







在Flink运行过程中,主要涉及Environment、Source、Transform、Sink四个部分,其中,最后三个尤为重要。
1. Environment
Flink程序在编写前首先要做的便是设置该程序的执行环境,而由于Flink主要面向的是流处理任务,所以一般情况下环境设置都为StreamExecutionEnvironment:

2. Source
Source可以理解为Flink流处理过程中获取数据的一个步骤,一般主要分为以下四种方式实现数据获取:
2.1 数据来自集合(很少使用)
在程序编写时定义一些确定某种数据类型的集合,直接调用即可。即:
fromElements()

fromCollection()

2.2 数据来自文件(批处理)
此法是从本地文件中读取需要的数据,光听描述就知道对于流处理任务并不适用

2.3 数据来自Kafka(生产环境中主要使用此法)
Kafka是一种存储数据的中间件,在真实的生产环境中多数情况下使用此法。


2.4 数据自定义(模拟真实情况,自定义生成数据)
重写SourceFunction接口,实现接口中的run和cancel方法。
下面实现的Demo中运用了HashMap数据结构,有几个地方值得注意:
.put(key,value)是向map中加入新的键值对,也可以用作修改,即覆盖原有键的值
.get(key)是访问该key所对应的value


3. Transform
Transform是整个Flink流处理中最重要的一个算子,常见的Transform算子如下:
3.1 Map算子(可以改变数据类型)
Map算子可以实现简单的转换功能,比如一个数乘另一个数。Map算子的输入和输出是一一对应的,可以理解为来一个处理一个。

Map算子及其之后介绍的算子的实现对于JAVA代码而言,核心思想都是实现XXFunction接口,然后实现接口中的方法,但大体上有两种实现方式:
·第一种,直接在括号内写方法实现(不推荐,可读性较差)
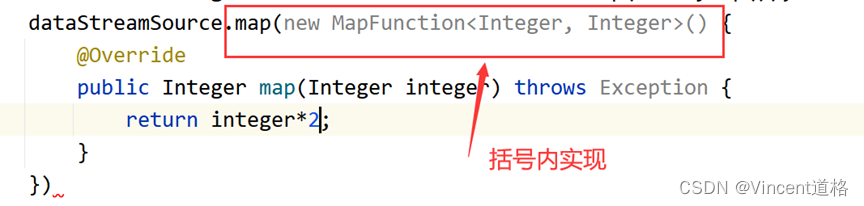
·第二种,到main方法外新建static class,实现该接口,重写方法(推荐,可读性较好)

·第三种,用lambda表达式(多见于Scala)

3.2 .FlatMap算子(可以改变数据类型)
FlatMap算子是Map算子的升级版,它可以将输入的数据做更为复杂的转换,其最为显著的特征是,输入集合后,输出将展开为一个个单独的元素。常见的如将输入的String集合转化为(word,1)的二元组形式

3.3 Filter算子
根据某种条件过滤掉一部分数据

Map、FlatMap、Filter统称为简单算子,因为这三种算子均为one-to-one,即DataStream->DataStream不涉及转换分区。
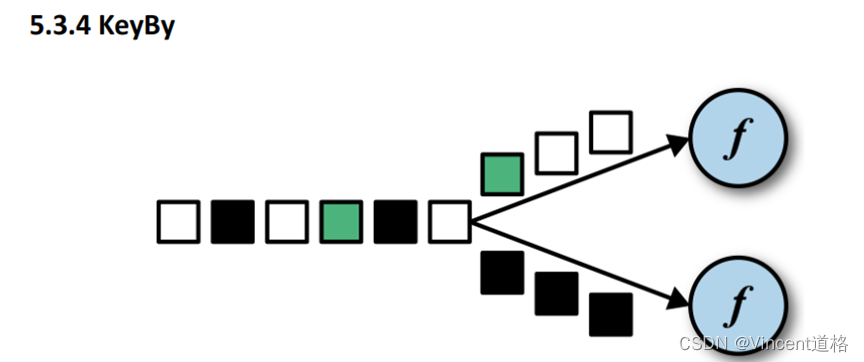
3.4 KeyBy算子
DataStream->keyedStream(也属于DataStream),根据哈希值做取模运算决定分区,不改变数据类型。
3.5 滚动聚合,最为简单的聚合操作
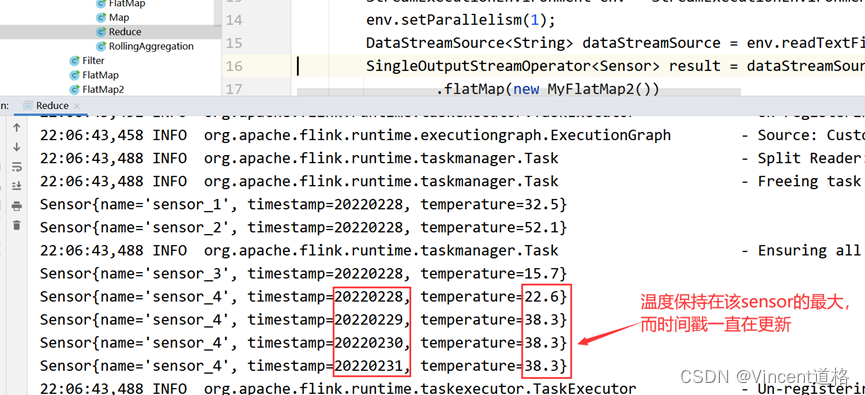
一个数据一个数据地做聚合操作,注意,聚合操作只有在完成分组后才能进行。如Max,Min,Sum,MaxBy,MinBy。值得一提的是,Max(字段1)方法只会对字段1的最大值进行更新,

要想实现不仅更新字段1位置,还能更新其他字段位置,可以使用MaxBy

3.6 Reduce算子:更加一般化的聚合操作
自己写个实现ReduceFunction接口的对象,重写reduce方法。

3.7 Split与Select算子
Split与Select是一组“形影不离”的算子组,使用完Split后,要用Select进行选择。Split算子实现的功能主要是将一条流中的数据按某个条件打上相应的标签,注意:并不是切分成两条流,实质上还是一条流,它是在一条流内打上不同的标签。

到IDEA中点开.split()方法查看需要实现的接口
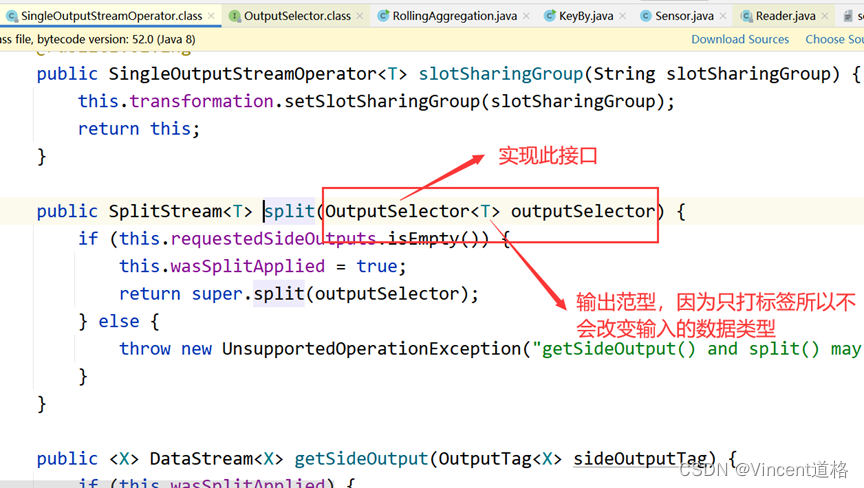
SplitDemo,注:迭代器是依赖于列表和集合存在的,故方法中与其说要求返回迭代器,不如说要求返回可迭代的数据类型。
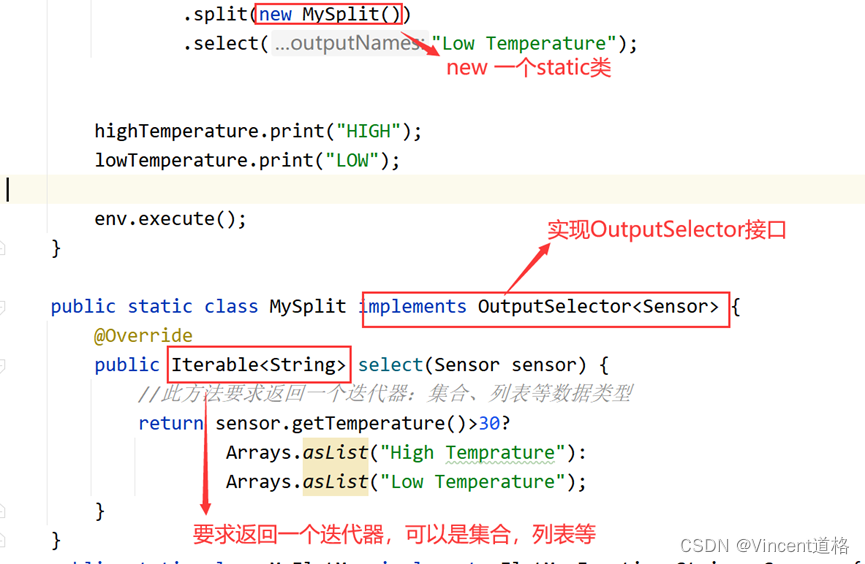
Split打完标签后,进行select操作,选择相应标签的一类数据作为新流

运行结果

3.8 Connect与CoMap、CoFlatMap(缺陷:只能链接两条流)
与3.7Split相反,Connect做的是将两条数据类型不同的流合并为一条数据类型相同流。
但若只是经过Connect算子处理的话,还不能实现真正意义上的合并为一条流。
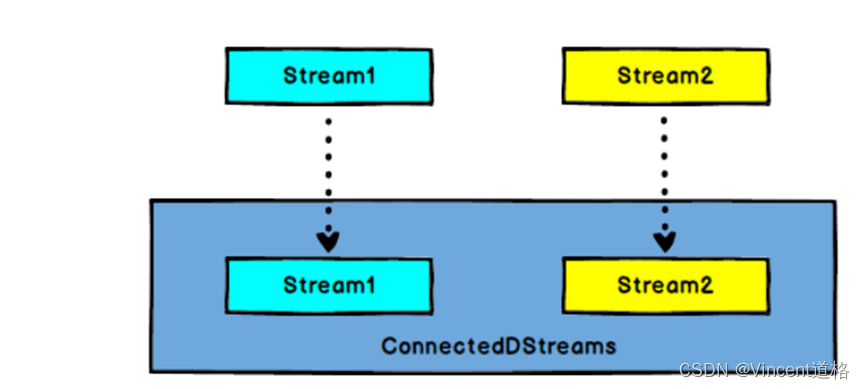
必须之后跟上与之对应的CoMap、CoFlatMap算子操作,只有这样才能真正实现合并为一条数据类型相同的流

ConnectAndCoMap实例
-
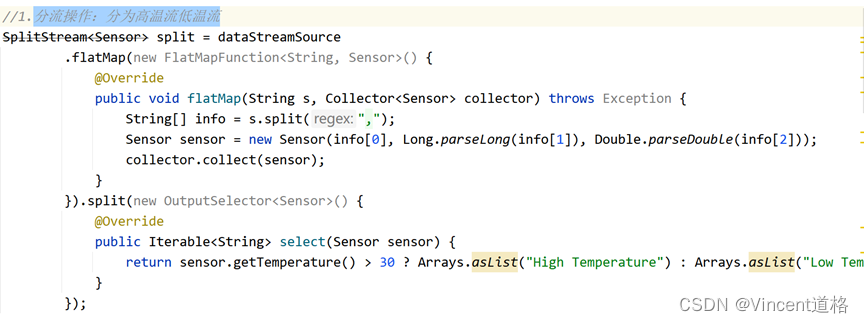
分流操作:分为高温流低温流
-
将高温流转换为二元组,为了实现和低温流有不相同的数据类型

-
合流操作

结果

3.9 Union算子(多留合并,要求数据类型相同)
Union可以做多流合并,但带合并的多条流只能是数据类型相同的流。
Split和Select、Connect和CoMap、Union这三种算子统称为多流转换算子
4. Sink
4.1 将数据流注入到Kafka
此例将实现从Kafka消费数据,在Flink端做个简单转换后把数据注入到Kafka中,实现一个简单的数据管道。
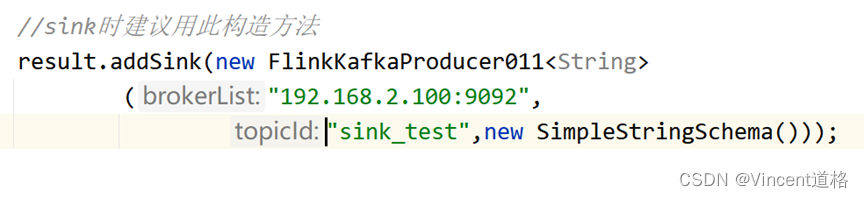
写代码的时候由于Kafka连接器的Maven依赖的Flink版本和我Linux上的flink版本不一致,导致报错:

要注意引入第三方中间件的依赖时,要和Flink版本统一,修改后成功解决

效果如下:D:\Tencent\TencentFile\757089512\FileRecv\KafkaToKafka.mp4
4.2 JDBC
因为JDBC涉及数据库连接和语句预处理等操作,所以需要获取上下文配置信息,由此可以想到使用富含数(包含上下文环境的函数)

注意:invoke方法是SinkFunction的主要执行方法,将数据注入到其他第三方工具依赖于此方法。
















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









