Python进行数据分析的过程中使用最广泛的库。利用pandas的内置方法,可以高效完成各种日常数据分析工作,如描述统计、数据清洗、分类汇总等。pandas的数据结构有4种,分别是Series、Time-Series、DataFrame和Panel。
1.Series:一维数组,与Numpy中的一维Array相似。
二者与List的区别是List中的元素可以是不同的数据类型,而Array和Series只允许存储相同的数据类型。
定义一个Series:
from pandas import Series
s = Series([1,2,'a','b','c'])
print(s)
0 1 1 2 2 a 3 b 4 c dtype: object
左侧的为索引,右侧列为元素值,可以通过索引修改元素值
s[3] = 'ccd'
print(s)0 1 1 2 2 a 3 ccd 4 c dtype: object
也可以通过index修改索引
s1=Series([1,2,'a','b','c'], index=['A','B','C','D','F'])
s2=Series([111,222,333])
s2.index=['a','b','c']
print(s1)
print(s2)A 1 B 2 C a D b F c dtype: object a 111 b 222 c 333 dtype: int64
2.Time-Series:以时间为索引的Series。
3.DataFrame:二维的表格型数据结构。
定义一个DataFrame。
from pandas import DataFrame
data={"title":['语文','数学','英语'],"score":[100,99,99]}
df=DataFrame(data)
print(type(data),type(df))
print(data)
print(df)<class 'dict'> <class 'pandas.core.frame.DataFrame'>
{'title': ['语文', '数学', '英语'], 'score': [100, 99, 99]}
title score
0 语文 100
1 数学 99
2 英语 99
如果需要保存的话,
df.to_csv('D:/desktop/xieru.csv',encoding='gbk')
这里需要注意的是,DataFrame写入的话,读取的数据无法按照索引来使用
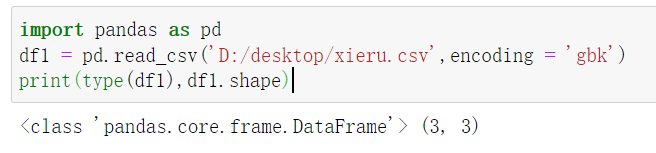

需要加上.values

DataFrame的列和索引均可以自定义。
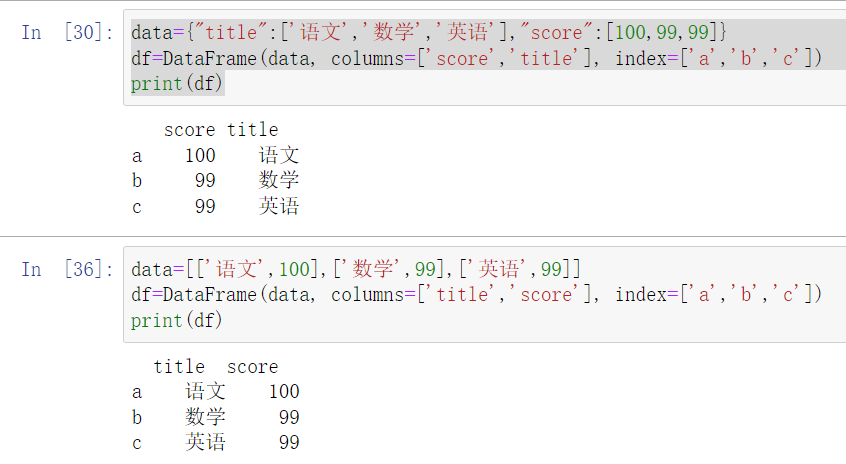
修改某一列的数据

修改具体某个位置的数据

4.Panel:三维数据。














 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









