









《程序设计(Python)》报告
sklearn线性回归预测
基于欧盟就业和活动的数据分析预测报告
一、数据描述
1、数据来源:
数据是在欧统局的数据库中关于1992年至2020年欧盟按各个国家、不同性别、年龄段来标识的年度就业和活动数据。
2、数据获取:
在欧统局数据库中获取了原始的TSV文件,并经初步处理后存于csv文件中。
3、数据种类:
年龄段:ageYa-Yb(a岁到b岁)
统计单位:总人数THS_PER、百分比PC_POP
性别:女性F、男性M
活动状态:在职的ACT、总就业的EMP_LFS
国家/地区:
年份:2020-1992年(降序)
总人数=常住人口数
百分比=实际的/总人数(百分号省略)
年龄段主要反映的是社会中劳动力的纵向分布,性别则是劳动力的横向分布;国家地区的情况则是空间分别,年度统计的就是时间分布;总人口数(基于常住人口)则表示一个国家或者地区的劳动力资源情况、直接反映该地区劳动力是否雄厚,而百分比则反映劳动力的实际利用情况,百分比=实际人口/总人口。
4、使用工具:
语言:Python
特点:Python的设计哲学强调代码的可读性和简洁的语法(尤其是使用空格缩进划分代码块,而非使用大括号或者关键词),相比于C++或Java,Python让开发者能够用更少的代码表达想法。不管是小型还是大型程序,该语言都试图让程序的结构清晰明了,现在的大数据分析、挖掘以及机器学习等都使用Python进行实现,面对信息量巨大、复杂度越来越高的数据,使用起来就很方便了。
5、数据主要内容
通过这近年来的数据,对社会中的劳动力资源,从时空角度、横纵向角度、基数和比例的角度,能够系统、客观的认识当下社会的劳动力、就业趋势。
该数据主要是统计的欧盟自1992年到2020年的实际就业、活动数据,动态地记录了劳动资源的分布情况;我们可以通过该数据对已经实际发生并客观存在的社会现象进行可视化分析,客观地认识西方社会的真实情况,进一步希望我们可以通过可视化的数据对比于当下我国的就业形式、以及对未来趋势的预判,达到自我认知的更新、提醒自己的未来的计划,反观我们的就业形式,从而制定适合自己成长计划,也可以为我们的社会提供决策参考,尤其是在国家进一步深化改革上,我们作为未来的参与者,把握这方面的技术也是非常必要的;最后通过这个项目进一步学习更多的技术。
二、数据预处理
通过在Excel对文件的初步观察,发现这样的数据类型比较繁杂,不利于计算机的读取和处理,尤其是数据记录的前两年,空白、无效数据比较多;所以我们第一步应该对数据进行预处理,将数据打开读入后,选择性地输出关键信息,方便后面数据的处理;然后对空白处进行处理,确保数据的可读性、便捷性、合理性。
1.首先导入代码所需库
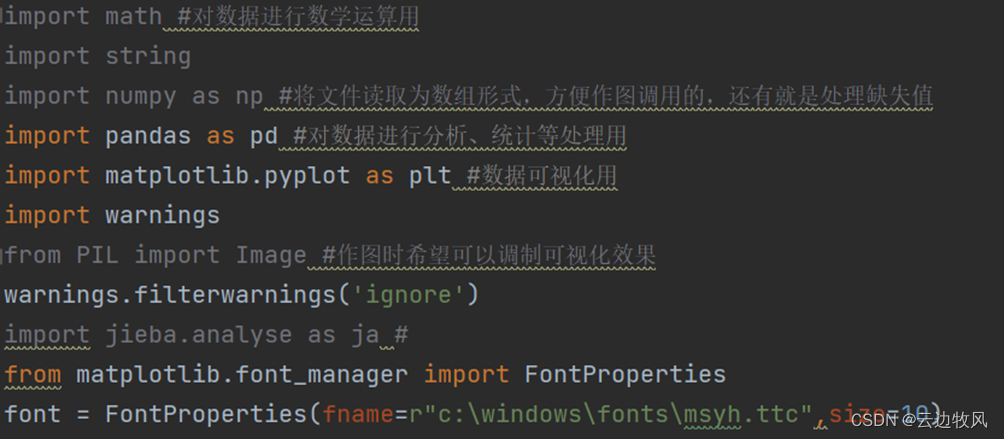

2.数据:确认编码、读入
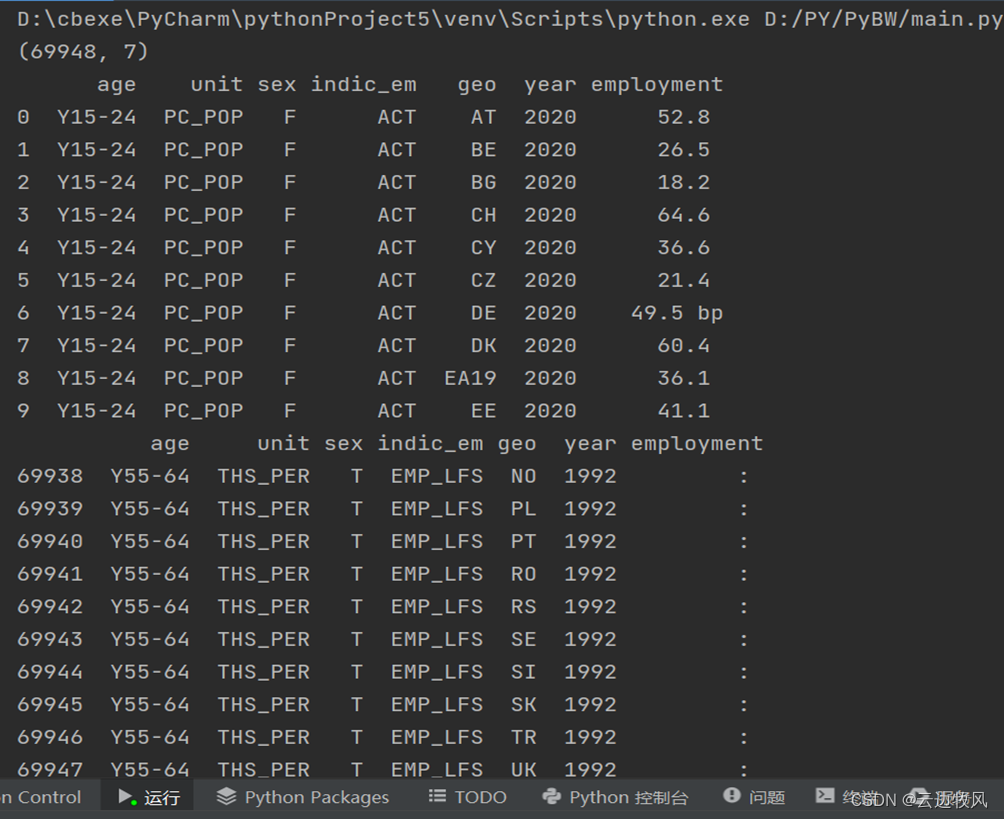
效果展示:
3.数据处理
将数据按照国家进行筛选
效果展示:
三、数据分析
1、缩小区间
由于数据太多,我们需要进行区间的缩小,先访问指定国家/地区不同人群的数据:
效果展示(以查询英国为例):
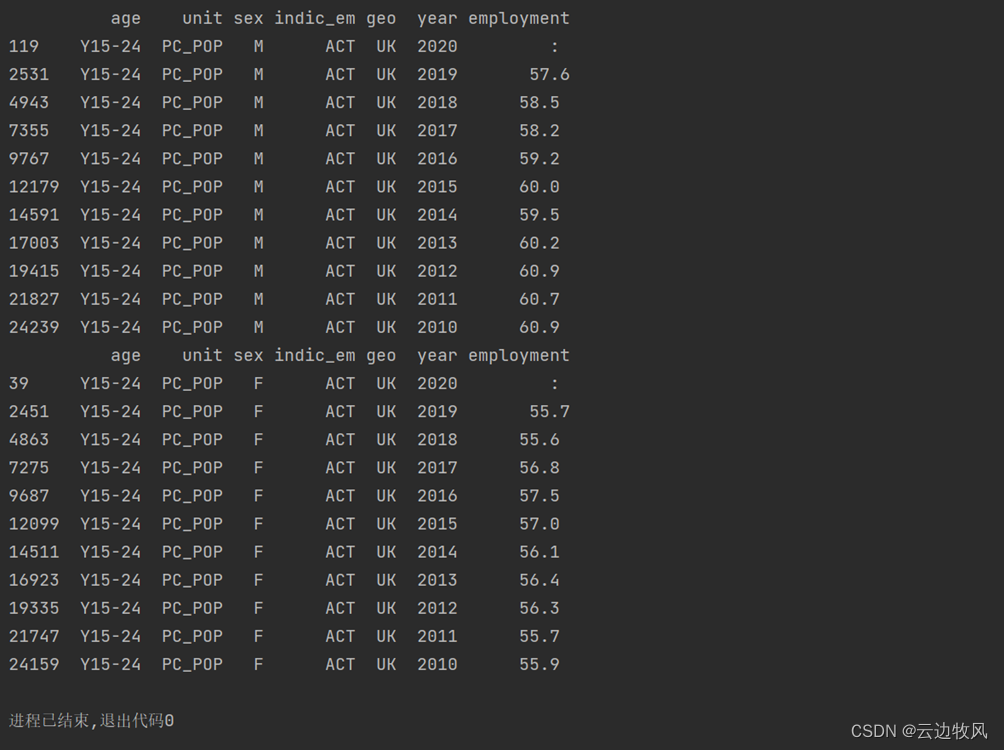
2、筛选出指定国家的男性和女性在15-24岁年龄段的在职数据:
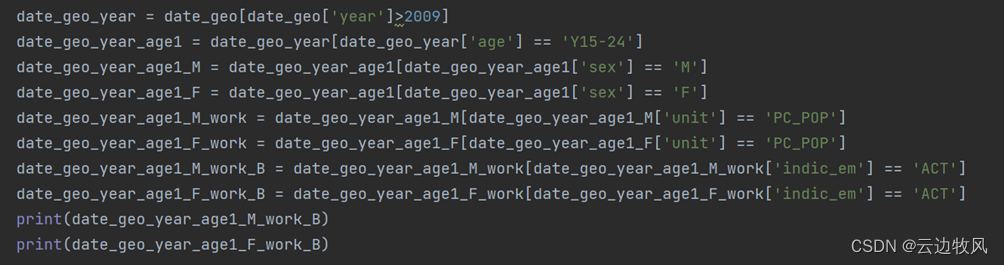
效果展示:

四、数据可视化展示
在筛选好某个国家(英国-UK)后,将其近二十年的数据进行可视化处理
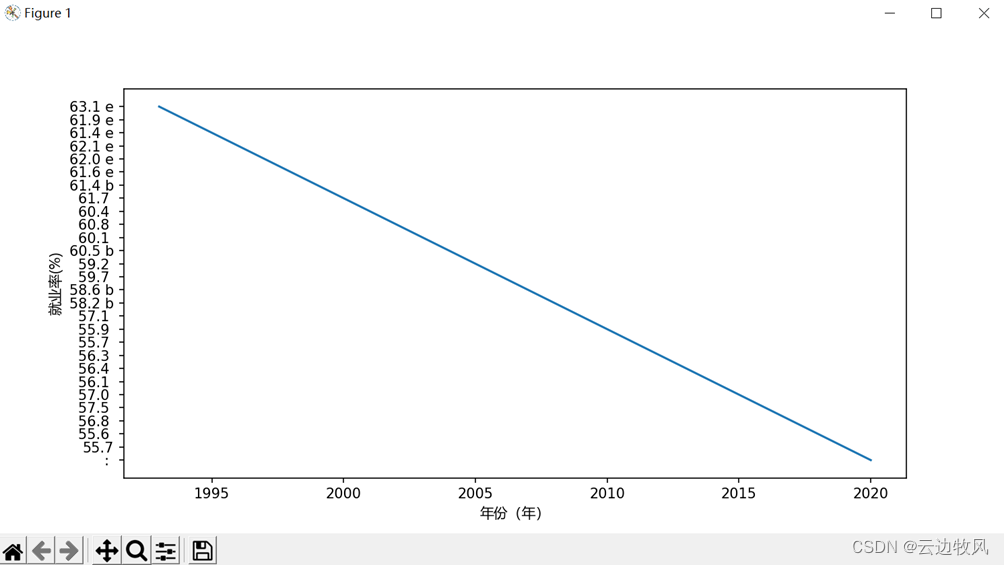
1、男性就业数据的折线图
代码显示
效果展示:
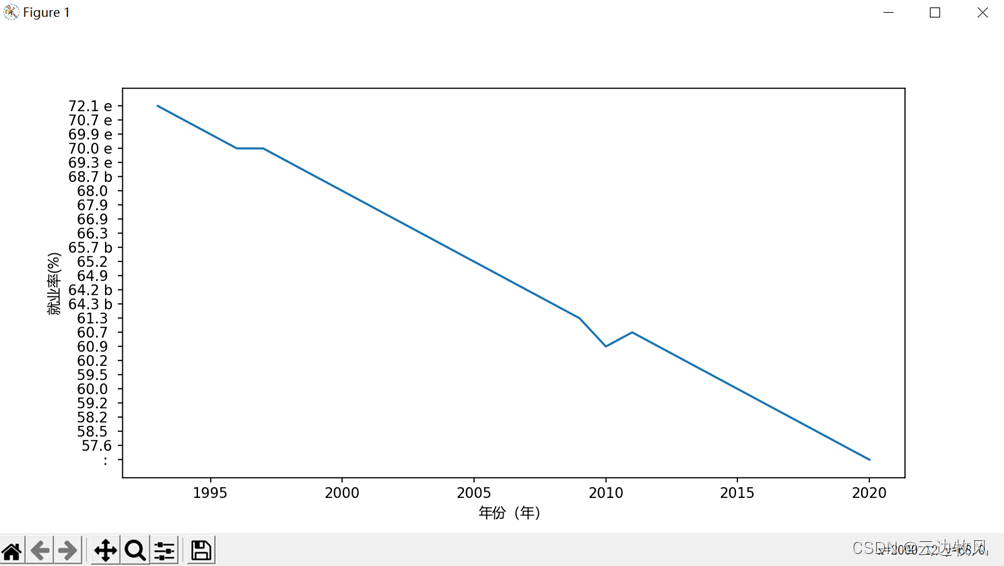
通过左边的Y轴不难看出,数值是在下降的,即就业形势逐渐严峻!!!
2、折线柱状图
效果展示:
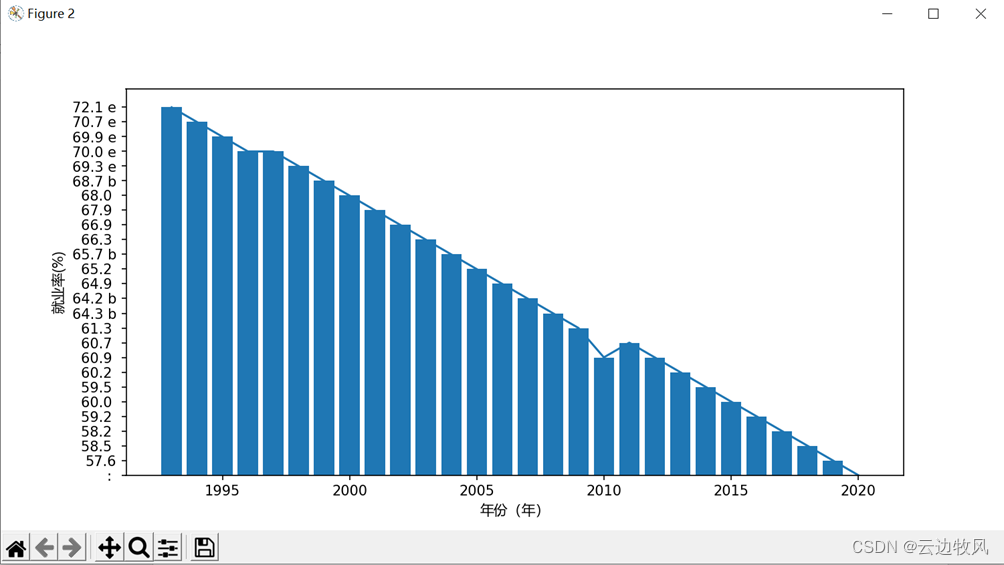
数值在下降!!!
3、再看看女性这边的情况
效果展示:
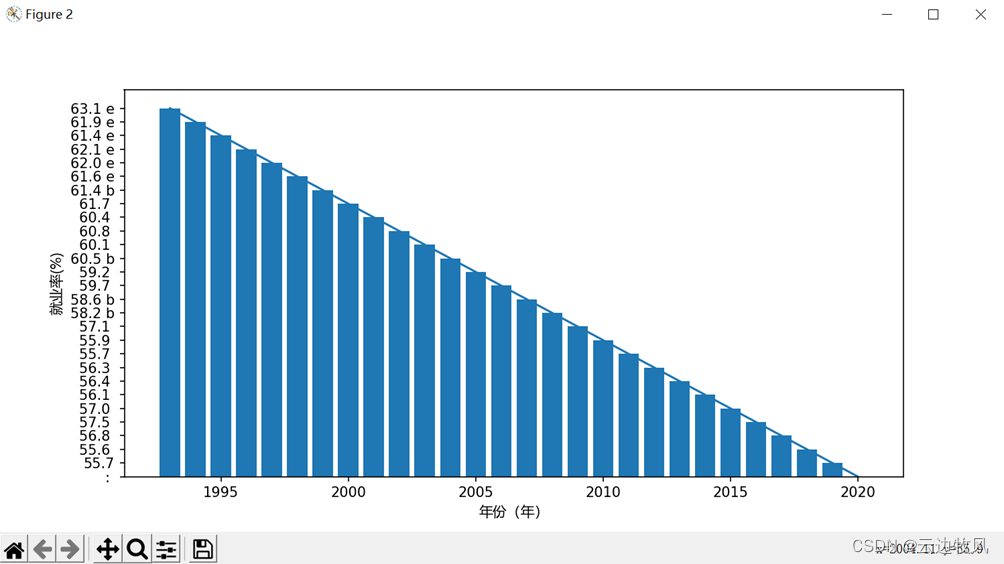
4、前面的123都是进行的纵向分析,面对这样丰富的数据,我们还可以进行横向的比较分析,也就是说我们把同一时间段的男性、女性以及整个欧盟的国家进行可视化,就能更加清楚地看出趋势了

效果展示:

不难看出,近二十年的欧盟即其国家的男和女性,就业率一直在下降,而且女性的普遍低于欧洲整体水平,而我们所选的英国,情况则比较乐观,水平一直都在欧盟整体前面。
5、已有的数据,都可以通过上面的方法进行我们想要的可视化展示了,但是似乎还不够深入;为此,我们需要进一步处理---预测!
在判断能否使用sklearn进行处理前,我们先进行可行性判断,即我们通过散点图来验证


效果展示:
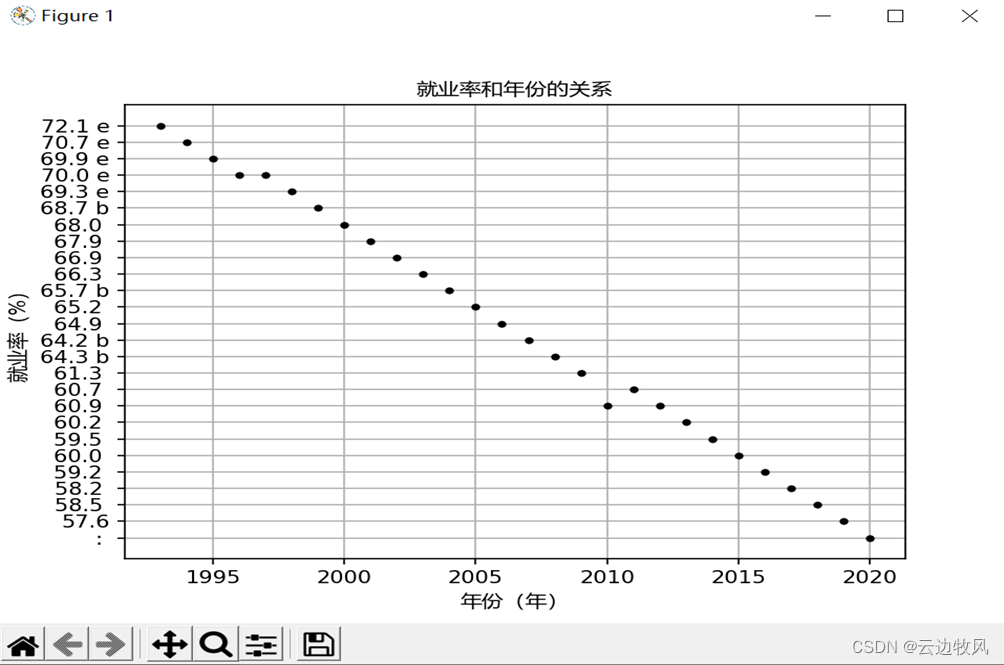
通过散点图不难看出,这类数据是能够建立起sklearn模型的。
6、为此,我使用的是机器学习的sklearn库里的线性回归器,将数据的年份和就业率导入模型进行训练,随后预测出未来十年的就业率。
代码展示

效果展示:
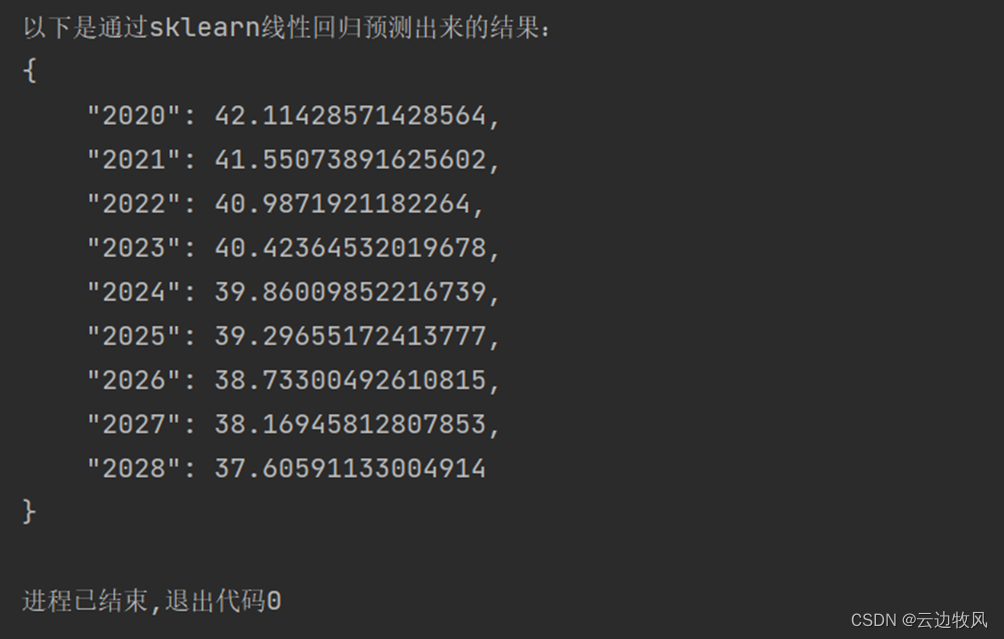
通过结果的打印显示得到,未来的就业率依旧是下降的趋势
通过对数据的可视化分析,得出以下结论:
-
欧盟国家的男女就业率在逐渐地下降
-
男性的就业率虽然普遍比女性高,但波动和下降的幅度也较大;反观女性的就业率,虽然也是在下降,但是总体水平是在稳定地缓慢下降。
-
通过预测,欧盟国家整体及其成员国的男性和女性,就业率在逐年下降,并且在2030年前后,就业率会降到历史最低。
通过访问欧统局,得到的结论依旧是就业形势严峻,大部分欧盟国家的就业率都是在逐年波动中下降的,并且我们预测的2020年就业率比较接近。
启示:在前面的二十年里面,没有疫情冲击的情况下,社会的就业率就已经在下降,原因包含了劳动力迁移、社会保障机制存在弊端外,劳动力的竞争也越来越激烈;反观我们当下又何尝不是如此,即劳动人口虽然在上升、工作时间也随着寿命的增长而延长,但也带来了社会就业的竞争日益加剧、失业风险越来越严峻;所以作为当下的我们,也需要面临这样的社会发展趋势,做好当下,努力提升自己。
五、遇到的问题与解决方法
1、问题:在一开始进行数据预处理的时候,没有弄清文件的读写性质,导致在读的逻辑上尝试改变数据的值,一直没能保存到文件中
解决:通过请教老师后发现问题所在,最后通过翻阅书籍,更加深入地理解了pandas下的数据处理。
- 问题:画图时想在图里面显示中文,程序却一直报错
解决:网上找到了关于matplotlib的修改使用,即原软件包里没有中文的编码,我们就修改参数,让它直接使用系统自带的微软字体包,代码是这样的font = FontProperties(fname=r"c:\windows\fonts\msyh.ttc",size=10)
- 调用sklearn的时候,系统出现路径错误
解决:卸载原函数库,再对环境变量进行修改,改为没有中文路径的,以及安装的包需要放在解释器一个路径里面,不能出现解释器在D盘而把软件包装到C盘里面(原因可能是因为C盘里的用户名一般都有中文的原因吧)
六、学习总结与反思
七、源代码
import numpy as np #将文件读取为数组形式,方便作图调用的,还有就是处理缺失值
import pandas as pd #对数据进行分析、统计等处理用
import matplotlib.pyplot as plt #数据可视化用
from matplotlib.font_manager import FontProperties
from sklearn.linear_model import LinearRegression
import json
font = FontProperties(fname=r"c:\windows\fonts\msyh.ttc",size=10)
def runplt(size=None):
plt.figure(figsize=size)
plt.title('就业率和年份的关系',fontproperties=font)
plt.xlabel('年份(年)',fontproperties=font)
plt.ylabel('就业率(%)',fontproperties=font)
plt.grid(True)
return plt
def is_number(s):
try: # 如果能运行float(s)语句,返回True(字符串s是浮点数)
float(s)
return True
except ValueError: # ValueError为Python的一种标准异常,表示"传入无效的参数"
pass # 如果引发了ValueError这种异常,不做任何事情(pass:不做任何事情,一般用做占位语句)
try:
import unicodedata # 处理ASCii码的包
unicodedata.numeric(s) # 把一个表示数字的字符串转换为浮点数返回的函数
return True
except (TypeError, ValueError):
pass
return False
if __name__ == '__main__':
date = pd.read_csv('D:\PY\lfsi_emp_a_h.csv', encoding='utf-8')
print(date.shape)
print(date.head(n=10))
print(date.tail(n=10))
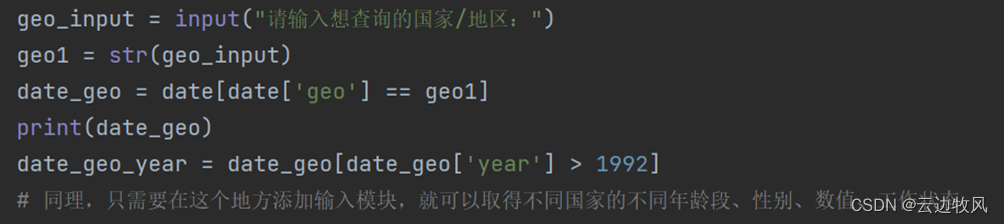
geo_input = input("请输入想查询的国家/地区:")
geo1 = str(geo_input)
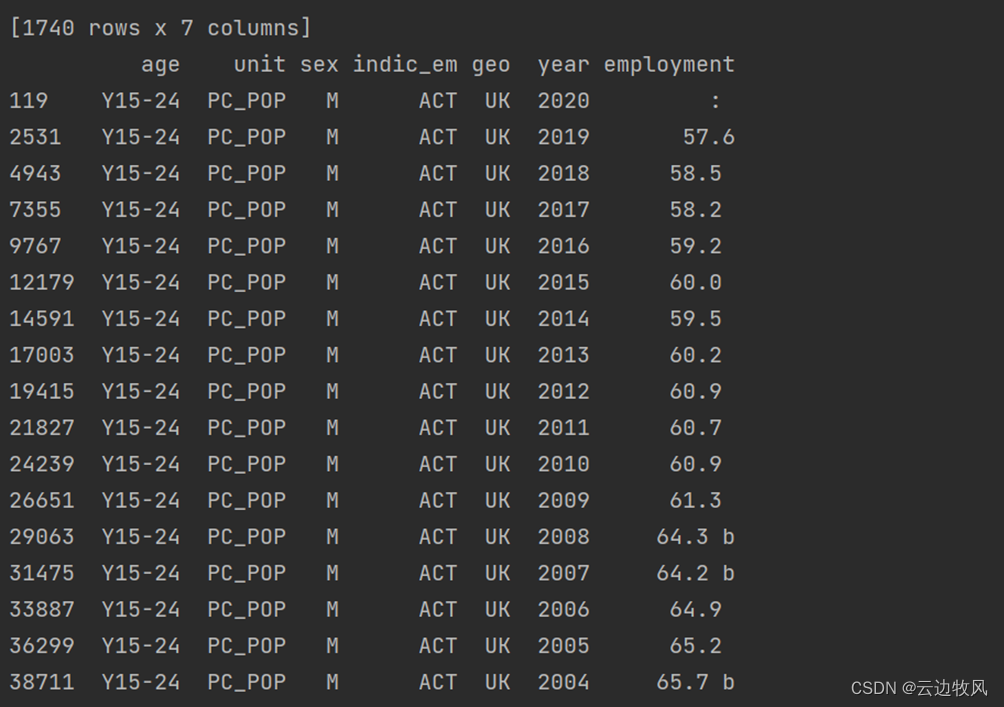
date_geo = date[date['geo'] == geo1]
print(date_geo)
date_geo_year = date_geo[date_geo['year'] > 1992]
# 同理,只需要在这个地方添加输入模块,就可以取得不同国家的不同年龄段、性别、数值、工作状态
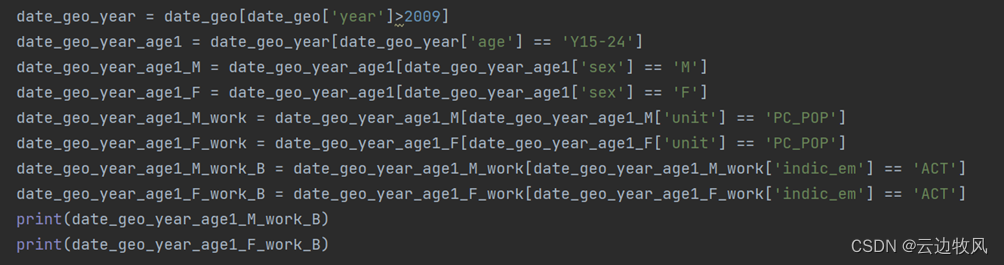
date_geo_year_age1 = date_geo_year[date_geo_year['age'] == 'Y15-24']
date_geo_year_age1_M = date_geo_year_age1[date_geo_year_age1['sex'] == 'M']
date_geo_year_age1_F = date_geo_year_age1[date_geo_year_age1['sex'] == 'F']
date_geo_year_age1_M_work = date_geo_year_age1_M[date_geo_year_age1_M['unit'] == 'PC_POP']
date_geo_year_age1_F_work = date_geo_year_age1_F[date_geo_year_age1_F['unit'] == 'PC_POP']
date_geo_year_age1_M_work_B = date_geo_year_age1_M_work[date_geo_year_age1_M_work['indic_em'] == 'ACT']
date_geo_year_age1_F_work_B = date_geo_year_age1_F_work[date_geo_year_age1_F_work['indic_em'] == 'ACT']
print(date_geo_year_age1_M_work_B)
print(date_geo_year_age1_F_work_B)
# 以下这个是筛选整个欧盟的部分
date_geo1 = date[date['geo'] == 'EU28']
date_geo1_year = date_geo1[date_geo1['year'] > 1992]
date_geo1_year_age1 = date_geo1_year[date_geo1_year['age'] == 'Y15-24']
date_geo1_year_age1_M = date_geo1_year_age1[date_geo1_year_age1['sex'] == 'M']
date_geo1_year_age1_F = date_geo1_year_age1[date_geo1_year_age1['sex'] == 'F']
date_geo1_year_age1_M_work = date_geo1_year_age1_M[date_geo1_year_age1_M['unit'] == 'PC_POP']
date_geo1_year_age1_F_work = date_geo1_year_age1_F[date_geo1_year_age1_F['unit'] == 'PC_POP']
date_geo1_year_age1_M_work_B = date_geo1_year_age1_M_work[date_geo1_year_age1_M_work['indic_em'] == 'ACT']
date_geo1_year_age1_F_work_B = date_geo1_year_age1_F_work[date_geo1_year_age1_F_work['indic_em'] == 'ACT']
print(date_geo1_year_age1_M_work_B)
print(date_geo1_year_age1_F_work_B)
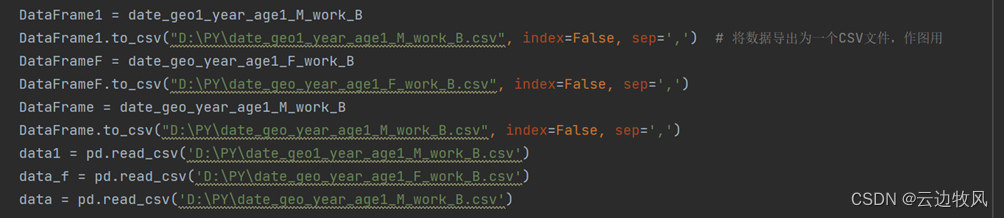
DataFrame1 = date_geo1_year_age1_M_work_B
DataFrame1.to_csv("D:\PY\date_geo1_year_age1_M_work_B.csv", index=False, sep=',') # 将数据导出为一个CSV文件,作图用
DataFrameF = date_geo_year_age1_F_work_B
DataFrameF.to_csv("D:\PY\date_geo_year_age1_F_work_B.csv", index=False, sep=',')
DataFrame = date_geo_year_age1_M_work_B
DataFrame.to_csv("D:\PY\date_geo_year_age1_M_work_B.csv", index=False, sep=',')
data1 = pd.read_csv('D:\PY\date_geo1_year_age1_M_work_B.csv')
data_f = pd.read_csv('D:\PY\date_geo_year_age1_F_work_B.csv')
data = pd.read_csv('D:\PY\date_geo_year_age1_M_work_B.csv')
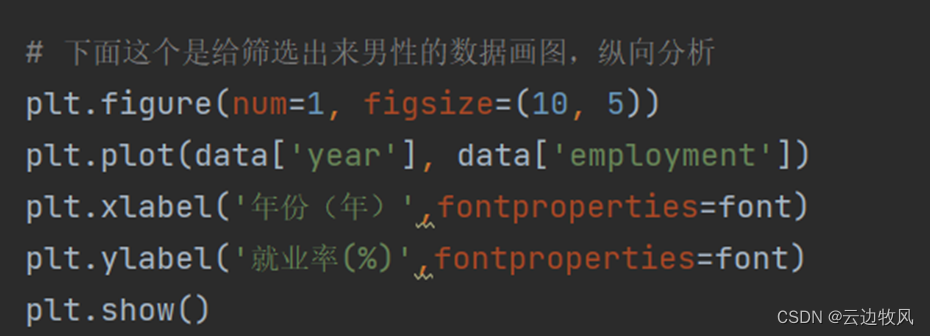
# 下面这个是给筛选出来男性的数据画图,纵向分析
plt.figure(num=1, figsize=(10, 5))
plt.plot(data['year'], data['employment'])
plt.xlabel('年份(年)', fontproperties=font)
plt.ylabel('就业率(%)', fontproperties=font)
plt.show()
plt.figure(num=2, figsize=(10, 5))
plt.xlabel('年份(年)', fontproperties=font)
plt.ylabel('就业率(%)', fontproperties=font)
plt.plot(data['year'], data['employment'])
plt.bar(data['year'], data['employment'])
plt.show()
# 下面这个是给筛选出来女性的数据画图,纵向分析
plt.figure(num=1, figsize=(10, 5))
plt.plot(data_f['year'], data_f['employment'])
plt.xlabel('年份(年)', fontproperties=font)
plt.ylabel('就业率(%)', fontproperties=font)
plt.show()
plt.figure(num=2, figsize=(10, 5))
plt.xlabel('年份(年)', fontproperties=font)
plt.ylabel('就业率(%)', fontproperties=font)
plt.plot(data_f['year'], data_f['employment'])
plt.bar(data_f['year'], data_f['employment'])
plt.show()
# 下面这个是把男性、女性、整个欧盟的画图出来,做的横向分析
plt.figure(num=3, figsize=(10, 5))
l1 = plt.plot(data['year'], data['employment'], label='the UK of M')
l2 = plt.plot(data1['year'], data1['employment'], color='red', linewidth=2.0, linestyle='--', label='the EU28')
l3 = plt.plot(data_f['year'], data_f['employment'], color='blue', linewidth=1.0, linestyle='-.',
label='the UK of F')
plt.legend(loc='upper right')
plt.xlabel('年份(年)', fontproperties=font)
plt.ylabel('就业率(%)', fontproperties=font)
plt.show()
# 下面是散点图de
plt = runplt()
plt.plot(data['year'], data['employment'], 'k.')
plt.show()
df = pd.DataFrame(data1)
df.hist(bins=6, figsize=(10, 5))
plt.show()
a = list()
for i in data1['year']:
a.append(i)
x = a[::-1]
b = list()
for i in data1['employment']:
if is_number(i):
b.append(float(i))
else:
b.append(60.0)
y = b[::-1]
X = np.array(x).reshape((-1, 1))
Y = np.array(y)
Model = LinearRegression().fit(X, Y)
y_pred = Model.predict(np.array(range(2021, 2030)).reshape((-1, 1)))
pred = dict(zip(range(2020, 2032), y_pred))
pred_Json = json.dumps(pred, ensure_ascii=False, indent='\t')
print('以下是通过sklearn线性回归预测出来的结果:')
print(pred_Json)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











