- 博客(18)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 使用sklearn构建完整的分类项目
常用指标:其余笔记见word笔记截图好麻烦常规数据生成from sklearn import datasetsiris = datasets.load_iris()X = iris.datay = iris.targetfeature = iris.feature_namesdata = pd.DataFrame(X,columns=feature)data['target'] = y# 逻辑回归'''penalty {‘l1’, ‘l2’, ‘elast
2021-03-28 00:31:11
 243
243
原创 基础模型超参优化
网格搜索GridSearchCV():把所有的超参数选择列出来分别做排列组合,然后选择测试误差最小的那组超参数。随机搜索 RandomizedSearchCV() :参数的随机搜索中的每个参数都是从可能的参数值的分布中采样的。从指定的分布中采样固定数量的参数设置与网格搜索相比,这有两个主要优点:可以独立于参数数量和可能的值来选择计算成本。添加不影响性能的参数不会降低效率。贝叶斯优化。贝叶斯优化用于机器学习调参由J. Snoek(2012)提出,主要思想是,给定优化的目标函数(广义的函数,
2021-03-24 22:21:11
161
原创 偏差与方差
(a) 训练均方误差与测试均方误差:在回归中,我们最常用的评价指标为均方误差,即:MSE=1N∑i=1N(yi−f^(xi))2MSE = \frac{1}{N}\sum\limits_{i=1}^{N}(y_i -\hat{ f}(x_i))^2MSE=N1i=1∑N(yi−f^(xi))2其中f^(xi)\hat{ f}(x_i)f^(xi)是样本xix_ixi应用建立的模型f^\hat{f}f^预测的结果。一个模型的训练均方误差最小时,不能保证测试均方误差同时也很小。对于
2021-03-22 23:27:16
397
原创 集成学习(2/6)
task 1 略水没啥子意思什么是机器学习?机器学习的一个重要的目标就是利用数学模型来理解数据,发现数据中的规律,用作数据的分析和预测。机器学习的任务可分为:有监督学习和无监督学习。有监督学习:给定某些特征去估计因变量,即因变量存在的时候,我们称这个机器学习任务为有监督学习。如:我们使用房间面积,房屋所在地区,环境等级等因素去预测某个地区的房价。无监督学习:给定某些特征但不给定因变量,建模的目的是学习数据本身的结构和关系。如:我们给定某电商用户的基本信息和消费记录,通过观察数据中的哪些类型的用户彼
2021-03-15 22:57:10
189
 1
1
原创 leetcode global函数失效问题
a = 100 def testA(): print(a) def testB(): global a # 关键字声明a为全局变量,系统就会去找叫a的全局变量 a = 200 print(a) print(a) # 100 print(testA()) # 100 print(testB()) # 200 ...
2021-03-14 13:42:54
564
原创 手写逻辑回归python实现
调用范例:plt.scatter(X[y == 0, 0], X[y == 0, 1], color="red")plt.scatter(X[y == 1, 0], X[y == 1, 1], color="blue")plt.show()# 切分数据集X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)# 调用我们自己的逻辑回归函数log_reg = LogisticRegression()
2021-03-09 16:34:09
302
原创 leetcode题1008问题 ,求解
1008.前序遍历构造二叉搜索树返回与给定前序遍历 preorder 相匹配的二叉搜索树(binary search tree)的根结点。(回想一下,二叉搜索树是二叉树的一种,其每个节点都满足以下规则,对于 node.left 的任何后代,值总 < node.val,而 node.right 的任何后代,值总 > node.val。此外,前序遍历首先显示节点 node 的值,然后遍历 node.left,接着遍历 node.right。)题目保证,对于给定的测试用例,总能找到满足要求的二叉
2021-02-20 18:26:11
143
原创 insert和数组直接相加时间损耗
from time import *import numpy as npk= [i for i in range(100000000)]b1=time()k.insert(0,0)e1=time()b2=time()k=[0]+ke2=time()print('insert cost: ',e1-b1)print('add cost: ',e2-e1)#结果insert cost: 0.14162087440490723add cost: 1.356372356414795
2021-01-10 15:46:00
120
转载 将CSDN博客内容保存为PDF
文章转自:https://blog.csdn.net/u010954948/article/details/82843105, 为了方便自己使用,所以在这里保存一下!使用Google Chrome浏览器,在右上角点开设置一栏,找到更多工具—开发者工具,会弹出下图中界面:接下来在Console中黏贴下面一段代码,然后按回车键即可,当前页面的pdf会自动加载出来。(function(){$("#side").remove();$("#comment_title, #comment_list, #co
2020-12-07 23:16:12
206
原创 json.load报错
json_data=json.load(f1)使用报错Traceback (most recent call last): File "D:/Desktop/螃蟹/数据/螃蟹标注(姚)/姚/test_right.py", line 42, in <module> json_data=json.load(f1) File "C:\ProgramData\Anaconda3\lib\json\__init__.py", line 296, in load parse_con
2020-12-07 17:46:45
1079
原创 SQL笔记之开天辟地
调用 select [distinct] 列 from 表 [where 列 运算符 值] [order by 列1,列2 [desc]] 去重复 筛选 排序 逆序插入 INSERT INTO 表名称 VALUES "值1, 值2,...." INSERT INTO table_name (列1, 列2,...) VALUES (值1, 值2,....)修改 UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值删除 DEL
2020-11-27 21:14:14
393
原创 我还能学之python元组、字典、列表、set()
2020.11.16周末细看再补充(-。-)9.1 元组创建tup1 = (‘Google’, ‘atguigu’, 1997, 2000);tup2 = (1, 2, 3, 4, 5 );tup3 = “a”, “b”, “c”, “d”; # 不需要括号也可以9.2 元组值获取tup1[1]tup1[1:5]9.3 元组更新元组不允许更新9.4 删除元组元素del tup[0]9.5 元组运算符表达式 结果 描述len((1, 2, 3))
2020-11-16 22:03:35
142
原创 我真的学不动了之推荐系统(1)
推荐系统基础知识相似度计算余弦相似度调整余弦相似度(修正余弦相似度)皮尔逊 Pearson相关系数特征处理归一化离散化等步长等频类别特征处理One-Hot编码/哑变量时间特征处理离散连续统计特征反馈数据UGC简单推荐TF-IDFUGC参考TF-IDF协同过滤基础知识相似度计算余弦相似度调整余弦相似度(修正余弦相似度)解决:比如用户A、B和C对三个物品的评分分别为(1,4,0)、(3,5,1)和(8,9,2),用余弦相似度计算得到A和B用户之间的相似度为0.874实质上是防止高数值的user与低
2020-11-16 21:19:25
269
原创 我还能学之python杂记
杂记多行语句进制随机函数转义字符打印多行语句Python语句中一般以新行作为语句的结束符。但是我们可以使用斜杠( \)将一行的语句分为多行显示,如下所示:total = item_one + \ item_two + \ item_threeprint('aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa\ aaaaaaaaaaaaaaaaaaaa')语句中包含 [], {} 或 () 括号就不需要使用多行连接符。如下实例:day
2020-11-15 21:39:33
248
原创 我不知道在学什么之Scala学习笔记
笔记目录Scala基础1.Scala基础数据类型Scala基础1.Scala基础数据类型biji Scala中所有的数据都是对象,也就是说scala没有java中的原生类型。在scala是可以对数字等基础类型调用方法的。举例:数字 1是一个对象,就有方法(函数)scala> 1.toStringres0: String = 1 可以不用指定数据的类型,Scala会自动进行类型的推荐 举例:下面的两条语句是一样的
2020-11-15 15:38:16
767
原创 maskrcnn模型加载问题
文档外模型加载报错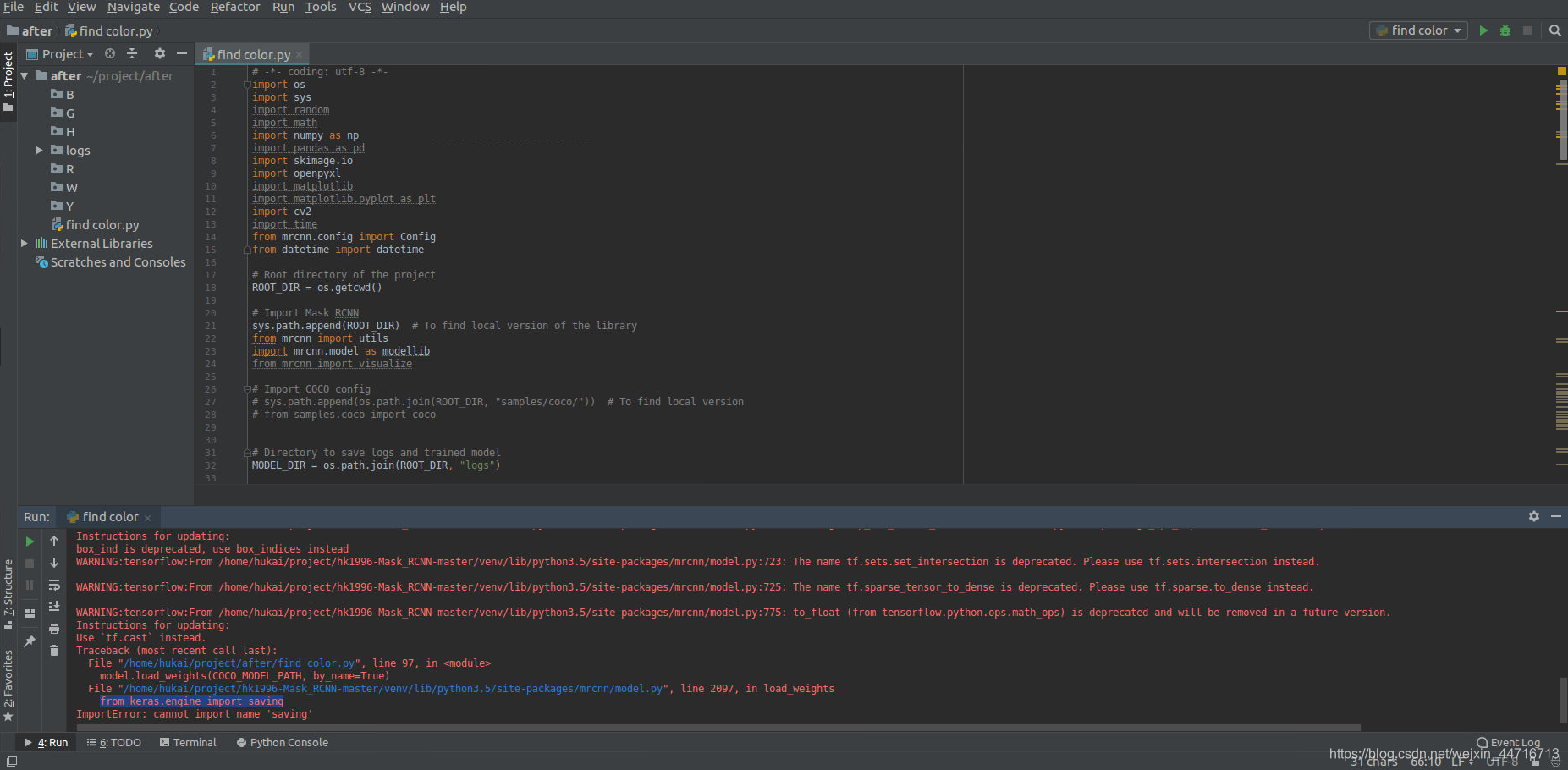...
2020-11-03 12:33:18
539
1
转载 解决RGB转Lab问题,lab值不对应的问题
引言解决RGB转Lab问题,lab值不对应的问题参考自原始csdn博客侵删cvtcolor颜色空间转换OpenCV有自带的颜色空间转换函数:img_lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)1需要注意的是,对于RGB转LAB的转换,输出的值取决于输入的图像的格式:8位图像:16位图像:目前不支持,调用时需转换为8位或者32位32位图像:输出与真实LAB结果一致如果将cvtColor与8位图像一起使用,转换将丢失一些信息。(如果有一个直接从
2020-11-03 12:10:28
2602
2
原创 Numpy笔记(1/4)
Numpy笔记(1/4)NumPy Ndarray 对象数据类型NumPy 数组属性创建数组从已有的数组创建数组动态输入数组从数值范围创建数组numpy.arangenumpy.linspacenumpy.logspace元组(1,2,3,4,5)ndarray[1 2 3 4 5 ]元组列表[(1,2,3),(4,5)]ndarray[(1, 2, 3) (4, 5)]NumPy Ndarray 对象其 N 维数组对象 ndarray。创建数组// An highlighted bloc
2020-10-28 23:34:57
300
![]()
空空如也
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人