






1. LangChain框架
LangChain是一个用于构建基于大语言模型的应用框架,通过模块化设计简化了LLM与外部工具,数据源和复杂逻辑的集成。
连接能力
将多个LLM调用,工具调用或者数据处理步骤串联成工作流
数据感知
外部数据集成
支持连接数据库,API,解决LLM的知识截止问题
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(你的文件路径)
记忆管理
自动跟踪多轮对话历史,支持短期(内存,调包)或者长期(数据库)存储
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
langchain支持本地模型
2. 多模态大模型连接数据库初始化设置
# 插入数据
def insert_data(connection, dataset):
connection.execute(users.insert(), dataset)
def select_data(connection):
result = connection.execute(users.select())
for row in result:
print(row)
def get_table_schema(engine):
inspector = reflection.Inspector.from_engine(engine)
table_names = inspector.get_table_names()
schema = {}
for table_name in table_names:
columns = inspector.get_columns(table_name)
schema[table_name] = [column['name'] for column in columns]
return schema
def execute_query(query):
with engine.connect() as conn:
result = conn.execute(text(query))
return result.fetchall()
def query_database(prompt, schema):
# 将表结构信息包含在提示中
schema_info = "\n".join([f"Table {table}: {', '.join(columns)}" for table, columns in schema.items()])
full_prompt = f"""
以下是数据库的表结构信息:
{schema_info}
请根据图片信息生成一个SQL查询
请严格按照表结构生成SQL查询在</answer>里面显示
"""
prompt_final = PromptTemplate(
input_variables=[schema_info],
template=full_prompt
)
print("***************************************************************************")
print("full_prompt:", full_prompt.replace('\n', ''))
print("***************************************************************************")
return full_prompt.replace('\n', '')
3. 输出结果

多模态推理过程
message_search = [
# {"role": "system", "content": [{"type": "text", "text": SYSTEM_PROMPT}]},
{
"role": "user",
"content": [
{
"type": "image",
"image": f"file://{image}"
},
{
"type": "text",
"text": query_database()
}
]
}]
messages_prompt.append(message_search)
text = [processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True) for msg in messages_prompt]
print("*************************************")
print("text:", text)
print("*************************************")
image_inputs, video_inputs = process_vision_info(messages_prompt)
print("*************************************")
print("image_inputs:", image_inputs)
print("*************************************")
inputs = processor(
text=text,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
print("*************************************")
print("inputs:", inputs)
print("*************************************")
inputs = inputs.to("cuda:0")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, use_cache=True, max_new_tokens=300, do_sample=False)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
batch_output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
all_outputs.extend(batch_output_text)
print("==========查询结果")
print(all_outputs[0])
4. 编写获取sql语句函数
def extract_sql_answer(content):
answer_tag_pattern = r'<Answer>(.*?)</Answer>'
sql_pattern = r'```sql(.*?)```'
content_answer_match = re.search(answer_tag_pattern, content, re.DOTALL)
if content_answer_match:
content_answer = content_answer_match.group(1).strip()
sql_match = re.search(sql_pattern, content_answer, re.DOTALL)
if sql_match:
sql_content = sql_match.group(1).strip()
posibble_things = execute_query(sql_content)
return posibble_things
elif "sql" in content:
sql_match = re.search(sql_pattern, content, re.DOTALL)
if sql_match:
sql_content = sql_match.group(1).strip()
posibble_things = execute_query(sql_content)
return posibble_things
return ""
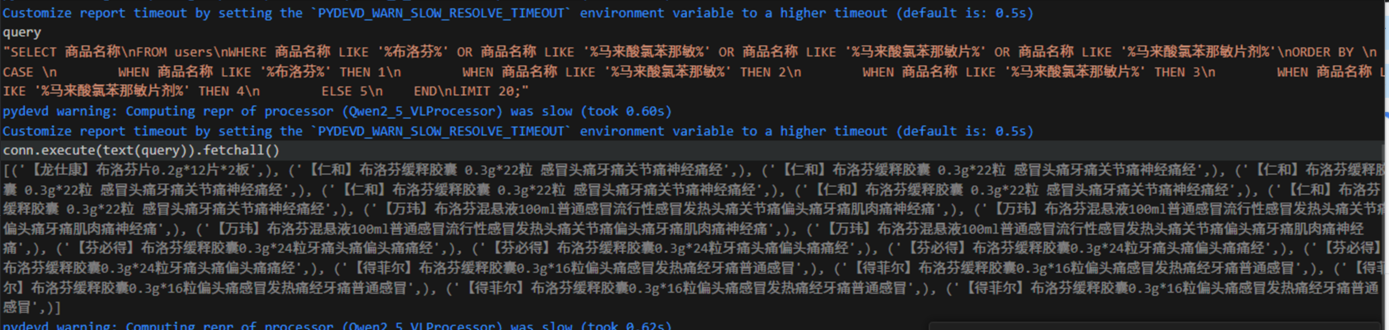
5. 将query查询语句与数据库连接并返回查询结果
def execute_query(query):
query = query.replace("商品表", "users")
with engine.connect() as conn:
result = conn.execute(text(query))
return result.fetchall()
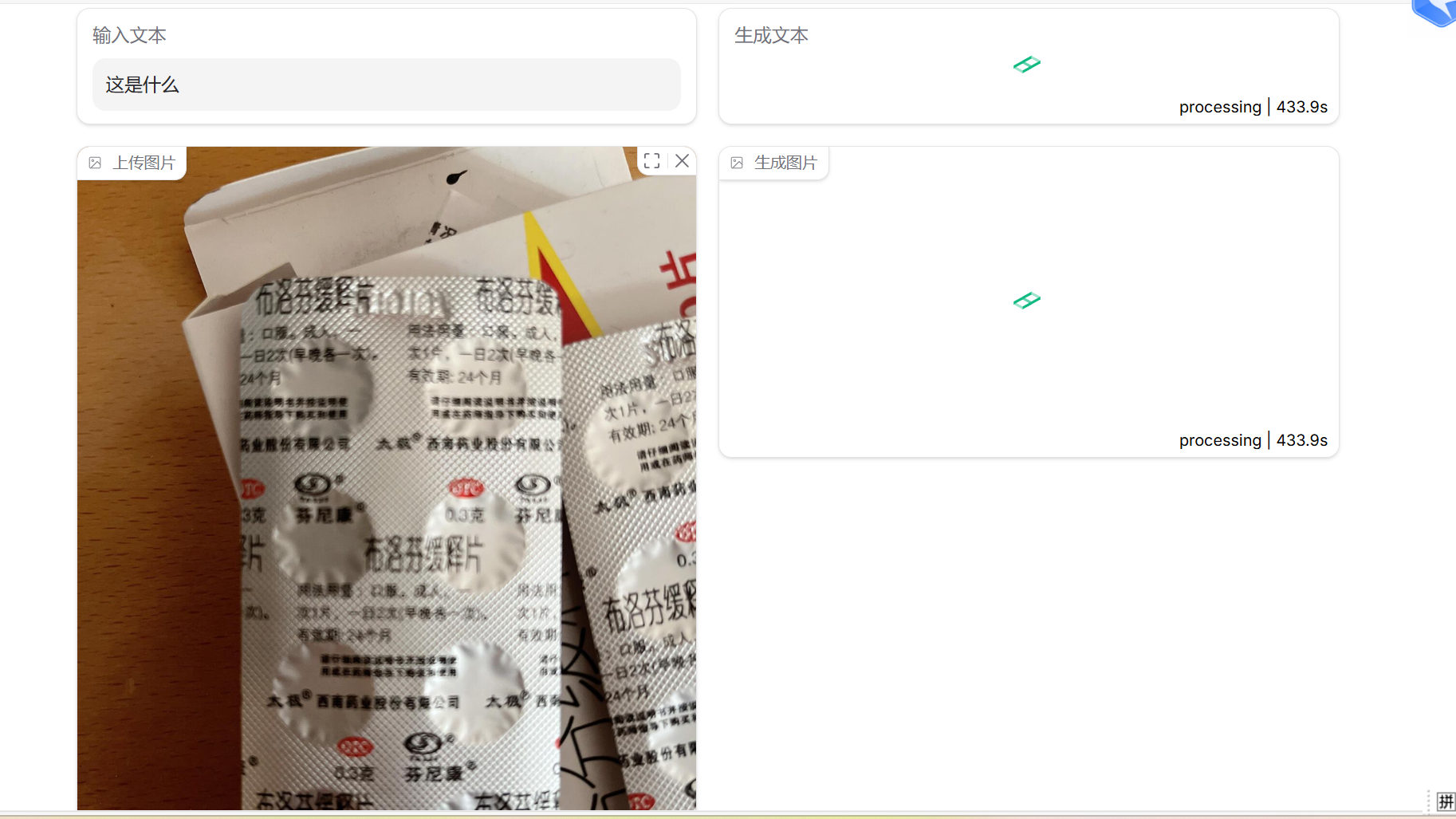
6. 结果展示



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









