







 本文介绍了类不平衡数据问题及其对分类算法的影响,特别是决策树分类器。SMOTE算法作为一种过采样方法,通过在少数类样本与其近邻之间创建新样本来增加数据量,从而避免过拟合。实验证明,SMOTE处理后的决策树模型在乳腺癌数据集上的分类准确率显著提高,证实了SMOTE在提升类不平衡数据分类准确率上的有效性。
本文介绍了类不平衡数据问题及其对分类算法的影响,特别是决策树分类器。SMOTE算法作为一种过采样方法,通过在少数类样本与其近邻之间创建新样本来增加数据量,从而避免过拟合。实验证明,SMOTE处理后的决策树模型在乳腺癌数据集上的分类准确率显著提高,证实了SMOTE在提升类不平衡数据分类准确率上的有效性。
类不平衡数据分类准确率的提升算法smote过采样方法
1.1概述
传统的分类算法是基于精度驱动的,即算法的目标是最小化分类误差,它假定:假正例(FP)和假负例(FN)错误的代价是相等的。这个假定是基于类平衡分布和相等的错误代价,即数据集中各个类的样本数都很接近。但是实际问题中我们遇到的大部分数据集往往是类不平衡的。例如:在疾病预测的问题中,患病的人数一般远远小于非患病的人数。在一般的分类算法下,往往会忽略小类样本(患病者)所带来的误差,它可能会把所有的样本都预测成非患病者。但是人们关注的重点是患病者的分类结果,类似的还有欺诈信用卡检测等问题。
针对上诉问题,对于类不平衡数据集的分类问题需要寻求一种新的方法加以解决。目前基于提升类不平衡数据集分类的准确率的处理方法分为两种:a)对数据进行预处理进行欠采样或者过采样等处理;b)对算法进行改进,使其对少数类更加敏感。其中欠采样和过采样是常用的两种处理类不平衡数据的方法。欠采样是从多数类样本中随机选择少量样本,再合并原有少量样本作为新的训练数据集。与欠采样相反,过采样是从少数样本中进行随机采样来增加新的样本。但是欠采样的方法只是使用了大类中的一个子集,忽略了数据的有效信息;而过采样通常会带来增加计算量,过拟合等问题
1.2 类不平衡数据smote分类算法
数据预处理类不平衡数据中最经典的算法是Synthetic Minority Oversampling Technique (smote)算法,smote算法是过采样中比较常用的一种算法。它是对随机过采样方法的一个改进,由于随机过采样方法是直接对少数类重新进行采样,这样会使训练集中有很多重复的样本,容易造成产生的模型过拟合问题。而它是通过在样本与其近邻的连线上随机选一个点作为新样本的方式来增加样本数据量。其合成新少数类样本的算法描述如下:
1).对于少数类中的每一个样本x,计算它到少数类样本集中所有样本的欧氏距离,得到其k近邻。
2).根据样本不平衡比例设置一个采样平衡比例以确定采样倍率N,对于每一个少数类样本,从其k近邻中随机选择若干个样本,假设选择的近邻是。
3).对于每一个随机选出来的近邻,分别与原样本按照如下公式构建新的样本
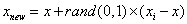
前面我们已经对提升类不平衡数据smote算法进行了介绍,为了了解提升的效果,接下来我们利用sklearn中自带的二分类数据breast_cancer(乳腺癌)数据集作为实验数据分别建立普通决策树分类器模型和经过过采
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3889
3889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









