







 本文分析了来自Kaggle的YouTube数据,针对CA国家的热门视频进行预处理和探索性分析。通过描述性分析、相关性分析及gropby分组函数,揭示了浏览量最多的频道、类别频率以及浏览量与点赞数的强正相关性。结论显示,Music、Entertainment和Movies类别最受关注。
本文分析了来自Kaggle的YouTube数据,针对CA国家的热门视频进行预处理和探索性分析。通过描述性分析、相关性分析及gropby分组函数,揭示了浏览量最多的频道、类别频率以及浏览量与点赞数的强正相关性。结论显示,Music、Entertainment和Movies类别最受关注。
YouTube热门视频的分析
1 概述
Youtube视频网站是美国最大的视频分享平台,youtube官网在中国也有很多用户。数据来源于kaggle网站,本文主要选取CA国家,探究YouTube在CA国家Top20热门视频数据。
2 数据的预处理
1、导包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt`
import seaborn as sns
import json
from datetime import datetime
import pandas as pd
data = pd.read_csv("3D Objects/CAvideos.csv",index_col=0)
2、查看数据集
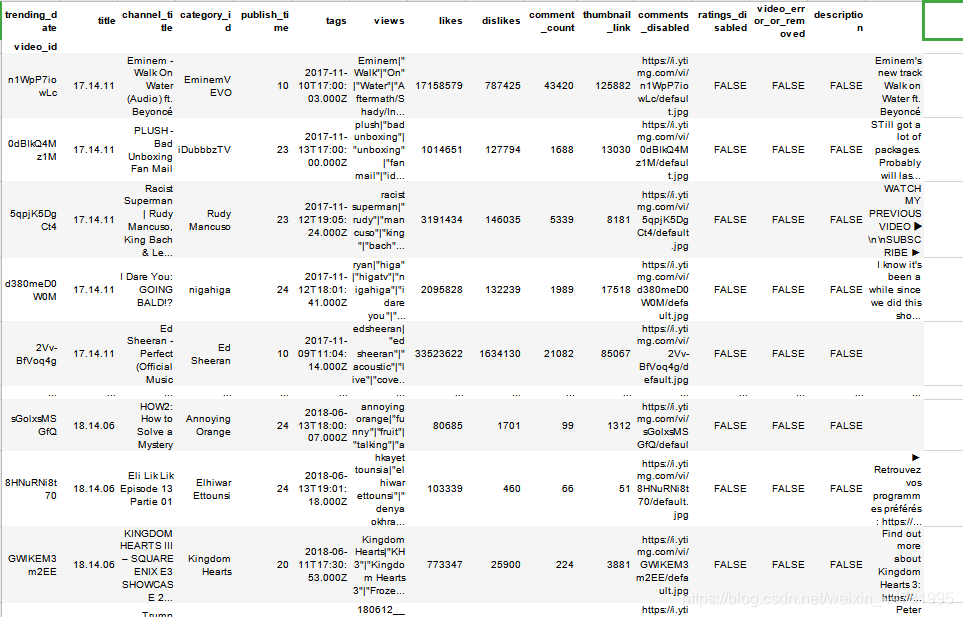
data
data["trending_date"]``
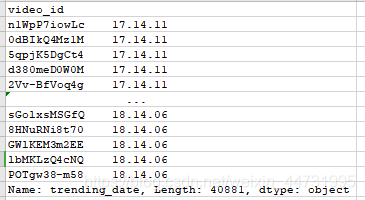
我们发现trending_date日期格式不一样,所以要对其进行日期格式的转化,这里我们用到datetime函数
data["trending_date"] = pd.to_datetime(data["trending_date"],format ="%y.%d.%m")
同理pubulish_time也一样
data["publish_time"] = pd.to_datetime(data["publish_time"],format = "%Y-%m-%dT%H:%M:%S.%fZ")
data["category_id"] = data["category_id"].astype(str)#转换成字符型
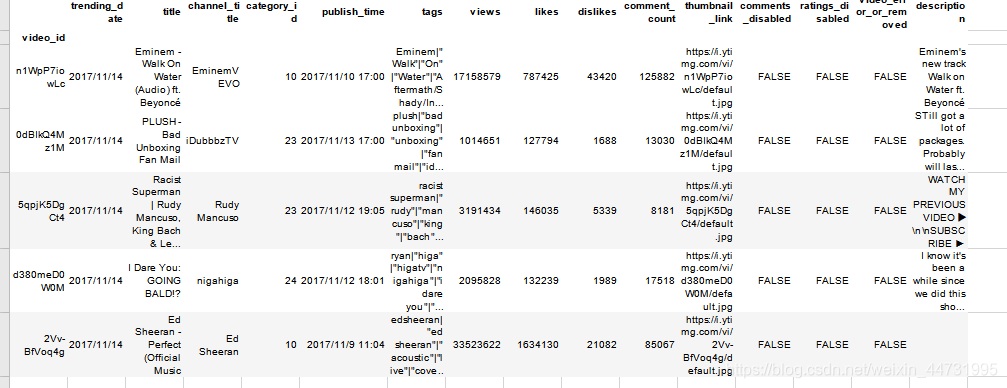
处理后的data
data.head()
对数据进行简单描述:
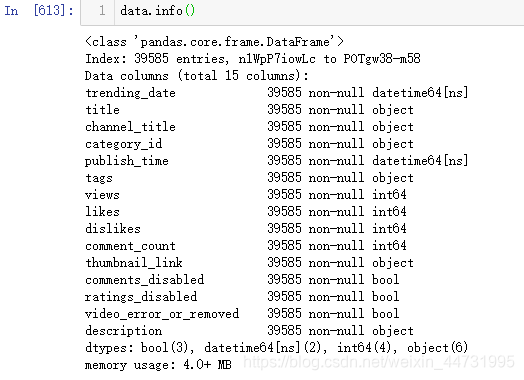
data.info()
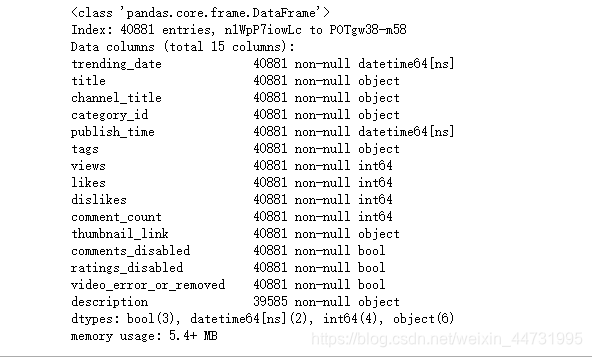
从数据的初始描述可以得出该数据总共有15个指标,共有40881行记录
,且description有缺失值。
由于数据原本量就很大,且缺失的数占少数,因此可以对数据有缺失的行进行删除。
data = data.dropna()#删除有缺失值的行
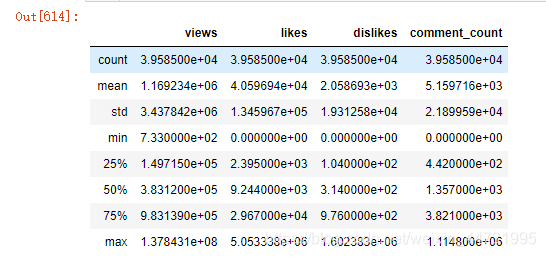
通过对缺失值的处理,我们得到我们的完整的数据集。接下来我们对数据集中数值型变量做一个描述数据表,得到最初的对数据集的了解
接下来我们导入json文件,让其与category匹配
id_to_category = {
}
with open (r"C:\Users\Desktop\4549_466349_bundle_archive/CA_category_id.json") as f:
js = json.load(f)
for category  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









