







一、environment

- getExecutionEnvironment
getExecutionEnvironment会根据查询运行的方式决定返回什么样的运行环境,是最常用的一种创建执行环境的方式
val env:ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
二、source
- 从集合读取数据
//2.从集合中读取数据
val dataList = List(
SensorReading("sensor_1", 1547718199, 35.8),
SensorReading("sensor_6", 1547718201, 15.4),
SensorReading("sensor_7", 1547718202, 6.7),
SensorReading("sensor_10", 1547718205, 38.1)
)
val stream = env.fromCollection(dataList)
stream.print()
- 从文件读取数据
//2.从文本文件中读取数据
val datapath = "E:\\study\\IdeaProjects\\FlinkTutorial\\src\\main\\resources\\sensorreading"
val txtDataStream = env.readTextFile(datapath)
txtDataStream.print()
- 以kafka消息队列的数据作为来源
步骤1:
在pom.xml中,需要引入 kafka 连接器的依赖:
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.11 --><dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
步骤2:
//2.从kafka中读取数据
val properties = new Properties()
properties.setProperty("bootstrap.servers", "hadoop102:9092,hadoop103:9092,hadoop104:9092")
properties.setProperty("group.id", "consumer-group")
val kafkaStream = env.addSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties))
kafkaStream.print()
步骤3:
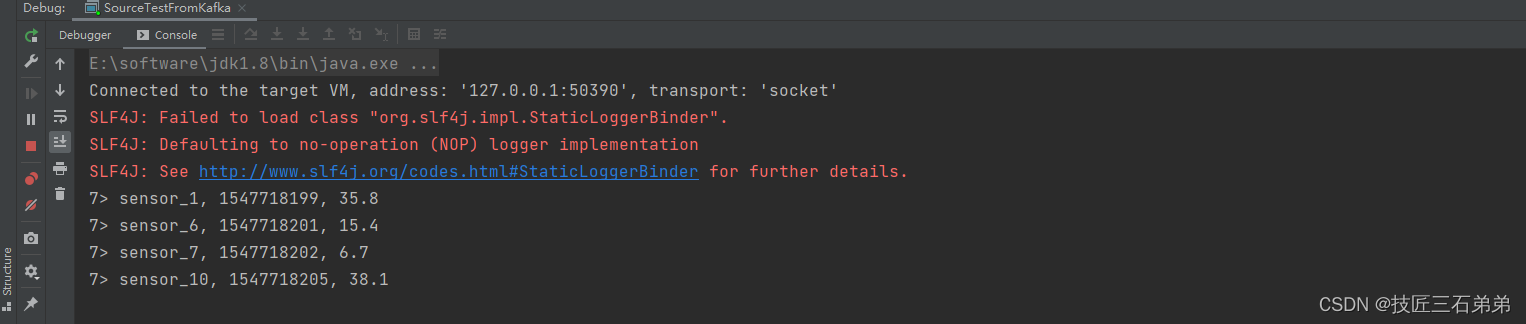
[yili@hadoop102 kafka_2.11-2.4.1]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic sensor
>sensor_1, 1547718199, 35.8
>sensor_6, 1547718201, 15.4
>sensor_7, 1547718202, 6.7
>sensor_10, 1547718205, 38.1
结果:
- 自定义source
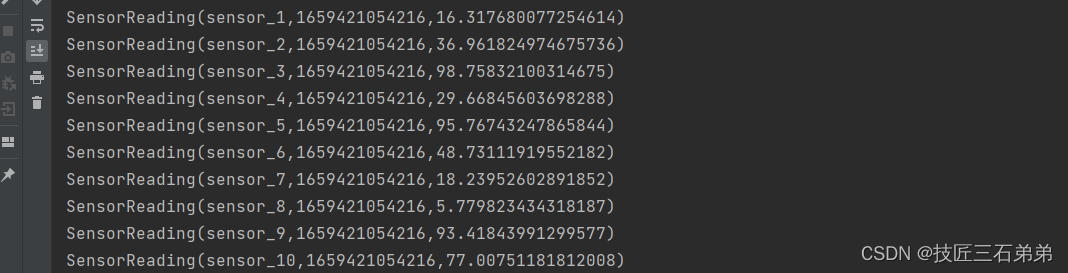
//2.自定义source
val stream = env.addSource(new MySensorSource())
stream.print()
//自定义source function
class MySensorSource() extends SourceFunction[SensorReading] {
var running = true
override def run(sourceContext: SourceFunction.SourceContext[SensorReading]): Unit = {
//定义一个随机数生成器
val random = new Random()
//随机生成一组(10个)传感器的初始温度(id,temp)
var curTemp = 1.to(10).map(i => ("sensor_" + i, random.nextDouble() * 100))
while (running) {
//在上次温度基础上更新温度值
curTemp.map(
data => (data._1, data._2 + random.nextGaussian())
)
//获取当前时间戳,加入到数据中,调用sourceContext.collect发出数据
val curTime = System.currentTimeMillis()
curTemp.foreach(data => sourceContext.collect(SensorReading(data._1, curTime, data._2)))
//间隔500ms
Thread.sleep(500)
}
}
override def cancel(): Unit = running = false
}
三、Transform
- map

val dataStream = inputStream
.map(data => {
val arr = data.split(",")
SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
})
- flatMap
略
- filter

略
- keyBy
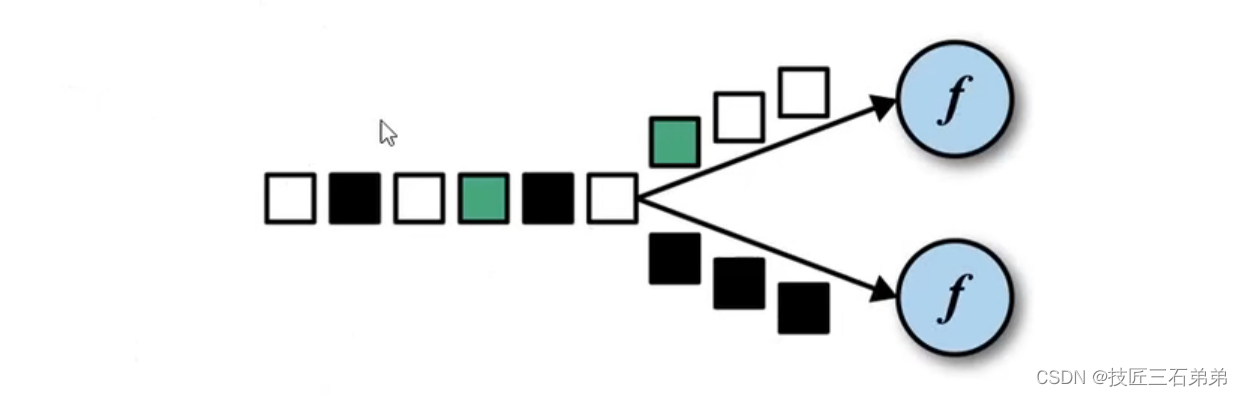
DataStream -> KeyedStream:逻辑地将一个流拆分成不相交的分区,每个分区包含具有相同key的元素,在内部以hash的形式实现的。
val aggStream = dataStream
.keyBy("id")
//.min("temperature")
.minBy("temperature")
- 滚动聚合算子(Rolling Aggregation)
这些算子可以针对KeyedStream的每一个支流做聚合。
(1)sum()
(2)min()
(3)max()
(4)minBy()
(5)maxBy() - Reduce
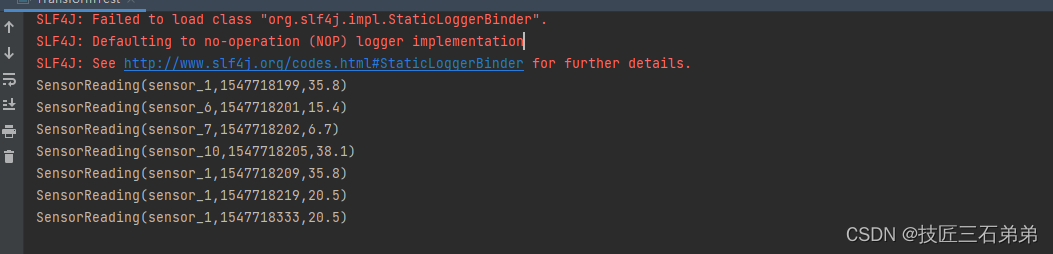
//需要输出当前最小的温度值,以及最近的时间戳,要用reduce
val resultStream = dataStream
.keyBy("id")
.reduce((curState, newData) => SensorReading(curState.id, newData.timestamp, curState.temperature.min(newData.temperature)))
resultStream.print()
结果展示:
- Split和Select
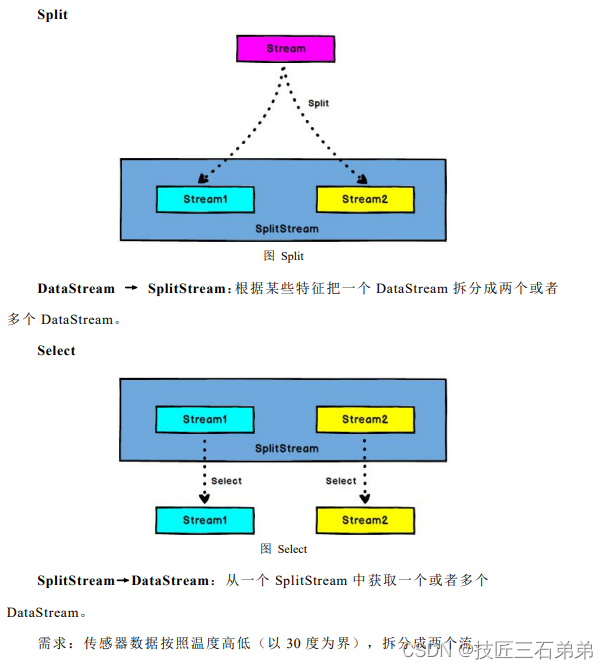
val splitStream = dataStream
.split(sensorData => {
if (sensorData.temperature > 30) Seq("high") else Seq("low")
})
val highTempStream = splitStream.select("high")
val lowTempStream = splitStream.select("low")
val allTempStream = splitStream.select("high", "low")
highTempStream.print("high")
lowTempStream.print("low")
allTempStream.print("all")
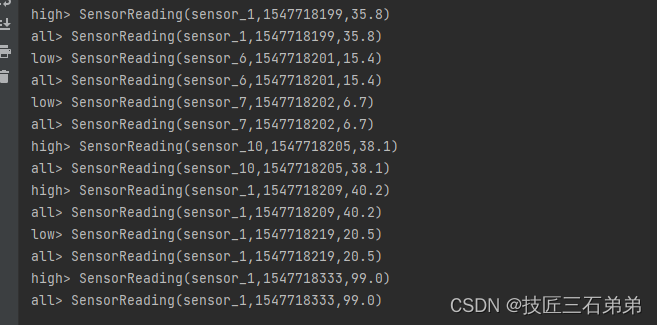
结果:
8. Connect和CoMap
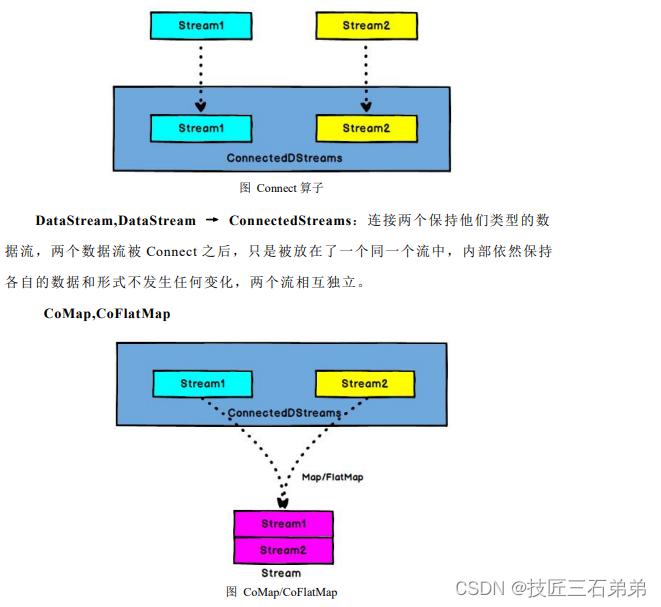

//合流,connect
val warningStream = highTempStream.map(data => (data.id, data.temperature))
val connectedStreams = warningStream.connect(lowTempStream)
//用coMap对数据进行分别处理
val coMap = connectedStreams.map(
warningData => (warningData._1, warningData._2, "warning"),
lowData => (lowData.id, "healthy")
)
coMap.print()
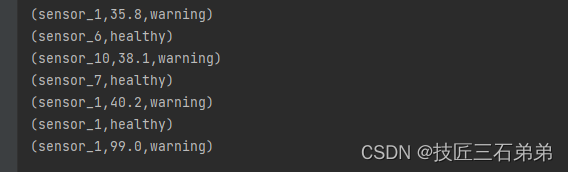
结果:
9. Union
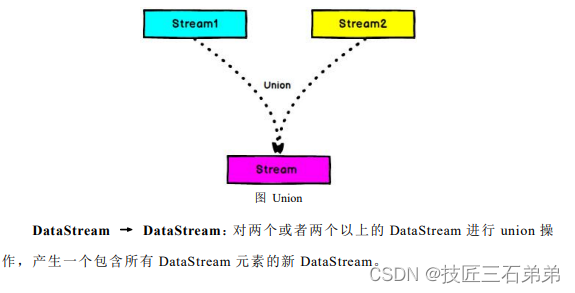
//union合流
val unionStream = highTempStream.union(lowTempStream)
四、支持的数据类型
- 函数类
val dataStream = inputStream
.map(data => {
val arr = data.split(",")
SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
})
.filter(new MyFilter)
//自定义一个函数类
class MyFilter extends FilterFunction[SensorReading] {
override def filter(t: SensorReading): Boolean =
t.id.startsWith("sensor_1")
- 匿名函数
val tweets: DataStream[String] = ...
val flinkTweets = tweets.filter(_.contains("flink"))
- 富函数
未完待续,敬请期待…















 97
97











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









