






文章目录
- 场景面试题
- HTML篇
- CSS篇
- JS 基础篇
- ES6篇
- React 篇
- VUE篇
- 算法篇
- 1. (百度)实现 (5).add(3).minus(2) 功能
- 2. 给定两个数组,写一个方法来计算它们的交集
- 3. 随机生成一个长度为 10 的整数类型的数组,例如 [2, 10, 3, 4, 5, 11, 10, 11, 20],将其排列成一个新数组,要求新数组形式如下,例如 [[2, 3, 4, 5], [10, 11], [20]]。
- 4. 如何把一个字符串的大小写取反(大写变小写小写变大写),例如 ’AbC' 变成 'aBc' 。
- 5. 实现一个字符串匹配算法,从长度为 n 的字符串 S中,查找是否存在字符串 T,T 的长度是 m,若存在返回所在位置。
- 6. 「旋转数组」
- 7. 打印出 1 - 10000 之间的所有对称数
- 8. 「两数之和」
- 9 给定两个大小为 m 和 n 的有序数组 nums1 和nums2。请找出这两个有序数组的中位数。要求算法的时间复杂度为 O(log(m+n))。
- 进阶篇
场景面试题
1、大文件上传怎么处理
大文件分片上传
如果太大的文件,比如一个视频1G、2G那么大,直接采用一般的上传方法可能会出链接现超时的情况,而且也会超过服务端允许上传文件的大小限制,所以解决这个问题我们可以讲文件进行分片上传,每次只上传很小一部分比如2M。
blob他表示原始数据,也就是二进制数据,同时提供了对数据截取的方法slice,而file继承了blob的功能,所以直接可以使用此方法对数据进行分段截图。
过程如下:
- 把大文件进行分段 比如2M,发送到服务器携带一个标志,暂时用当前的时间戳,用于标识一个完整的文件
- 服务端保存各段文件
- 浏览器端所有分片上传完成,发送给服务端一个合并文件的请求
- 服务端根据文件标识、类型、各分片顺序进行文件合并
- 删除分片文件
// 假设服务器端的上传接口是 /upload 和合并接口是 /merge
// 用于上传文件的函数
async function uploadFile(file, chunkSize = 2 * 1024 * 1024) { // 默认分片大小为 2MB
const timestamp = Date.now(); // 使用当前时间戳作为文件标识
const totalChunks = Math.ceil(file.size / chunkSize);
let uploadedChunks = 0;
// 上传分片
for (let i = 0; i < totalChunks; i++) {
const start = i * chunkSize;
const end = Math.min(start + chunkSize, file.size);
const chunk = file.slice(start, end);
const formData = new FormData();
formData.append('file', chunk);
formData.append('timestamp', timestamp);
formData.append('chunkIndex', i);
formData.append('totalChunks', totalChunks);
try {
const response = await fetch('/upload', {
method: 'POST',
body: formData,
});
if (!response.ok) {
throw new Error(`Upload failed: ${response.statusText}`);
}
uploadedChunks++;
console.log(`Chunk ${i + 1} of ${totalChunks} uploaded.`);
} catch (error) {
console.error(`Failed to upload chunk ${i + 1}:`, error);
return; // 如果某个分片上传失败,停止上传
}
}
// 所有分片上传完成,发送合并请求
if (uploadedChunks === totalChunks) {
try {
const response = await fetch('/merge', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
timestamp,
totalChunks,
}),
});
if (!response.ok) {
throw new Error(`Merge failed: ${response.statusText}`);
}
console.log('File merged successfully.');
} catch (error) {
console.error('Failed to merge file:', error);
}
}
}
// 使用示例
document.getElementById('fileInput').addEventListener('change', (event) => {
const file = event.target.files[0];
if (file) {
uploadFile(file);
}
});
服务器端伪代码(Node.js 示例)
const express = require('express');
const multer = require('multer');
const fs = require('fs');
const path = require('path');
const app = express();
const upload = multer({ dest: 'uploads/' });
app.post('/upload', upload.single('file'), (req, res) => {
const { timestamp, chunkIndex, totalChunks } = req.body;
const chunkPath = path.join('uploads', `${timestamp}_${chunkIndex}`);
fs.rename(req.file.path, chunkPath, (err) => {
if (err) {
return res.status(500).send('Failed to save chunk');
}
res.send('Chunk uploaded successfully');
});
});
app.post('/merge', (req, res) => {
const { timestamp, totalChunks } = req.body;
const filePath = path.join('uploads', `${timestamp}.merged`);
const writeStream = fs.createWriteStream(filePath);
for (let i = 0; i < totalChunks; i++) {
const chunkPath = path.join('uploads', `${timestamp}_${i}`);
const readStream = fs.createReadStream(chunkPath);
readStream.pipe(writeStream, { end: false });
readStream.on('end', () => {
fs.unlink(chunkPath, (err) => {
if (err) {
console.error(`Failed to delete chunk ${i}:`, err);
}
});
});
}
writeStream.on('finish', () => {
res.send('File merged successfully');
});
writeStream.on('error', (err) => {
console.error('Failed to merge file:', err);
res.status(500).send('Failed to merge file');
});
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
大文件上传断点续传
在上面我们实现了文件分片上传和最终的合并,现在要做的就是如何检测这些分片,不再重新上传即可。这里我们可以在本地进行保存已经上传成功的分片,重新上传的时候使用spark-md5来生成文件hash,区分此文件是否已上传。
- 为每个分段生成hash值,使用spark-md5库
- 将上传成功的分段信息保存到本地
- 重新上传时,进行和本地分段hash值的对比,如果相同的话则跳过,继续下一个分段的上传
-方案一:保存在本地indexDB/localStorage等地方,推荐使用localForage这个库
npm install localForage
// 引入所需的库
import SparkMD5 from 'spark-md5';
import localForage from 'localforage';
// 用于上传文件的函数
async function uploadFile(file, chunkSize = 2 * 1024 * 1024) { // 默认分片大小为 2MB
const timestamp = Date.now(); // 使用当前时间戳作为文件标识
const totalChunks = Math.ceil(file.size / chunkSize);
const uploadedChunks = await getUploadedChunks(timestamp); // 获取本地存储的已上传分片信息
// 上传分片
for (let i = 0; i < totalChunks; i++) {
if (uploadedChunks.includes(i)) {
console.log(`Chunk ${i + 1} already uploaded.`);
continue; // 如果分片已经上传成功,跳过
}
const start = i * chunkSize;
const end = Math.min(start + chunkSize, file.size);
const chunk = file.slice(start, end);
const chunkHash = await generateHash(chunk); // 生成分片的哈希值
const formData = new FormData();
formData.append('file', chunk);
formData.append('timestamp', timestamp);
formData.append('chunkIndex', i);
formData.append('totalChunks', totalChunks);
formData.append('chunkHash', chunkHash); // 将哈希值一起上传
try {
const response = await fetch('/upload', {
method: 'POST',
body: formData,
});
if (!response.ok) {
throw new Error(`Upload failed: ${response.statusText}`);
}
// 保存已上传分片信息到本地
await saveUploadedChunk(timestamp, i);
console.log(`Chunk ${i + 1} of ${totalChunks} uploaded.`);
} catch (error) {
console.error(`Failed to upload chunk ${i + 1}:`, error);
return; // 如果某个分片上传失败,停止上传
}
}
// 所有分片上传完成,发送合并请求
if (uploadedChunks.length === totalChunks) {
try {
const response = await fetch('/merge', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
timestamp,
totalChunks,
}),
});
if (!response.ok) {
throw new Error(`Merge failed: ${response.statusText}`);
}
console.log('File merged successfully.');
} catch (error) {
console.error('Failed to merge file:', error);
}
}
}
// 生成分片的哈希值
function generateHash(blob) {
return new Promise((resolve) => {
const reader = new FileReader();
reader.onload = (e) => {
const spark = new SparkMD5.ArrayBuffer();
spark.append(e.target.result);
resolve(spark.end());
};
reader.readAsArrayBuffer(blob);
});
}
// 保存已上传分片信息到本地
async function saveUploadedChunk(timestamp, chunkIndex) {
const uploadedChunks = await getUploadedChunks(timestamp);
uploadedChunks.push(chunkIndex);
await localForage.setItem(`uploadedChunks_${timestamp}`, uploadedChunks);
}
// 获取本地存储的已上传分片信息
async function getUploadedChunks(timestamp) {
return (await localForage.getItem(`uploadedChunks_${timestamp}`)) || [];
}
// 使用示例
document.getElementById('fileInput').addEventListener('change', (event) => {
const file = event.target.files[0];
if (file) {
uploadFile(file);
}
});
方案2:服务端用于保存分片坐标信息。返回给前端
需要服务端添加一个接口只是服务端需要增加一个接口。基于上面一个栗子进行改进,服务端已保存了部分片段,客户端上传前需要从服务端获取已上传的分片信息(上面是保存在了本地浏览器)本地对比每个分片的hash值,跳过已上传的部分,只传为上传的分片。
方法1是从本地获取分片信息,这里只需要将此方法的能力改为从服务端获取分片信息就行了。
2、 请求失败会弹出一个toast,如何保证批量请求失败,只弹出一个toast
方案1:设置全局标志位,定义一个全局变量(如isToastShown)来表示是否已经弹出过toast。在请求失败的处理逻辑中,首先检查该标志位。如果尚未弹出toast,则进行弹出操作,并设置标志位为true;如果标志位已经为true,则直接忽略后续的弹出操作。
方案2:使用防抖或截流函数,防抖或截流函数可以限制某个函数在一定时间内的执行次数。将弹出toast的操作封装在防抖或节流函数中,确保在短时间内多个请求失败时,不会频繁弹出toast
方案3:集中处理错误,将所有请求的错误集中处理,而不是在每个请求的catch块中直接弹出toast。例如,把所有请求的promise添加到一个数组中,然后使用promise.all()或其他类似方法来统一处理这些promise的结果。如果所有请求都失败了,在弹出一个toast。
3、如何减少项目里面if-else
当项目中存在大量的if-else语句时,可以考虑以下几种优化方法
- 策略模式
创建一组策略对象,每个对象应以一种条件和处理逻辑。根据不同的条件选择相应的策略对象来执行操作。 - 表驱动法
建立一个数据结构(如对象或数组)。将条件与对应的处理函数或值关联起来,通过查找表来获取相应的处理方式。 - 多态
如果条件判断基于不同的对象类型,可以使用多态性,让每个对象类型实现自己的处理方法。 - 提取函数
将每个if-else分支中的复杂逻辑提取为独立的函数,以提高代码的可读性和可维护性。 - 状态模式
当条件判断反映的是对象的不同状态时,可以使用状态模式来处理。
4、如何做好前端监控方案
web前端监控的方案,包括前端监控的意义、内容、形式、总体方案设计、监控的指标、前端埋点方案、上报逻辑、监控数据存储、管理平台展示、报警通知、优化整改方案
重要:
- 前端监控的意义:如同城市探头,实时监测保证系统稳定高效,为业务赋能获取更多用户。能够快速解决用户线上问题、用户性能问题;给予产品决策提供数据支持。
- 2-5-8原则:阐述不同响应时间用户的感受和可能的行为
- 监控的内容:包括用户行为异常、运行性能。
- 监控的形式:分为主动和被动监控
- 总体方案设计:涵盖页面埋点、数据上报、后台存储、汇总统计、报警展示、优化整改环节。
- 监控指标:性能指标如FP FECP FMP等以及Google Web Vitals中的LCP FID CLS等,还有用户指标如UV PV等。
- 前端埋点方案:介绍了写死在业务代码、全量埋点、动态埋点三种方式,推荐动态埋点
- 上报逻辑:ajax、fetch上报、image上报、jsonp上报、sendBeacon上报,推荐sendBeacon上报
- 监控数据的存储:可存于Hadoop大数据平台、MySQL关系数据库、NoSQL存储。
- 管理数据的存储:包括注册和管理业务项目、查看监控数据、配置监控规则和阈值。
- 报警通知:通过定时任务读取配置表,根据规则查询数据,有多种通知形式。
- 优化整改:针对性能不能达标和用户留存低提出多种措施。
5、cookie可以实现不同域共享吗
默认情况下,Cookie不能在不同的顶级域名之间共享数据
但是,如果两个域名属于同一主域名下的子域名,并且您设置了正确的Domain属性,那么在这些子域名之间是可以共享Cookie的。
例如,对于sub1.example.com和sub2.example.com这样的子域名,如果设置Cookie的Domain属性为.example.com,那么这两个子域名之间,这个Cookie是可以共享和访问的。
然而,如果是完全不同的顶级域名,如example.com和anotherdomain.com之间,Cookie是不能直接共享的。
此外,还需要注意Cookie的path属性、安全属性(Secure)、httponly属性等,这些属性也会影响Cookie的使用范围和方式。
6、axios是否可以取消请求
axios可以取消请求。官方文档指出有两种方法可以取消请求,分别是cancelToken 和AbortController,示例代码如下
- 使用cancelToken 的方法一:
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.post("/user/1234",{name:"new name"},{cancleToken:source.token});
source.cancle("Operation canceled by the user.")
- 使用cancelToken 的方法二:
const CancelToken = axios.CancelToken;
let cancel;
axios.get("/user/12345",{
CancelToken:new CancelToken(function executor(c){
cancel = c;
}),
});
cancel();
- 使用AbortController
const controller = new AbortController();
axios.get("/foo/bar",{signal:controller.signal}).then(function (response)
{});
controller.abort();
通过文档描述和实例代码,可以总结出以下功能点:
- 支持cancelToken取消请求,cancelToken可以通过工厂函数产生,也可以通过工厂函数产生,也可以通过构造函数生成
- 支持fetch API的AbortController 取消请求
- 一个token/signal可以取消多个请求,一个请求也可以同时使用token/signal;
- 如果在开始axios request 之前执行了取消请求,则并不会发出真实的请求。
7. 函数式编程了解多少
函数式编程时一种编程范式,他将程序看作是一系列函数的组合,函数是应用的基础单位。函数式编程主要有以下核心概念:
- 纯函数:函数的输出只取决于输入,没有任何副作用,不会修改外部变量或状态,所以对于同样的输入,永远返回同样的输出值。因此纯函数可以有效的避免副作用和静态条件等问题,使得代码更加可靠、易于调适和测试。
- 不可变性:在函数式编程中,数据通常是不可变的,即不允许在内部进行修改。这样可以避免副作用的发生,提高代码可靠性。
- 函数组合:函数可以组合成复杂的函数,从而减少重复代码的产生。
- 高阶函数:高阶函数是指可以接收其他函数作为参数,也可以返回函数的函数。例如,函数柯里化和函数的组合就是高阶函数的应用场景。
- 惰性计算:指在必要的时候才计算(执行)函数,而不是在每个可能的执行路径上都执行,从而提高性能。
函数式编程的核心概念是将函数作为基本构件块来组合构建程序,通过纯函数、不可变性、函数组合、高阶函数和惰性计算等概念来实现代码的简洁性、可读性和可维护性,以及高洗澡的性能运行。
8. 单点登录是如何实现的?
单点登录:简称SSO。用户只要登录一次,就可以访问所有相关信任应用的资源。企业里面用的会比较多,有很多内网平台,但是只要在一个系统登录就可以。
实现方案
- 单一域名:可以把cookie种在根域名下实现单点登录
- 多域名:常用CAS来解决,新增一个认证中心的服务。CAS是实现单点登录的框架
CAS实现单点登录的流程
- 用户访问系统A,判断未登录,则直接跳到认证中心页面
- 在认证中心页面输入账号、密码、生成令牌,重定向到系统A
- 在系统A拿到令牌到认证中心去认证,认证通过,则建立对话
- 用户访问系统B,发现没有有效会话,则重定向到认证中心
- 认证中心发现有全局绘画,建立令牌,重定向到系统B
- 在系统B使用令牌去认证中心验证,验证成功后,建立系统B的局部会话。
关键点
下面是举例来详细说明CAS实现单点登录的流程:
一、第一次访问系统A
1.用户访问系统A (www.app1.com),跳转认证中心 client(www.sso.com), 然后输入用户名,密码登录,然后认证中心 serverSS0把cookieSSO 种在认证中心的域名下 (www.sso.com),重定向到系统A,并且带上生成的 ticket参数(www.appl.com?ticket =xxx)
系统A (www.app1.com?ticket =xxx)请求系统A的后端 serverA,serverA去serverSSO 验证,通过后,将cookieA种在www.app1.com下
二、第二次访问系统A 直接携带 cookieA 去访问后端,验证通过后,即登录成功。
三、第三次访问系统B
- 访问系统B (www.app2.com),跳转到认证中心 client(www.sso.com),这个时候会把认证中心的1.cookieSS0也携带上,发现用户已登录过,则直接重定向到系统B(www.app2.com),并且带上生成的ticket参数(www.app2.com?ticket =xxx)
- 系统B (www.app2.com?ticket =xxx)请求系统B的后端serverB,serverB 去serverSSO 验证,通过后,将cookieB种在www.app2.com下
注意cookie生成时机及种的位置。
- cookieSSO,SSO域名下的cookie
- cookieA,系统A域名下的cookie
- cookieB,系统B域名下的cookie
9. 你认为组件封装的一些基本准则是什么?
- 单一职责原则:一个组件应该具有单一的功能,并且只负责完成该功能,避免组件过于庞大和复杂。
- 高内聚低耦合:组件内部的各个部分之间应该紧密相关,组件与其他组件之间应该尽量解耦,减少对外部的依赖。
- 易用性:组件应该易于使用,提供清晰地接口和文档,使用户能够方便地使用组件。
- 可扩展性:组件应该具有良好的可扩展性,能够方便的添加新的功能或进行修改,同事不影响已有的功能。
- 可重用性:组件应该是可重用的,能够在多个项目中使用,减少重复开发的工作量。
- 高效性:组件应该具有高性能和低资源消耗的特点,不会成为整个系统的性能瓶颈。
- 安全性:组件应该具有安全性,能够防止恶意使用或攻击。
- 可测试性:组件应该容易进行单元测试和集成测试,以保证组件的质量和稳定性。
10. npm install之后发生了什么
10.1 什么是npm
npm(node package manager),是随同node.js一起安装的第三方包管理器。通过npm,我们可以安装、共享、发布代码,管理项目依赖关系。
嵌套结构
在npm的早期版本中,npm以递归的方式去处理依赖,每个依赖包都会在自己的node_modules目录中安装其子依赖,直到没有子依赖为止。
举个例子,我们项目安装axios依赖,axios自身需要两个依赖:
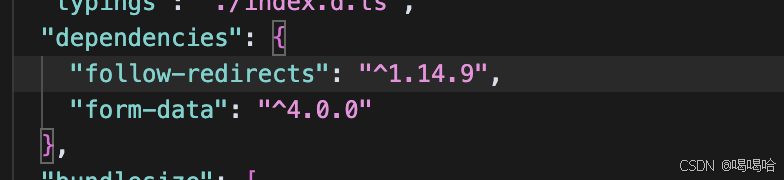
而其中的form-data又存在三个依赖,这里就不一一列举了,当执行npm install命令后,得到的node_modules中的模块目录结构:
my-project
└── node_modules
├── axios
│ ├── follow-redirects
│ ├── form-data
│ │ ├── asynckit
│ │ ├── combined-stream
│ │ │ └── delayed-stream
│ │ └── mime-types
│ │ └── mime-db
│
这样的优点就是node_modules的结果和package.json的结果一一对应,层级结构明显,而且保证了每次安装目录结构都是相同的。
但也存在不容忽视的缺点:如果项目一旦变大,依赖变多,node_modules将变得非常庞大,特别是不同层级的依赖如果共用一个依赖,还会造成不必要的冗余,而且整个的嵌套层级也会非常深。
扁平结构
为了解决以上的问题,npm3.x开始嵌套结构改为了扁平结构,当安装模块时,不管是直接依赖还是子依赖,有限将其安装在node_modules根目录。
当安装到相同的时候,判断已安装的是否符合新的版本范围,如果符合就跳过,不符合就继续安装。
配置文件
- package.json
一般来说,任何使用Node.js的项目都需要有一个package.json文件,该文件中包括项目名称、版本、描述和所依赖的包 - package-lock.json
为了解决 npm install 的不确定性问题,在 npm 5.x 版本新增了 package-lock.json 文件,而安装方式还沿用了 npm 3.x 的扁平化的方式。它描述了生成的确切树,以便后续安装能够生成相同的树,而不管中间依赖更新如何
.npmrc
控制 npm 的行为,如注册表、代理、缓存路径等。
# 包下载源
registry=https://registry.npmmirror.com
# 设置作用域包的私有仓库(如公司内部包)
@mycompany:registry=https://npm.mycompany.com
# 设置缓存目录路径(默认 ~/.npm)
cache=~/.custom-npm-cache
# 设置 HTTP 代理(根据实际情况替换)
proxy=http://127.0.0.1:8080
.npmrc 文件的优先级为:项目级 > 用户级 > 全局级 > 内置级。
打开目录有以下文件夹
content-v2存放的是依赖实际的内容,而index-v5则是存放依赖的索引信息
下载包
如果检查到本地缓存中不存在对应的依赖包,便会通过发送网络请求去下载包。具体是通过package-lock.json文件中的resolved字段,当我们尝试通过该字段中的值从浏览器中输入,发现会直接给我们下载了一个文件,例如,我们使用 axios 中的 resolved 中的值,具体值是:
https://registry.npmjs.org/axios/-/axios-1.3.1.tgz
10.3 依赖完整性
在下载依赖包之前,我们一般就能拿到 npm 对该依赖包计算的 hash 值,例如我们执行 npm info 命令,紧跟 tarball(下载链接) 的就是 shasum(hash)
在下载依赖包之前,npm 会获取其 shasum 哈希值。下载完成后,npm 会在本地重新计算哈希值,并与远程的哈希值对比。如果两者一致,则依赖包完整;否则,npm 会重新下载。
10.4 npm缓存
在执行 npm install 或 npm update 命令下载依赖后,除了将依赖包安装在 node_modules 目录下外,还会在本地的缓存目录缓存一份。我们可以通过以下命令获取缓存位置:
npm config get cache
10.5 整体流程
- 首先,npm install 需要检查是否有附加的命令参数,如 --save、–save-dev,以决定依赖的类型(例如:生产依赖或开发依赖)。如果没有指定,则之后会安装 package.json 中列出的所有依赖。
- 接着,npm install 会按优先级查找配置文件:项目级 .npmrc > 用户级 .npmrc > 全局级 .npmrc > npm 内置 .npmrc,并根据配置调整安装行为。
- 如果项目定义了 preinstall 钩子(例如:npm run preinstall),它会在依赖安装前被执行。可以在此步骤进行一些初始化操作,如检查版本、清理缓存等。
- 然后检查是否有lock文件,有的话会检查package.json中的依赖版本是否和package-lock.json中的依赖有冲突。如果没有冲突,直接在缓存中查找包信息。
如果没有lock文件,会先从npm远程仓库去获取包信息,之后根据package.json构建依赖树,具体过程
- 构建依赖树时,不管其是直接依赖还是子依赖的依赖,优先将其放置在 node_modules 根目录。
当遇到相同模块时,判断已放置在依赖树的模块版本是否符合新模块的版本范围,如果符合则跳过,不符合则在当前模块的 node_modules 下放置该模块。
- 之后再在缓存中依次查找依赖树的每个包:
- 不存在缓存:从npm远程仓库下载包,检验包的完整性,检验不通过就重新下载,检验通过会将下载的包复制到npm缓存目录并按照扁平化的依赖结构解压到node-modules中
- 存在依赖:将缓存按照扁平化的依赖结构解压到node-modules中
- 生成lock文件
11、如何清理代码中没有被应用的代码,主要是js、ts、css代码
对于JavaScript,typescript
- 使用ESLint
- 初始化ESLint:如果你还没有使用ESLint,可以通过npm eslint --init命令来初始化配置
- 配置规则:确保在.eslintrc配置文件中启用了no-unused-vars规则,以识别未使用的变量和函数
{
"rules":{
"no-usused-vars":"warn"
}
}
- 使用ESLint的–fix选项:虽然ESLint主要用于识别问题,但它的–fix选项可以自动修复一些问题,包括删除未使用的变量等。不过,这种方式相对保守,无法删除大块的未使用代码。
- 使用typescript编译器选项
- 对于typescript项目,可以在tsconfig.json文件中启用noUnusedLocals和noUnusedParametes选项,以识别未使用的本地变量
{
"compilerOptions": {
"noUnusedLocals": true,
"noUnusedParameters": true
}
}
- 利用Webpack的Tree Shaking
- 确保在生产模式下使用Webpack,它自带Tree Shaking功能,可以去除未被使用的代码。
- 使用ES6模块语法(import和export),因为Tree Shaking 仅支持静态导入。
对于CSS
- 使用Purgecss
- PurgeCSS分析你的内容和css文件,去除不匹配的选择器。非常适用于清楚再HTML或JS文件中未引用的CSS代码。
- 可以通过Webpack、Gulp或Postcss等多种方式与PurgeCSS集成
npm install Purgecss
使用Purgecss时,配置你的内容文件路径(如HTML或JSX文件),它会扫描这些文件以确定哪些css选择器被使用:
// 一个基本的PurgeCSS 配置例子
new PurgecssPlugin({
paths: glob.sync(`${PATHS.src}/**/*`, { nodir: true }),
});
使用Codemods
Codemods是Facebook提出的一种工具,允许你对代码库进行大规模的自动化重构。通过编写特定的脚本,你可以自定义删除或修改未被调用的代码的逻辑。例如,使用jscodeshift工具可以配合具体规则进行代码修改。
注意事项
- 测试:自动删除代码后,务必执行完整的测试套件,确认改动不会影响现有功能。
- 版本控制:在进行删除操作之前,确保代码已经提交到版本控制系统,以便必要时可以恢复。
- 逐行执行:尤其是在较大或复杂的项目中,建议分步骤、逐渐移除未使用的代码,每次删除后都进行测试和评估。
使用这些策略和工具可以帮助自动化清理未使用的代码,但是请注意,完全自动化的过程可能会有风险,依然需要人工审核和测试以确保代码的质量和应用的稳定性。
HTML篇
1、HTML5有哪些新特性?
HTML5 现在已经不是 SGML 的子集,主要是关于图像,位置,存储,多任务等功能的增加。
(1)绘画 canvas;
(2)用于媒介回放的 video 和 audio 元素;
(3)本地离线存储 localStorage 长期存储数据,浏览器关闭后数据不丢失;
(4)sessionStorage 的数据在浏览器关闭后自动删除;
(5)语意化更好的内容元素,比如 article、footer、header、nav、section;
(6)表单控件,calendar、date、time、email、url、search;
(7)新的技术webworker, websocket, Geolocation;
(8)IE8/IE7/IE6支持通过document.createElement方法产生的标签,可以利用这一特性让这些浏览器支持HTML5新标签,浏览器支持新标签后,还需要添加标签默认的样式。当然也可以直接使用成熟的框架、比如html5shim
移除的元素:
- 纯表现的元素:basefont big center font s strike tt u
- 性能较差元素:frame frameset noframes
区分:
- DOCTYPE声明的方式是区分重要因素
- 根据新增加的结构、功能来区分
2、介绍下 BFC 及其应用
BFC 就是块级格式上下文,是页面盒模型布局中的一种 CSS 渲染模式,相当于一个独立的容器,里面的元素和外部的元素相互不影响。
创建BFC的方式有:
- html 根元素
- float 浮动
- 绝对定位
- overflow 不为 visiable
- display 为表格布局或者弹性布局
创建 BFC 的方式有:
- 清除浮动
- 防止同一 BFC 容器中的相邻元素间的外边距重叠问题
3、内元素和块级元素的区别?
行内元素:不会独立出现在一行,单独使用的时候后面不会有换行符的元素。eg:span, strong, img, a
等。这些元素,默认的高宽,总是其内容的高宽。并且,margin和padding值,只有左右有效。
块级元素:独立在一行的元素,他们后面会自动带有换行符。eg:div , p ,form , ul , li , ol , dl
等。它们的出现,往往独自占领一行。在没有设置宽度的情况下,默认宽度总是其父元素的宽度。
行内元素转换成块元素,只要设置其display属性为block即可,display:block;
。块元素转换成行内元素,只要将其display属性设置为inline即可,display:inline;。
(1)行内元素有:a b span img input select
(2)块级元素有:div p ul ol li dl dt dd h1-h6
(3)常见的空元素:br-换行,hr-水平分割线
4、Doctype作用?标准模式与混杂模式如何区分?
<!DOCTYPE>告诉浏览器使用哪个版本的html规范来渲染文档。DOCTYPE不存在或形式不正确会导致html文档以混杂模式呈现。
标准模式(Standards mode)以浏览器支持的最高标准运行;混杂模式(Quirks
mode)中页面是一种比较宽松的向后兼容的方式显示。
5、引入样式时,link和@import的区别?
链接样式时,link只能在HTML页面中引入外部样式
导入样式表时,@import 既可以在HTML页面中导入外部样式,也可以在css样式文件中导入外部css样式。
6、介绍一下你对浏览器内核的理解?
主要分成两部分:渲染引擎(Layout Engine或Rendering Engine)和js引擎。
**渲染引擎:**负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。
**js引擎:**解析和执行JavaScript来实现网页的动态效果。最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎。
7、title与h1的区别、b与strong的区别、i与em的区别?
title属性没有明确意义,只表示标题;h1表示层次明确的标题,对页面信息的抓取也有很大的影响
strong标明重点内容,语气加强含义;b是无意义的视觉表示 em表示强调文本;i是斜体,是无意义的视觉表示 视觉样式标签:b i u s
语义样式标签:strong em ins del code
8、从浏览器地址栏输入url到显示页面的步骤
浏览器根据请求的URL交给DNS域名解析,找到真实IP,向服务器发起请求;
服务器交给后台处理完成后返回数据,浏览器接收文件(HTML、JS、CSS、图象等);
浏览器对加载到的资源(HTML、JS、CSS等)进行语法解析,建立相应的内部数据结构(如HTML的DOM);
载入解析到的资源文件,渲染页面,完成。
CSS篇
1. 绘制一像素的线
canvas 、height、hr、伪元素上设置媒体查询+transfrom scaleY、边框
ctx.lineWidth = 1;
ctx.beginPath();
ctx.moveTo(10, 100);
ctx.lineTo(300,100);
ctx.stroke();
2. css选择器
选择器的分类与优先级

- 标签选择器:优先级加权值为 1。
- 伪元素或伪对象选择器:优先级加权值为 1。
- 类选择器:优先级加权值为 10。
- 属性选择器:优先级加权值为 10。
- ID选择器:优先级加权值为 100。
- 其他选择器:优先级加权值为 0,如通配选择器等。
然后,以上面加权值数为起点来计算每个样式中选择器的总加权值数。计算的规则如下:
- 统计选择器中 ID 选择器的个数,然后乘以100。
- 统计选择器中类选择器的个数,然后乘以 10。
- 统计选择器中的标签选择器的个数,然后乘以 1。
依此方法类推,最后把所有加权值数相加,即可得到当前选择器的总加权值,最后根据加权值来决定哪个样式的优先级大。
3. CSS盒子模型与怪异盒模型
1、标准盒模型中width指的是内容区域content的宽度;height指的是内容区域content**的高度。
标准盒模型下盒子的大小 = content + border + padding + margin

2、怪异盒模型中的width指的是内容、边框、内边距总的宽度(content + border + padding);
height指的是内容、边框、内边距总的高度
怪异盒模型下盒子的大小=width(content + border + padding) + margin
3、在ie8+浏览器中使用哪个盒模型可以由box-sizing(CSS新增的属性)触发,
默认值为content-box,即标准盒模型;如果将box-sizing设为border-box则用的是IE盒模型
4、box-shadow: h-shadow v-shadow blur spread color inset;
h-shadow,v-shadow必须。水平,垂直阴影的位置。允许赋值。blur可选,模糊距离。spread可选,阴影的尺寸。color可选,阴影的颜色。inset可选,将外部阴影(outset)改为内部阴影。
4. CSS3动画
一:过渡动画—Transitions
1:过渡动画Transitions
含义:在css3中,Transitions功能通过将元素的某个属性从一个属性值在指定的时间内平滑过渡到另一个属性值来实现动画功能。
Transitions属性的使用方法如下所示:
transition: property | duration | timing-function | delay
transition-property: 表示对那个属性进行平滑过渡。
transition-duration: 表示在多长时间内完成属性值的平滑过渡。
transition-timing-function 表示通过什么方法来进行平滑过渡。
| linear | 规定以相同速度开始至结束的过渡效果(等于 cubic-bezier(0,0,1,1))。 |
|---|---|
| ease | 规定慢速开始,然后变快,然后慢速结束的过渡效果(cubicbezier(0.25,0.1,0.25,1))。 |
| ease-in | 规定以慢速开始的过渡效果(等于 cubic-bezier(0.42,0,1,1))。 |
| ease-out | 规定以慢速开始和结束的过渡效果(等于 cubic-bezier(0.42,0,0.58,1))。 |
| cubicbezier(n,n,n,n) | 在 cubic-bezier 函数中定义自己的值。可能的值是 0 至 1 之间的数值。 |
transition-delay: 定义过渡动画延迟的时间。
默认值是 all 0 ease 0
**浏览器支持程度:**IE10,firefox4+,opera10+,safari3+及chrome8+
下面是transitions过渡功能的demo如下
HTML代码如下:
<div class="transitions">transitions过渡功能</div>
CSS代码如下:
.transitions {
-webkit-transition: background-color 1s ease-out;
-moz-transition: background-color 1s ease-out;
-o-transition: background-color 1s ease-out;
}.transitions:hover {
background-color: #00ffff;
}
效果如下:
transitions过渡功能
如果想要过渡多个属性,可以使用逗号分割,如下代码:
div { -webkit-transition: background-color 1s linear, color 1s linear, width 1s linear;}
2. 我们可以使用Transitions功能同时平滑过渡多个属性值。
如下HTML代码:
<h2>transitions平滑过渡多个属性值</h2><div class="transitions2">transitions平滑过渡多
个属性值</div>
css代码如下:
.transitions2 {
background-color:#ffff00;
color:#000000;
width:300px;
-webkit-transition: background-color 1s linear, color 1s linear, width
1s linear;
-moz-transition: background-color 1s linear, color 1s linear, width 1s
linear;
-o-transition: background-color 1s linear, color 1s linear, width 1s
linear;
}.transitions2:hover {
background-color: #003366;
color: #ffffff;
width:400px;
}
transitions平滑过渡多个属性值
transitions平滑过渡多个属性值 注意:transition-timing-function
表示通过什么方法来进行平滑过渡。它值有如下: 有ease | linear | ease-in | ease-out |
ease-in-out | cubic-bezier 至于linear
线性我们很好理解,可以理解为匀速运动,至于cubic-bezier贝塞尔曲线目前用不到,可以 忽略不计,我们现在来理解下 ease,
ease-in, easy-out 和 ease-in-out 等属性值的含义; ease: 先快后逐渐变慢; ease-in: 先慢后快
easy-out: 先快后慢
easy-in-out: 先慢后快再慢
理解上面几个属性值,如下demo:
HTML代码如下:
<div id="transBox" class="trans_box">
<div class="trans_list ease">ease</div>
<div class="trans_list ease_in">ease-in</div>
<div class="trans_list ease_out">ease-out</div>
<div class="trans_list ease_in_out">ease-in-out</div>
<div class="trans_list linear">linear</div></div>
CSS代码如下:
.trans_box {
background-color: #f0f3f9; width:100%
}.trans_list {
width: 30%;
height: 50px;
margin:10px 0;
background-color:blue;
color:#fff;
text-align:center;
}.ease {
-webkit-transition: all 4s ease;
-moz-transition: all 4s ease;
-o-transition: all 4s ease;
transition: all 4s ease;
}.ease_in {
-webkit-transition: all 4s ease-in;
-moz-transition: all 4s ease-in;
-o-transition: all 4s ease-in;
transition: all 4s ease-in;
}.ease_out {
-webkit-transition: all 4s ease-out;
-moz-transition: all 4s ease-out;
-o-transition: all 4s ease-out;
transition: all 4s ease-out;
}.ease_in_out {
-webkit-transition: all 4s ease-in-out;
-moz-transition: all 4s ease-in-out;
-o-transition: all 4s ease-in-out;
transition: all 4s ease-in-out;
}.linear {
-webkit-transition: all 4s linear;
-moz-transition: all 4s linear;
-o-transition: all 4s linear;
transition: all 4s linear;
}.trans_box:hover .trans_list{
margin-left:90%;
background-color:#beceeb;
color:#333;
-webkit-border-radius:25px;
-moz-border-radius:25px;
-o-border-radius:25px;
border-radius:25px;
-webkit-transform: rotate(360deg);
-moz-transform: rotate(360deg);
-o-transform: rotate(360deg);
transform: rotate(360deg);
}
二:Animations功能:定义多个关键帧
Animations功能与Transitions功能相同,都是通过改变元素的属性值来实现动画效果的。
它们的区别在于:使用Transitions功能是只能通过指定属性的开始值与结束值。然后在这两个属性值之间进行平滑过渡的方式来实现动画效果,因此不能实现复杂的动画效果;而Animations则通过定义多个关键帧以及定义每个关键帧中元素的属性值来实现更为复杂的动画效果。
**语法:**animations: name duration timing-function iteration-count;
name: 关键帧集合名(通过此名创建关键帧的集合)
duration: 表示在多长时间内完成属性值的平滑过渡
timing-function: 表示通过什么方法来进行平滑过渡
iteration-count: 迭代循环次数,可设置为具体数值,或者设置为infinite进行无限循环,默认为1.
用法:@-webkit-keyframes 关键帧的集合名 {创建关键帧的代码}
如下面的代码:
@-webkit-keyframes mycolor {
0% {background-color:red;}
40% {background-color:darkblue;}
70% {background-color: yellow;}
100% {background-color:red;}}
.animate:hover {
-webkit-animation-name: mycolor;
-webkit-animation-duration: 5s;
-webkit-animation-timing-function:
5. Flex布局
设为 Flex 布局以后,子元素的 float 、 clear 和 vertical-align 属性将失效。
采用 Flex 布局的元素,称为 Flex 容器(flex container)
- flex-direction
- flex-wrap
- flex-flow
- justify-content
- align-items
- align-content
5.1 flex-direction属性
flex-direction 属性决定主轴的方向(即项目的排列方向)。
.box {
flex-direction: row | row-reverse | column | column-reverse;
}

它可能有4个值。

5.2 flex-wrap属性
默认情况下,项目都排在一条线(又称"轴线")上。 flex-wrap 属性定义,如果一条轴线排不下,如何
换行。

它可能取三个值。
(1) nowrap (默认):不换行。
(2) wrap :换行,第一行在上方。
(3) wrap-reverse :换行,第一行在下方。
5.3 flex-flow
flex-flow 属性是 flex-direction 属性和 flex-wrap 属性的简写形式,默认值为 row nowrap 。
.box {
flex-flow: <flex-direction> || <flex-wrap>;
}
5.4 justify-content属性
justify-content 属性定义了项目在主轴上的对齐方式
.box {
justify-content: flex-start | flex-end | center | space-between | spacearound;
}
它可能取5个值,具体对齐方式与轴的方向有关。下面假设主轴为从左到右。
flex-start (默认值):左对齐 flex-end :右对齐 center : 居中 space-between:两端对齐,
项目之间的间隔都相等。 space-around :每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大 一倍
5.5 align-items属性
align-items 属性定义项目在交叉轴上如何对齐。
.box {
align-items: flex-start | flex-end | center | baseline | stretch;
}
它可能取5个值。具体的对齐方式与交叉轴的方向有关,下面假设交叉轴从上到下。
flex-start :交叉轴的起点对齐。
flex-end:交叉轴的终点对齐。
center :交叉轴的中点对齐。
baseline : 项目的第一行文字的基线对齐。
stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。
5.6 align-content属性
align-content 属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
.box {
align-content: flex-start | flex-end | center | space-between | spacearound | stretch;
}
该属性可能取6个值。
flex-start :与交叉轴的起点对齐。
flex-end :与交叉轴的终点对齐。
center:与交叉轴的中点对齐。
space-between :与交叉轴两端对齐,轴线之间的间隔平均分布。
space-around:每根轴线两侧的间隔都相等。所以,轴线之间的间隔比轴线与边框的间隔 大一倍。
stretch (默认值):轴线占满整个交叉轴
6. 实现一个元素水平垂直居中
1)缺点:如果不知道宽高,这个效果就没法实现。如果数据除不尽,实现的效果存在误差。
width:200px;
height:200px;position:absolute或者fixed;
top:50%;
margin-top:-100px;
left:50%;
margin-left:-100px;
2)缺点:不适合未知宽高的元素水平垂直居中
width:333px;
height:333px;
position:fixed;
margin:auto;
top:0;
left:0;
right:0;
bottom:0;
3)优点:可以实现一个未知宽高的元素水平垂直居中 缺点:display:flex;css3新增加的;兼容到
IE10以上
html{ height:100%;}
body{ margin:0; display:flex; height:100%;}
div{ margin:auto;}
//其中:display:flex给的最近的父元素
4)
body{ margin:0;}
div{
position:fixed;
top:50%;
left:50%;
transform:translate(-50%,-50%);
}
/*top:50%; left:50%; 这个是浏览器视口整体宽高的一半 ;
transform:translate(-50%,-50%);是当前元素宽高的一半*/
7. 获取dom元素的宽高
1、Element.style.width/height
只能获取内联样式
var ele = document.getElementById('element');
console.log(ele.style.height); // '100px'
2、window.getComputedStyle(ele).width/height
IE9以上 可获取实时的style
var ele = document.getElementById('element');
console.log(window.getComputedStyle(ele).width); // '100px'
console.log(window.getComputedStyle(ele).height); // '100px'
3、Element.currentStyle.width/height
功能与第二点相同,只存在于旧版本IE中(IE9以下),除了做旧版IE兼容,就不要用它了。
4、Element.getBoundingClientRect().width/height
除了能够获取宽高,还能获取元素位置等信息
var ele = document.getElementById('element');
console.log(ele.getBoundingClientRect().width); // 100
console.log(ele.getBoundingClientRect().height); // 100
JS 基础篇
1. 原始类型有哪几种?null 是对象吗?
在 JS 中,存在着 6 种原始值,分别是:
- boolean
- null
- undefined
- number
- string
- symbol
首先原始类型存储的都是值,是没有函数可以调用的,比如 undefined.toString()
另外对于 null 来说,很多人会认为他是个对象类型,其实这是错误的。虽然 typeof null 会输出
object ,但是这只是 JS 存在的一个悠久 Bug。在 JS 的最初版本中使用的是 32 位系统,为了性能考虑
使用低位存储变量的类型信息, 000 开头代表是对象,然而 null 表示为全零,所以将它错误的判断
为 object 。虽然现在的内部类型判断代码已经改变了,但是对于这个 Bug 却是一直流传下来。
对象(Object)类型
涉及面试题:对象类型和原始类型的不同之处?函数参数是对象会发生什么问题?
在 JS 中,除了原始类型那么其他的都是对象类型了。对象类型和原始类型不同的是,原始类型存储的是值,对象类型存储的是地址(指针)。当你创建了一个对象类型的时候,计算机会在内存中帮我们开辟一个空间来存放值,但是我们需要找到这个空间,这个空间会拥有一个地址(指针)
const a = []
对于常量 a 来说,假设内存地址(指针)为 #001 ,那么在地址 #001 的位置存放了值 [] ,常量 a存放了地址(指针) #001 ,再看以下代码
const a = []
const b = a
b.push(1)
当我们将变量赋值给另外一个变量时,复制的是原本变量的地址(指针),也就是说当前变量 b 存放
的地址(指针)也是 #001 ,当我们进行数据修改的时候,就会修改存放在地址(指针) #001 上的
值,也就导致了两个变量的值都发生了改变。
接下来我们来看函数参数是对象的情况
function test(person) {
person.age = 26
person = {
name: 'yyy',
age: 30
}
return person
}
const p1 = {
name: 'yck',
age: 25
}
const p2 = test(p1)
console.log(p1) // -> {name: "yck", age: 26}
console.log(p2) // -> {name: "yyy", age: 30}
对于以上代码,你是否能正确的写出结果呢?接下来让我为你解析一番:
- 首先,函数传参是传递对象指针的副本
- 到函数内部修改参数的属性这步,我相信大家都知道,当前p1的值也被修改了
- 但是当我们重新为person分配了一个对象时就出现了分歧
所以最后person拥有了一个新的指针,也就和p1没有关系了,导致了最终两个变量的值是不同的
2. typeof VS instanceof
涉及面试题:typeof 是否能正确判断类型?instanceof 能正确判断对象的原理是什么?
typeof对于原始类型来说,除了null都可以显示正确的类型
typeof1//'number'
typeof'1'//'string'
typeofundefined//'undefined'typeoftrue//'boolean'
typeofSymbol()//'symbol'
typeof对于对象来说,除了函数都会显示object,所以说typeof并不能准确判断变量到底是什么类型
typeof[]//'object'
typeof{}//'object'
typeofconsole.log//'function'
如果我们想判断一个对象的正确类型,这时候可以考虑使用instanceof,因为内部机制是通过原型链来判断
constPerson=function(){}constp1=newPerson()
p1instanceofPerson//true
varstr='helloworld'
strinstanceofString//false
varstr1=newString('helloworld')
str1 instanceof String//true
对于原始类型来说,你想直接通过instanceof 来判断类型是不行的,当然我们还是有办法让instanceof 判断原始类型的
class PrimitiveString {
static [Symbol.hasInstance](x){
return typeof x === 'string
}
}
console.log('hello world' instanceof PrimitiveString) // true
你可能不知道 Symbol.hasInstance 是什么东西,其实就是一个能让我们自定义 instanceof 行为的
东西,以上代码等同于 typeof ‘hello world’ === ‘string’ ,所以结果自然是 true 了。这其实
也侧面反映了一个问题, instanceof 也不是百分之百可信的。
3. This指向问题:
涉及面试题:如何正确判断 this?箭头函数的 this 是什么
this 的指向,是在调用函数时根据执行上下文所动态确定的。
- 函数在浏览器全局环境中被简单调用(非显式/隐式绑定下)
严格模式下 this 绑定到 undefined,
否则绑定到全局对象 window/global; - 在执行函数时,如果函数中的this是被上一级的对象所调用,那么this指向就是上一级的对象; 否则指 向全局环境。
- 回调函数(除事件函数):
数组的所有遍历方法forEach,map,filter,reduce,every,some,flatMap,sort;这些方法均使用了回调
函数,因此在所有使用回调函数的方法中,所有回调函数中this都被指window,
'a' + + 'b' // -> "aNaN"
4 * '3' // 12
4 * [] // 0
4 * [1, 2] // NaN
let a = {
valueOf() {
return 0
},
toString() {
return '1'
}
}
a > -1 // true
setInterval,setTimeOut 函数中的回调函数的因为作用域不明(不知道在哪里调用)就会指向
window:
- 事件函数中的this:指向侦听的对象
这里的特殊情况(事件函数)是因为:在函数执行时底层函数调用了call和apply,因此此时的回调函数中的this就会被指向绑定的侦听对象上; - 在定义对象属性时,obj对象还没有创建完成;this仍旧指向window
- 一般构造函数 new 调用,绑定到新创建的对象上;
- 一般由 call/apply/bind 方法显式调用,绑定到指定参数的对象上;
面试技巧:如果把这项放到最后说下个问题多半就是三者区别 - 一般由上下文对象调用,绑定在该对象上;
- 箭头函数中,根据外层上下文绑定的 this 决定 this 指向
1、全局环境下的 this
函数在浏览器全局环境中被简单调用,ES5非严格模式下指向 window,ES6严格模式下指向
undefined。
function fn1( ) {
console.log(this) }
fn1( ) // window
function fn2( ) {'use strict'
console.log(this)}
fn2( ) // undefined
在执行函数时,如果函数中的this是被上一级的对象所调用,那么this指向就是上一级的对象; 否则指
向全局环境。
Var foo = {
bar:10,
fn:function( ) {
console.log(this)
console.log(this.bar)}
}
***\*var fn1 = foo.fn\****
fn1( ) // ***\*直接调用\****,this ***\*指向 window\****,window.bar => undefined
foo.fn( ) // 通过 foo 调用,this 指向 foo,foo.bar => 10
this.a=3;//this--->window
var b=5;
function fn(){
var b=10;
console.log(b+this.b);//this--->window
// 这种方法仅限于ES5,在ES6严格模式中this将会变成undefined
}
fn()
2、回调函数中的this
数组的所有遍历方法forEach,map,filter,reduce,every,some,flatMap,sort;这些方法均使用了回调函
数,因此在所有使用回调函数的方法中,除了特殊的情况外(事件函数),其他所有回调函数中this都被指向
window,setInterval,setTimeOut 函数中的回调函数的因为作用域不明(不知道在哪里调用)就会指向
window:
var obj = {
fn: function ( ) {
// console.log(this);
***\*return\**** function ( ) {
console.log(this);//this--->window
}
}
}
var fn=obj.fn( );
fn( );//因为是在另外的作用域调用
//return中回调函数因为相当于var fn=obj.fn( )( );是在外部执行所以会指向window
这里的特殊情况(事件函数)是因为:在函数执行时底层函数调用了call和apply,因此此时的回调函数中的this就会被指向document;
3、对象中的this
在定义属性时,obj对象还没有创建完成;this仍旧指向window
箭头函数指向当前域外的内容
var c=100;
var obj={
c:10,
b:this.c,//this--->window 定义属性时,obj对象还没有创建完成,this仍旧指向window
a:function(){
// this;//this--->obj
// console.log(obj.c);
console.log(this.c);
},
d:()=>{
//this--->window
console.log(this);
}
}
// console.log(obj);
// obj.d();
var obj1=obj;
obj=null;
obj1.a();
这里a:function( )This.c}中为什么不用obj而用this呢:因为obj的地址值可能改变;就会找不到这个引
用变量obj对象;
4、ES6class中的this
class Box{
a=3;
static abc(){
console.log(this);//Box 静态方法调用就是通过类名.方法
// Box.abc();
// 尽量不要在静态方法中使用this
}
constructor(_a){
this.a=_a }
play(){
// this就是实例化的对象
console.log(this.a);
// 这个方法是被谁执行的,this就是谁
}
let b=new Box(10);
b.play();
let c=new Box(5);
c.play();
//使用静态方法:就指向box:相当于box.abc( )调用该方法;所以指向box
class Box{
a=3;
static abc(){
console.log(this);//Box 静态方法调用就是通过类名.方法
// Box.abc();
// 尽量不要在静态方法中使用this
}
5、ES5中的this
function Box(_a){
this.a=_a;
}
Box.prototype.play=function(){
console.log(this.a);//this就是实例化的对象
}
Box.prototype.a=5;
Box.abc=function(){
//this
// 这样的方法,等同于静态方法
}
var a=new Box(10);
a.play();
Box.abc();
6、事件函数中的this:指向侦听的对象
document.addEventListener("click",clickHandler);
function clickHandler(e){
console.log(this);//this--->e.currentTarget
}
7、Call apply bind中的this:指向绑定的对象
function fn(a,b){
this.a=a;//this如果使用了call,apply,bind,this将会被指向被绑定的对象
this.b=b;
return this;
}
var obj=fn.call({},3,5)
var obj=fn.apply({},[3,5])
var obj=fn.bind({})(3,5);
*8、箭头函数中的this:指向当前函数外的函数或内容与自带bind(this)的作用
var obj={
a:function(){
document.addEventListener("click",e=>{
console.log(this);//指向事件侦听外函数中的this/obj
});
var arr=[1,2,3];
arr.forEach(item=>{
console.log(this);//this-->obj
});
// 相当于自带bind(this)的作用
arr.forEach((function(item){
}).bind(this));
}
}
4. == vs ===
涉及面试题:== 和 === 有什么区别?
对于 == 来说,如果对比双方的类型不一样的话,就会进行类型转换
假如我们需要对比 x 和 y 是否相同,就会进行如下判断流程:
- 首先会判断两者类型是否相同。相同的话就是比大小了
- 类型不相同的话,那么就会进行类型转换
- 会先判断是否在对比 null 和 undefined ,是的话就会返回 true
- 判断两者类型是否为 string 和 number ,是的话就会将字符串转换为 number
1 == '1'
↓
1 == 1
- 判断其中一方是否为 boolean ,是的话就会把 boolean 转为 number 再进行判断
'1' == true
↓
'1' == 1
↓
1 == 1
- 判断其中一方是否为 object 且另一方为 string 、 number 或者 symbol ,是的话就会把object 转为原始类型再进行判断
'1' == { name: 'yck' }
↓
'1' == '[object Object]'
5. 闭包
什么是闭包?
要理解闭包,首先必须理解Javascript特殊的变量作用域。
变量的作用域无非就是两种:全局变量和局部变量。
Javascript语言的特殊之处,就在于函数内部可以直接读取全局变量。
而闭包却是能够读取其他函数内部变量的函数。所以,在本质上,闭包就是将函数内部和函数外
部连接起来的一座桥梁。
闭包的特点
1.函数嵌套函数
2.函数内部可以引用外部的参数和变量
3.参数和变量不会被垃圾回收机制回收
因此闭包常会被用于
1可以储存一个可以长期驻扎在内存中的变量
2.避免全局变量的污染
3.保证私有成员的存在
那闭包又因为什么原因不被回收呢
简单来说,js引擎的工作分两个阶段,
一个是语法检查阶段,
一个是运行阶段。而运行阶段又分预解析和执行两个阶段。
在预解析阶段,先会创建执行上下文,执行上下文又包括变量对象、变量对象的作用域链和this指向的创建 。
创建执行上下文后,会对变量对象的属性进行填充。
进入执行代码阶段,此时执行上下文有个Scope属性该属性作为一个作用域链包含有该函数被定义时所有外层的变量对象的引用js解析器逐行读取并执行代码时当我们需要查询外部作用域的变量时,其实就是沿着作用域链,依次在这些变量对象里遍历标志符,直到最后的全局变量对象。
基于js的垃圾回收机制:在Javascript中,如果一个对象不再被引用,那么这个对象就会被GC回收。如果两个对象互相引用,而不再被第3者所引用,那么这两个互相引用的对象也会被回收。因为函数a被b引用,b又被a外的c引用,所以定义了闭包的函数虽然销毁了,但是其变量对象依然被绑定在函数上,只有仍被引用,变量会继续保存在内存中,这就是为什么函数a执行后不会被回收的原因。
变量对象VO:var声明的变量、function声明的函数,及当前函数的形参
作用域链:当前变量对象+所有父级作用域 [[scope]]
this值:在进入执行上下文后不再改变
PS:作用域链其实就是一个变量对象的链,函数的变量对象称之为active object,简称AO。函数创建后就静态的[[scope]]属性,直到函数销毁)
创建执行上下文后,会对变量对象的属性进行填充。所谓属性,就是var、function声明的标志符及函数形参名,至于属性对应的值:变量值为undefined,函数值为函数定义,形参值为实参,没有传入实参则为undefined。
闭包的应用场景
- 数据封装:闭包可以帮助我们创建具有私有变量的函数,这些变量不会被外部直接访问,从而实现封装。
- 模块化:在JavaScript等语言中,闭包常用于模块化开发,通过闭包可以创建独立的功能模块,避免全局变量的污染。
- 函数柯里化:闭包允许我们将一个多参数的函数转换成一系列单参数的函数,这在函数式编程中非常有用。
- 延迟计算:闭包可以用于实现延迟执行的逻辑,例如,在用户实际需要数据时才进行计算。
- 状态保持:在异步操作中,闭包可以保持异步操作的状态,确保回调函数能够访问到正确的上下文。
- 事件处理:在JavaScript中,闭包常用于事件监听器,确保回调函数能够访问到绑定时的作用域。
- 迭代器和生成器:闭包在迭代器和生成器模式中用于保存迭代状态,使得迭代可以跨多个函数调用持续进行。
- 高阶函数:闭包使得函数可以作为参数传递给其他函数,或者作为其他函数的返回值,这是高阶函数的基础。
- 函数工厂:闭包可以创建函数工厂,即返回一个函数的函数,这些返回的函数可以访问闭包中定义的变量。
- 记忆化:闭包可以用于实现记忆化技术,存储函数的计算结果,避免重复计算,提高性能。
- 定时器和动画:在JavaScript中,闭包可以用于定时器和动画的实现,确保回调函数能够访问到正确的状态。
- AJAX请求:在进行AJAX请求时,闭包可以确保请求完成时能够访问到请求发起时的上下文。
6. 原型
涉及面试题:如何理解原型?如何理解原型链?
1.每个对象都有 __proto__属性 ,该属性指向其构造函数的原型对象, proto 将对象和其原型对
象连接起来组成原型链
2.在调用实例的方法和属性时,如果在实例对象上找不到,就会往原型对象上找
3.构造函数的 prototype属性 也指向实例的原型对象
4.原型对象的 constructor属性 指向构造函数。
7. 继承
说到继承,最容易想到的是ES6的 extends ,当然如果只回答这个肯定不合格,我们要从函数和原型链的角度上实现继承,下面我们一步步地、递进地实现一个合格的继承实现一个方法可以从而实现对父类的属性和方法的继承,解决代码冗余重复的问题
7.1 原型链继承
原型链继承的原理很简单,
直接让子类的原型对象指向父类实例,
Child.prototype=new Parent()
当子类实例找不到对应的属性和方法时,就会往它的原型对象,也就是父类实例上找,
从而实现对父类的属性和方法的继承
原型继承的缺点:
1.由于所有Child实例原型都指向同一个Parent实例, 因此对某个Child实例的父类引用类型变量修改会影 响所有的Child实例
2.在创建子类实例时无法向父类构造传参, 即没有实现super()的功能
7.2 构造函数继承
构造函数继承,即在子类的构造函数中执行父类的构造函数,并为其绑定子类的this,
让父类的构造函数把成员属性和方法都挂到子类的this上去;
//在Child的构造函数中执行
Parent.apply(this, arguments);
这样既能避免实例之间共享一个原型实例,又能向父类构造方法传参;
js继承的方式继承不到父类原型上的属性和方法
构造函数继承的缺点
1.继承不到父类原型上的属性和方法
7.3 组合式继承
既然原型链继承和构造函数继承各有互补的优缺点, 那么我们为什么不组合起来使用呢, 所以就有了综合二者的组合式继承
Child.prototype=new Parent()
Child.prototype.constructor=Child //相当于在Child的构造函数中给Parent绑定this
组合式继承的缺点:
1.每次创建子类实例都执行了两次构造函数(Parent.call()和new Parent()),虽然这并不影响对父类的继承,但子类创建实例时,原型中会存在两份相同的属性和方法,这并不优雅
7.4 寄生式组合继承
为了解决组合式继承中构造函数被执行两次的问题,
我们将指向父类实例改为指向父类原型, 减去一次构造函数的执行
到这里我们就完成了ES5环境下的继承的实现,这种继承方式称为寄生组合式继承。
Function.prototype.extend = function (supClass) {
// 创建一个中间替代类,防止多次执行父类(超类)的构造函数
function F() { }
// 将父类的原型赋值给这个中间替代类
F.prototype = supClass.prototype;
// 将原子类的原型保存
var proto = subClass.prototype;
// 将子类的原型设置为中间替代类的实例对象
subClass.prototype = new F();
// 将原子类的原型复制到子类原型上,合并超类原型和子类原型的属性方法
// Object.assign(subClass.prototype,proto);
var names = Object.getOwnPropertyNames(proto);
for (var i = 0; i < names.length; i++) {
var desc = Object.getOwnPropertyDescriptor(proto, names[i]);
Object.defineProperty(subClass.prototype, names[i], desc);
}
// 设置子类的构造函数时自身的构造函数,以防止因为设置原型而覆盖构造函数
subClass.prototype.constructor = subClass;
// 给子类的原型中添加一个属性,可以快捷的调用到父类的原型方法
subClass.prototype.superClass = supClass.prototype;
// 如果父类的原型构造函数指向的不是父类构造函数,重新指向
if (supClass.prototype.constructor !== supClass) {
supClass.prototype.constructor = supClass;
}
}
function Ball(_a) {
this.superClass.constructor.call(this, _a);
}
Ball.prototype.play = function () {
this.superClass.play.call(this);//执行超类的play方法
console.log("end");
}
Object.defineProperty(Ball.prototype, "d", {
value: 20
})
Ball.extend(Box);
var b=new Ball(10);
console.log(b);
是目前最成熟的继承方式,babel对ES6继承的转化也是使用了寄生组合式继承
8. 深浅拷贝
涉及面试题:什么是浅拷贝?如何实现浅拷贝?什么是深拷贝?如何实现深拷贝?
浅拷贝实现
- 展开运算符 …
- Object.assign({}, a)
通常浅拷贝就能解决大部分问题了,但是当我们遇到如下情况就可能需要使用到深拷贝了
let a = {
age: 1,
jobs: {
first: 'FE'
}
}
let b = { ...a }
a.jobs.first = 'native'
console.log(b.jobs.first) // native
浅拷贝只解决了第一层的问题,如果接下去的值中还有对象的话,那么就又回到最开始的话题了,两者享有相同的地址。要解决这个问题,我们就得使用深拷贝了。
深拷贝实现
- JSON.parse(JSON.stringify(object))
但是该方法也是有局限性的:
- 会忽略 undefined
- 会忽略 symbol
- 不能序列化函数
- 不能解决循环引用的对象
- 在遇到函数、 undefined 或者 symbol 的时候,该对象也不能正常的序列化 原型链如何处理
- DOM 如何处理
- Date
- Reg
- ES6类
- null
- boolen
- array
- string
- number
实现一个深拷贝是很困难的,需要我们考虑好多种边界情况,比如原型链如何处理、DOM 如何处理等等,所以这里我们实现的深拷贝只是简易版,并且我其实更推荐使用 lodash 的深拷贝函数。
- lodash
function deepClone(obj) {
function isObject(o) {
return (typeof o === 'object' || typeof o === 'function') && o !== null
}
if (!isObject(obj)) {
throw new Error('非对象')
}
let isArray = Array.isArray(obj)
let newObj = isArray ? [...obj] : { ...obj }
Reflect.ownKeys(newObj).forEach(key => {
newObj[key] = isObject(obj[key]) ? deepClone(obj[key]) : obj[key]
})
return newObj
}
let obj = {
a: [1, 2, 3],
b: {
c: 2,
d: 3
}
}
let newObj = deepClone(obj)
newObj.b.c = 1
console.log(obj.b.c) // 2
8. new 操作符调用构造函数具体做了什么?
- 创建一个新的对象;
- 将构造函数的 this 指向这个新对象;
- 为这个对象添加属性、方法等;
- 最终返回新对象;
9. 冒泡排序如何实现,时间复杂度是多少, 还可以如何改进?
冒泡算法的原理:
升序冒泡: 两次循环,相邻元素两两比较,如果前面的大于后面的就交换位置
降序冒泡: 两次循环,相邻元素两两比较,如果前面的小于后面的就交换位置
js 实现:
// 升序冒泡 function maopao(arr){
const array = [...arr] for(let i = 0, len = array.length; i < len -
1; i++){
for(let j = i + 1; j < len; j++) {
if (array[i] > array[j]) {
let temp = array[i]
array[i] = array[j]
array[j] = temp
}
}
}
return array
}
看起来没问题,不过一般生产环境都不用这个,原因是效率低下,冒泡排序在平均和最坏情况下的时间复杂度都是 O(n^2),最好情况下都是 O(n),空间复杂度是 O(1)。因为就算你给一个已经排好序的数组,如[1,2,3,4,5,6] 它也会走一遍流程,白白浪费资源。所以有没有什么好的解决方法呢?
答案是肯定有的:加个标识,如果已经排好序了就直接跳出循环。
优化版:
function maopao(arr){
const array = [...arr]
let isOk = true for(let i = 0, len = array.length;
i < len - 1; i++){
for(let j = i + 1; j < len; j++) {
if (array[i] > array[j]) {
let temp = array[i]
array[i] = array[j]
array[j] = temp
isOk = false
}
}
if(isOk){
Break
}
}
return array}
10. 防抖、节流
10.1 防抖
即短时间内大量触发同一事件,只会执行一次函数,防抖常用于搜索框/滚动条的监听事件处理,如果不做防抖,每输入一个字/滚动屏幕,都会触发事件处理,造成性能浪费;实现原理为设置一个定时器,约定在xx毫秒后再触发事件处理,每次触发事件都会重新设置计时器,直到xx毫秒内无第二次操作。
// func是用户传入需要防抖的函数
// wait是等待时间
const debounce = (func, wait = 50) => {
// 缓存一个定时器id
let timer = 0
// 这里返回的函数是每次用户实际调用的防抖函数
// 如果已经设定过定时器了就清空上一次的定时器
// 开始一个新的定时器,延迟执行用户传入的方法
return function(...args) {
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
10.2 节流
防抖是 延迟执行 ,而节流是 间隔执行 ,和防抖的区别在于,防抖每次触发事件都重置定时器,而节流在定时器到时间后再清空定时器,函数节流即 每隔一段时间就执行一次 ,实现原理为 设置一个定时器,约定xx毫秒后执行事件,如果时间到了,那么执行函数并重置定时器 ,
// func是用户传入需要防抖的函数
// wait是等待时间
const throttle = (func, wait = 50) => {
// 上一次执行该函数的时间
let lastTime = 0
return function(...args) {
// 当前时间
let now = +new Date()
// 将当前时间和上一次执行函数时间对比
// 如果差值大于设置的等待时间就执行函数
if (now - lastTime > wait) {
lastTime = now
func.apply(this, args)
}
}
}
setInterval(
throttle(() => {
console.log(1)
}, 500),
1
)
11. TCP 三次握手和四次挥手的理解
TCP的三次握手和四次挥手是TCP协议中用于建立连接和断开连接的重要过程。以下是对这两个过程的理解:
1. TCP三次握手:
TCP的三次握手是用于建立可靠的连接的过程,确保双方都能确认对方的可达性和能够接收数据。
具体过程如下:
- 第一次握手:客户端向服务器发送一个连接请求报文段,其中包含SYN标志位设置为1,序号为A,然后进入SYN_SENT状态等待服务器的确认。客户端首先选择一个初始的序列号A,并随机生成一个初始的ISN(Initial Sequence Number)作为初始序列号。
- 第二次握手:服务器接收到客户端的连接请求报文段后,如果同意建立连接,则向客户端发送一个确认报文段,其中包含SYN和ACK标志位都设置为1,确认号为A+1,序号为B。服务器也会为该连接选择一个自己的初始序列号B,随机生成一个ISN。
- 第三次握手:客户端接收到服务器的确认报文段后,向服务器发送一个确认报文段,其中ACK标志位设置为1,确认号为B+1,序号为A+1。服务器接收到客户端的确认报文段后,连接建立成功,双方可以开始进行数据传输。
通过三次握手,可以确保双方都能确认对方的可达性和能够接收数据,建立了可靠的连接。若其中任何一次握手失败或超时,连接建立就会失败,双方不会建立连接。
TCP四次挥手:
TCP的四次挥手是用于断开连接的过程,由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。具体过程如下:
- 第一次挥手:客户端发送一个FIN报文段给服务器,关闭客户端到服务器的数据传送,客户端进入FIN_WAIT_1状态。
- 第二次挥手:服务器收到FIN报文段后,发送一个ACK报文段给客户端,确认序号为收到序号+1,服务器进入CLOSE_WAIT状态。
- 第三次挥手:服务器发送一个FIN报文段给客户端,关闭服务器到客户端的数据传送,服务器进入LAST_ACK状态。
- 第四次挥手:客户端收到FIN报文段后,客户端进入TIME_WAIT状态,接着发送一个ACK报文段给服务器,确认序号为收到序号+1,服务器进入CLOSED状态。
完成四次挥手后,连接被完全释放。第二次挥手和第三次挥手都是为了确认双方都已经完成数据的发送和接收。在第二次挥手后,客户端可以继续向服务器发送数据,直到收到服务器的FIN报文段;同样地,在第三次挥手后,服务器也可以继续向客户端发送数据,直到收到客户端的ACK报文段。
12. 介绍下重绘和回流(Repaint & Reflow),以及如何进行优化
12.1 浏览器渲染机制
浏览器采用流式布局模型(Flow Based Layout) 浏览器会把 HTML 解析成 DOM,把 CSS 解析成 CSSOM,DOM
和 CSSOM 合并就产生了渲染树(Render Tree)。 有了
RenderTree,我们就知道了所有节点的样式,然后计算他们在页面上的大小和位置,最后把节点绘制到页面上。 由于浏览器使用流式布局,对
Render Tree 的计算通常只需要遍历一次就可以完成,但 table 及其内部元素除外,他们可能需要多次计算,通常要花 3
倍于同等元素的时间,这也是为什么要避免使用 table 布局的原因之一。
12.2 重绘
由于节点的几何属性发生改变或者由于样式发生改变而不会影响布局的,称为重绘,例如 outline, visibility,
color、background-color 等,重绘的代价是高昂的,因为浏览器必须验证 DOM 树上其他节点元素的可见性。
12.3 回流
回流是布局或者几何属性需要改变就称为回流。回流是影响浏览器性能的关键 因素,因为其变化涉及到部分页面(或是整个页面)的布局更新。一个元素的回流可能会导致了其所有子元素以及 DOM 中紧随其后的节点、祖先节点元素 的随后的回流。
减少重绘与回流
CSS
1、使用 transform 替代 top
2、使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流(改变了布局)
3、避免使用 table 布局,可能很小的一个小改动会造成整个 table 的重新布局。
4、尽可能在 DOM 树的最末端改变 class,回流是不可避免的,但可以减少其影响。尽可能在 DOM 树的最末端改变 class,可以限制了回流的范围,使其影响尽可能少的节点。
5、避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多。
JavaScript
1、避免频繁操作样式,最好一次性重写 style 属性,或者将样式列表定义为 class
并一次性更改 class 属性。
2、避免频繁操作 DOM,创建一个 documentFragment,在它上面应用所有 DOM
操作,最后再把它添加到文档中。
3、避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个
变量缓存起来。
4、对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素
及后续元素频繁回流。
13. call 和 apply 的区别是什么,哪个性能更好一些
- Function.prototype.apply 和 Function.prototype.call 的作用是一样的,区别在于传入参数的不同;
- 第一个参数都是,指定函数体内 this 的指向;
- 3 第二个参数开始不同,apply 是传入带下标的集合,数组或者类数组,apply 把它传给函数作为参数,call 从第二个开始传入的参数是不固定的,都会传给函数作为参数。
- call 比 apply 的性能要好,平常可以多用 call, call 传入参数的格式正是内部所需要的格式
14.说说你了解的js数据结构
1. 什么是数据结构
数据结构是计算机存储、组织数据的方式。
数据结构意味着接口或封装:一个数据结构可被视为两个函数之间的接口,或者是由数据类型联合组成的存储内容的访问方法封装。
我们每天的编码中都会用到数据结构
数组是最常见的数据结构:
1.1 数组
1.2 栈
1.3 队列
1.4 链表
1.5 字典
1.6 散列表
1.7 树
1.8 图
1.9 堆
2. 数组
数组是最基本的数据结构,很多语言都内置支持数组
数组是使用一块连续的内存空间保存数据,保存的数据的个数在分配内存的时候就是确定的。
在日常生活中,人们经常使用列表:待办事项列表、购物清单等。
而计算机程序也在使用列表,在下面条件下,选择列表作为数据结构就显得尤为有用:
数据结构较为简单
不需要在一个长序列中查找元素,或者对其进行排序。
反之,如果数据结构非常复杂,列表的作用就没有那么大了。
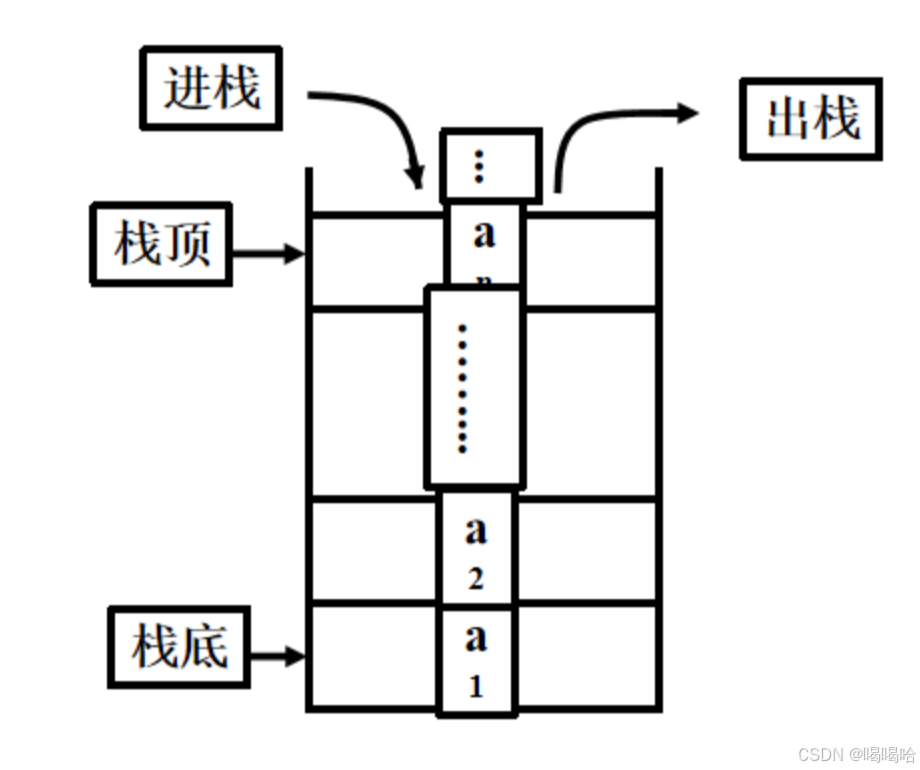
3. 栈
栈是一种遵循后进先出原则的有序集合
在栈里,新元素都接近栈顶,旧元素都接近栈底。
每次加入新的元素和拿走元素都在顶部操作
4. 队列
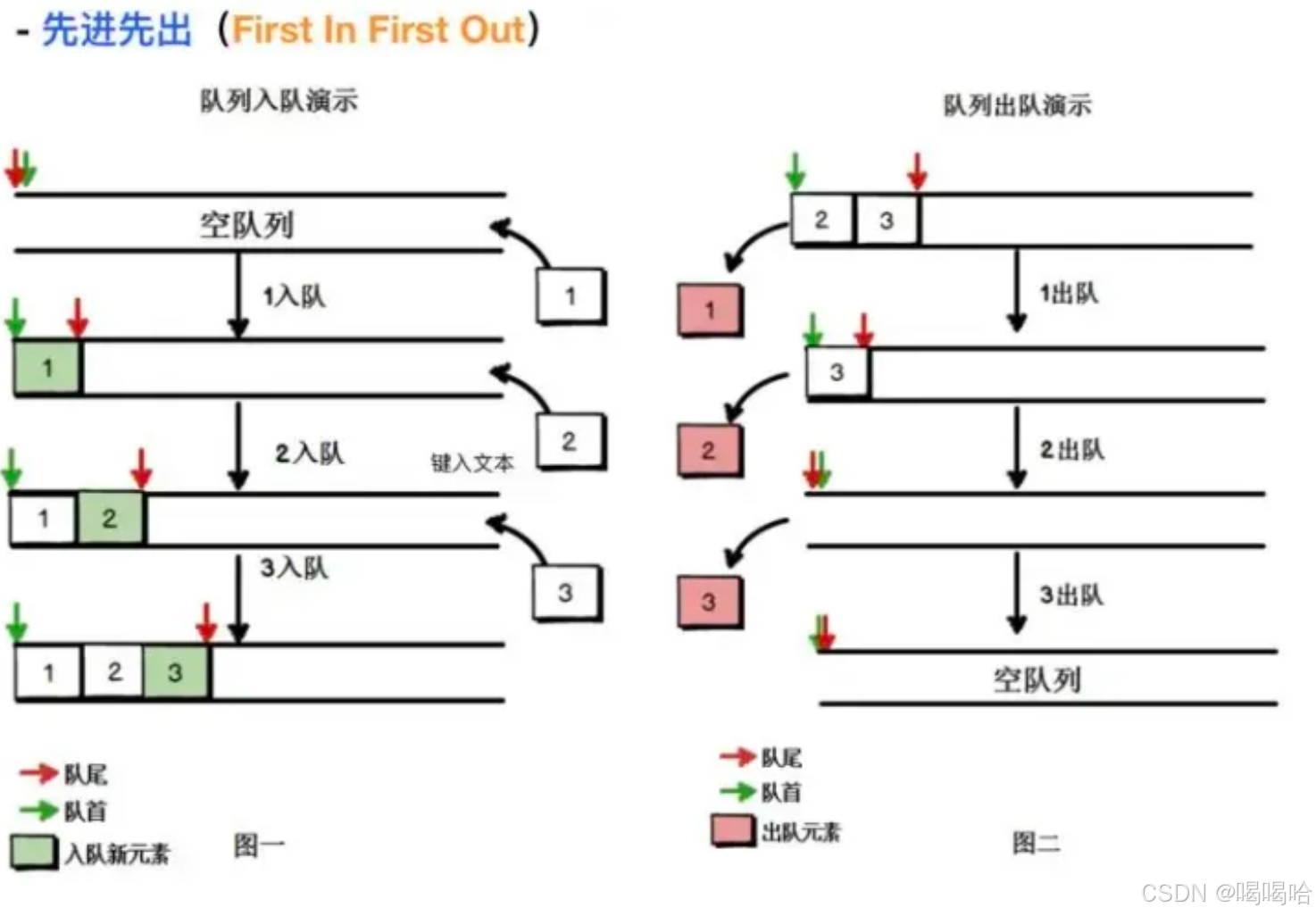
队列是遵循先进先出原则的一组有序的项,队列在尾部添加新元素,并从顶部移除元素
最新添加的元素必须排在队列的末尾
5. 链表
链表也是一种列表,已经设计了数组,为什么还需要链表呢?
javascript中数组的主要问题时,他们被实现成了对象,与其它语言(c++,java)的数组相对,效率很低。
如果你发现数组在实际使用时很慢,就可以考虑使用链表来代替他。
使用条件:
链表几乎可以用在任何可以使用的一维数组的情况中。
如果需要随机访问,数组仍然是更好的选择。
6. 字典
字典是一种以键-值对存储数据结的数据结构,js中的object类就是以字典形式设计的。javascript可以通过实现字典类,让这种字典类型的对象使用起来更加简单,字典可以实现对象拥有的常见功能,并相应拓展自己想要的功能,而对象在javascript编写中随处可见,所以字典的作用也异常明显了。
7. 散列表
也称为哈希表,特点是在散列表上插入、删除和取用数据都非常快。
为什么要设计这种数据结构呢
用数组或链表存储数据,如果想要找到其中一个数据,需要从头进行遍历,因为不知道这个数据存储到了数组的哪个位置。
散列表在javascript中可以基于数据去进行设计。
数组的长度是预先设定好的,所有元素根据和该元素对应的键,保存在数组的特定位置,这里的键和对象是类型的概念。
使用散列表存储数组是,通过一个散列函数将键映射为一个数字,这个数字的范围是0到散列表的长度。
即使使用一个高效的散列函数,依然存在将两个键映射为同一个值的可能,这种现象叫做碰撞。常见碰撞的处理方法有:开链法和线性探测法
使用条件:可以用于数据的插入、删除和取用,不适用于查找数据。
ES6篇
1. 介绍下 Set、Map、WeakSet 和 WeakMap 的区别?
Set——对象允许你存储任何类型的唯一值,无论是原始值或者是对象引用
WeakSet——成员都是对象;成员都是弱引用,可以被垃圾回收机制回收,可以
用来保存 DOM 节点,不容易造成内存泄漏;
Map——本质上是键值对的集合,类似集合;可以遍历,方法很多,可以跟各
种数据格式转换。
WeakMap——只接受对象最为键名(null 除外),不接受其他类型的值作为键
名;键名是弱引用,键值可以是任意的,键名所指向的对象可以被垃圾回收,
此时键名是无效的;不能遍历,方法有 get、set、has、delete。
2. var、let 及 const 区别
涉及面试题:什么是提升?什么是暂时性死区?var、let 及 const 区别?
函数提升优先于变量提升,函数提升会把整个函数挪到作用域顶部,变量提升只会把声明挪
到作用域顶部
var 存在提升,我们能在声明之前使用。 let 、 const 因为暂时性死区的原因,不能在声明前使用
var 在全局作用域下声明变量会导致变量挂载在 window 上,其他两者不会
let 和 const 作用基本一致,但是后者声明的变量不能再次赋值
3. es6新增了什么?
- 类(Class):可以通过class关键字定义一个类,内部使用constructor定义构造方法,使用new关键字创建实例
class Person {
constructor(name, age) {
this.name = name;
this.age = age;
}
greet() {
console.log(`Hello, my name is ${this.name}`);
}
}
const person = new Person('Alice', 25);
person.greet(); // Hello, my name is Alice
- 模板字符串(Template Literals):用反引号包围的字符串,可以内嵌表达式和行终止字符
const name = 'Alice';
const age = 25;
console.log(`Hello, my name is ${name} and I am ${age} years old.`);
- 箭头函数(Arrow Functions):简化了函数的定义。
const add = (a, b) => a + b;
console.log(add(5, 3)); // 8
- let和const声明:提供块级作用域,let用于变量声明,const用于常量声明。
let x = 10;
x = 20; // OK
const y = 30;
// y = 40; // Error: Assignment to constant variable.
- Iterator和Generator:提供了一种新的迭代方式,可以自定义迭代器。
function* fibonacci() {
let a = 0;
let b = 1;
while (true) {
yield a;
[a, b] = [b, a + b];
}
}
const fib = fibonacci();
console.log(fib.next().value); // 0
console.log(fib.next().value); // 1
console.log(fib.next().value); // 1
// ...
- Promise:用于处理异步操作,可以避免回调地狱。
const fetchData = new Promise((resolve, reject) => {
// 模拟异步操作
setTimeout(() => {
const data = 'Some data';
if (data) {
resolve(data);
} else {
reject('Error: Data not found');
}
}, 1000);
});
fetchData.then(data => console.log(data))
.catch(error => console.error(error));
4. async/await、promise和setTimeout
async/await、Promise 和 setTimeout 都是JavaScript中处理异步操作的重要概念,但它们各自有不同的用途和特性。
4.1 Promise
Promise 是代表异步操作最终完成或失败的对象。它有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。
Promise 构造函数接受一个执行器函数,该函数有两个参数:resolve 和 reject,分别用于将 Promise 标记为已完成(并传递一个值)或已失败(并传递一个原因)。
const promise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('操作成功完成');
}, 1000);
});
promise.then(result => {
console.log(result); // "操作成功完成"
}).catch(error => {
console.error(error);
});
4.2 async/await
async/await 是建立在 Promise 之上的语法糖,它使得异步代码看起来更像同步代码。
async 函数总是返回一个 Promise。如果在 async 函数中返回一个值,那么这个值会被 Promise.resolve() 包裹并返回。如果 async 函数中抛出一个错误,那么这个错误会被 Promise.reject() 包裹并返回。
await 只能在 async 函数内部使用,它会暂停 async 函数的执行并等待 Promise 完成,然后恢复 async 函数的执行并返回解析后的值(或抛出异常)。
4.3 3. setTimeout
setTimeout 是一个浏览器提供的全局函数,用于在指定的毫秒数后执行函数或指定的代码。它返回一个表示定时器的ID,可以使用 clearTimeout 函数来取消它。
setTimeout 的回调函数是在异步上下文中执行的,因此它不会阻塞其他代码的执行。
setTimeout(() => {
console.log('这是通过setTimeout在1秒后执行的');
}, 1000);
console.log('这是立即执行的');
总结:
Promise 是处理异步操作的对象,它表示一个最终可能完成(也可能失败)的异步操作及其结果值。
async/await 是建立在 Promise 之上的语法糖,它使得异步代码更易于阅读和理解。
setTimeout 是一个用于在指定时间后执行代码的浏览器API,它的回调函数是在异步上下文中执行的。
5. forEach Map的区别
在JavaScript中,forEach 和 map 都是数组(Array)对象上的方法,用于遍历数组的元素。但是,它们之间存在一些重要的差异。
- forEach
forEach 方法用于遍历数组的每个元素,并对每个元素执行提供的函数。但是,forEach 不会返回一个新数组,而是直接在原始数组上进行操作(尽管它实际上并不修改数组中的元素值,除非你在回调函数中显式地这样做)。
示例:
const numbers = [1, 2, 3, 4, 5];
numbers.forEach(function(number, index, array) {
console.log(number); // 依次输出 1, 2, 3, 4, 5
// 注意:forEach 不会返回一个新数组
});
- map
map 方法也用于遍历数组的每个元素,但是它会将回调函数的结果组成一个新数组返回。原始数组不会被改变。
示例:
const numbers = [1, 2, 3, 4, 5];
const doubled = numbers.map(function(number) {
return number * 2;
});
console.log(doubled); // 输出 [2, 4, 6, 8, 10]
// 注意:numbers 数组没有被改变
总结:
forEach:遍历数组,对每个元素执行操作,但不返回新数组。
map:遍历数组,对每个元素执行操作,并返回一个新数组,其中包含了操作的结果。
选择使用哪个方法取决于你的具体需求:如果你只是想遍历数组而不关心返回值,那么使用 forEach;如果你需要基于原始数组创建一个新数组,那么使用 map。
6. 箭头函数与普通函数(function)的区别是什么?构造函数(function)可以使用 new 生成实例,那么箭头函数可以吗?为什么?
箭头函数是普通函数的简写,可以更优雅的定义一个函数,和普通函数相比,
有以下几点差异:
- 函数体内的 this 对象,就是定义时所在的对象,而不是使用时所在的对 象。
- 不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可 以用 rest 参数代替。
- 不可以使用 yield 命令,因此箭头函数不能用作 Generator 函数。
- 不可以使用 new 命令,因为:
1.没有自己的 this,无法调用 call,apply。
2.没有 prototype 属性 ,而 new 命令在执行时需要将构造函数的 prototype 赋值给新的对象的 proto
//new 过程大致是这样的
function newFunc(father, ...rest) {
var result = {};
result.__proto__ = father.prototype;
var result2 = father.apply(result, rest);
if (
(typeof result2 === 'object' || typeof result2 === 'function') &&
result2 !== null
) {
return result2;
}
return result;
}
React 篇
1. React的特点和优势
1. 虚拟DOM
我们以前操作dom的方式是通过document.getElementById()的方式,这样的过程实际上是先去读取
html的dom结构,将结构转换成变量,再进行操作。
而reactjs定义了一套变量形式的dom模型,一切操作和换算直接在变量中,这样减少了操作真实
dom,性能真实相当的高,和主流MVC框架有本质的区别,并不和dom打交道
2. 组件系统
react最核心的思想是将页面中任何一个区域或者元素都可以看做一个组件 component
那么什么是组件呢?
组件指的就是同时包含了html、css、js、image元素的聚合体
if (typeof setImmediate !== "undefined" && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks);
};
} else if (
typeof MessageChannel !== "undefined" &&
(isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === "[object MessageChannelConstructor]")
) {
const channel = new MessageChannel();
const port = channel.port2;
channel.port1.onmessage = flushCallbacks;
macroTimerFunc = () => {
port.postMessage(1);
};
} else {
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0);
};
}
使用react开发的核心就是将页面拆分成若干个组件,并且react一个组件中同时耦合了css、js、
image,这种模式整个颠覆了过去的传统的方式
3. 单向数据流
其实reactjs的核心内容就是数据绑定,所谓数据绑定指的是只要将一些服务端的数据和前端页面绑定
好,开发者只关注实现业务就行了
4. JSX 语法
在vue中,我们使用render函数来构建组件的dom结构性能较高,因为省去了查找和编译模板的过程,
但是在render中利用createElement创建结构的时候代码可读性较低,较为复杂,此时可以利用jsx语法来在render中创建dom,解决这个问题,但是前提是需要使用工具来编译jsx。
2. React 中 setState 什么时候是同步的,什么时候是异步的?
1、由 React 控制的事件处理程序,以及生命周期函数调用 setState 不会同步更新 state 。
2、React 控制之外的事件中调用 setState 是同步更新的。比如原生 js 绑定的事件,setTimeout/setInterval 等。
下面的代码输出什么?
class Example extends React.Component {
constructor() {
super();
this.state = {
val: 0,
};
}
componentDidMount() {
this.setState({ val: this.state.val + 1 });
console.log(this.state.val);
// 第 1 次 log
this.setState({ val: this.state.val + 1 });
console.log(this.state.val);
// 第 2 次 log
setTimeout(() => {
this.setState({ val: this.state.val + 1 });
console.log(this.state.val);
// 第 3 次 log
this.setState({ val: this.state.val + 1 });
console.log(this.state.val);
// 第 4 次 log
}, 0);
}
render() {
return null;
}
}
//答: 0, 0, 1, 2
3. react-router 里的 link标签和 a标签有什么区别?
如何禁掉 标签默认事件,禁掉之后如何实现跳转。
答:
Link 点击事件 handleClick 部分源码:
if (_this.props.onClick) _this.props.onClick(event);
if (
!event.defaultPrevented && // onClick prevented default
event.button === 0 && // ignore everything but left
clicks !_this.props.target && // let browser handle "target=_blank"
etc. !isModifiedEvent(event) // ignore clicks with modifier keys
) {
event.preventDefault();
var history = _this.context.router.history;
var _this$props = _this.props,
replace = _this$props.replace,
to = _this$props.to;
if (replace) {
history.replace(to);
} else {
history.push(to);
}
}
Link 做了 3 件事情:
- 有 onclick 那就执行 onclick
- click 的时候阻止 a 标签默认事件(这样子点击<a href=“/abc”>123</a>就不会跳转和刷新页面)
- 再取得跳转 href(即是 to),用 history(前端路由两种方式之一,history& hash)跳转,此时只是链接变了,并没有刷新页面
4. 生命周期
- 在 V16 版本中引入了 Fiber 机制。这个机制一定程度上的影响了部分生命周期的调用,并且也引入了新的 2 个 API 来解决问题,关于 Fiber 的内容将会在下一章节中讲到。
- 在之前的版本中,如果你拥有一个很复杂的复合组件,然后改动了最上层组件的 state ,那么调用栈可能会很长
- 调用栈过长,再加上中间进行了复杂的操作,就可能导致长时间阻塞主线程,带来不好的用户体验。Fiber 就是为了解决该问题而生。
- Fiber 本质上是一个虚拟的堆栈帧,新的调度器会按照优先级自由调度这些帧,从而将之前的同步渲染改成了异步渲染,在不影响体验的情况下去分段计算更新。
- 对于如何区别优先级,React 有自己的一套逻辑。对于动画这种实时性很高的东西,也就是 16 ms 必须渲染一次保证不卡顿的情况下,React 会每 16 ms(以内) 暂停一下更新,返回来继续渲染动画。
- 对于异步渲染,现在渲染有两个阶段: reconciliation 和 commit 。前者过程是可以打断的,后者
不能暂停,会一直更新界面直到完成。
Reconciliation 阶段
-
componentWillMount
-
componentWillReceiveProps
-
shouldComponentUpdate
-
componentWillUpdate
Commit 阶段
-
componentDidMount
-
componentDidUpdate
-
componentWillUnmount
因为 Reconciliation 阶段是可以被打断的,所以 Reconciliation 阶段会执行的生命周期函数就可能会出现调用多次的情况,从而引起 Bug。由此对于 Reconciliation 阶段调用的几个函数,除了
shouldComponentUpdate 以外,其他都应该避免去使用,并且 V16 中也引入了新的 API 来解决这个
问题。
getDerivedStateFromProps 用于替换 componentWillReceiveProps ,该函数会在初始化和update 时被调用
getSnapshotBeforeUpdate 用于替换 componentWillUpdate ,该函数会在 update 后 DOM 更新
前被调用,用于读取最新的 DOM 数据。
React中组件也有生命周期,也就是说也有很多钩子函数供我们使用, 组件的生命周期,我们会分为四个阶段,初始化、运行中、销毁、错误处理(16.3之后)

5. 通信
其实 React 中的组件通信基本和 Vue 中的一致。同样也分为以下三种情况:
- 父子组件通信
- 兄弟组件通信
- 跨多层级组件通信
- 任意组件
父子通信
父组件通过 props 传递数据给子组件,子组件通过调用父组件传来的函数传递数据给父组件,这两种
方式是最常用的父子通信实现办法。
这种父子通信方式也就是典型的单向数据流,父组件通过 props 传递数据,子组件不能直接修改
props , 而是必须通过调用父组件函数的方式告知父组件修改数据。
兄弟组件通信
对于这种情况可以通过共同的父组件来管理状态和事件函数。比如说其中一个兄弟组件调用父组件传递过来的事件函数修改父组件中的状态,然后父组件将状态传递给另一个兄弟组件。\
跨多层次组件通信
如果你使用 16.3 以上版本的话,对于这种情况可以使用 Context API。
// 创建 Context,可以在开始就传入值
const StateContext = React.createContext()
class Parent extends React.Component {
render () {
return (
// value 就是传入 Context 中的值
<StateContext.Provider value='yck'>
<Child />
</StateContext.Provider>
)
}
}
class Child extends React.Component {
render () {
return (
<ThemeContext.Consumer>
// 取出值
{context => (
name is { context }
)}
</ThemeContext.Consumer>
);
}
}
context.js
import React from 'react'
const {
Provider,
Consumer: MapCounsumer
} = React.createContext();
class MapProvider extends React.Component {
constructor() {
super();
this.state = {
showMap: JSON.parse(localStorage.getItem('showMap')) || false
}
}
changeStatus = () => {
this.setState((preState) => {
return {
showMap: !preState.showMap
}
}, () => {
localStorage.setItem('showMap', this.state.showMap)
})
}
render() {
return (
<Provider value={{
showMap: this.state.showMap,
changeStatus: this.changeStatus
}}>
{
this.props.children
}
</Provider>
)
}
}
export {
MapProvider,
MapCounsumer
}
//index.js
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import "assets/styles/reset.css"
import { MapProvider } from './context/MapContext'
ReactDOM.render(
<MapProvider>
<App />
</MapProvider>
,
document.getElementById('root')
);
more.js
import React, { Component } from 'react'
import {Switch} from 'antd-mobile'
import {MapCounsumer} from 'context/MapContext'
export default class More extends Component {
render() {
return (
<MapCounsumer>
{
({showMap,changeStatus})=>{
return (
<>
地图:
<Switch checked={showMap} onChange={changeStatus}></Switch>
</>
)
}
}
</MapCounsumer>
)
}
}
任意组件
这种方式可以通过 Redux 或者 Event Bus 解决,另外如果你不怕麻烦的话,可以使用这种方式解决上述所有的通信情况
6. 循环渲染中 为什么推荐不用index做可key
在react的循环渲染中,不推荐使用数组的index(索引)作为元素的key,主要基于以下几点理由:
- 列表顺序的变化:如果列表项的顺序会发生变化(如排序、增加、删除操作),使用index作为key可能会导致性能问题和组件状态的错误。这是因为react依赖key来判断哪些元素是新元素、哪些被移除,以及哪些元素的位置发生了变化。当使用index作为key时,即使数据项的内容改变了,key仍然保持不变,导致react无法正确识别和优化渲染。
- 性能问题:当列表项发生变动时,如果使用index作为key,react可能会做更多的dom操作来更新视图,因为它无法准确的通过key识别哪些元素是新的,哪些元素被移动了位置。这可能导致不必要的重渲染和性能下降。
- 组件状态的问题:对于使用state的组件,如果列表项的顺序改变,使用index作为key可能会导致状态错乱。例如,当你删除一个列表项时,后面的项会移上来,他们的index改变了,如果他们有独立的状态,这时会由于index作为key使得状态与视图匹配错误。
因此,推荐的做法是使用唯一的、稳定的标识符(如数据库中的id或者具有唯一性的hash值等)作为key,这样无论数据如何变化,每个元素的key都是稳定的,可以帮助react更准确、更高效的进行dom的对比如更新。
VUE篇
1. MVC和MVVM 、MVP
MVC,MVP,MVVM是三种常见的前端架构模式,通过分离关注点来改进代码组织方式。MVC模式是
MVP,MVVM模式的基础,这两种模式更像是MVC模式的优化改良版,他们三个的MV即Model,view都是相同的,不同的是MV之间的桥梁连接部分。
一、MVC
视图(View):用户界面,只负责渲染 HTML
控制器(Controller):业务逻辑,负责调度 model 和 view
模型(Model):数据保存,只负责存储数据、请求数据、更新数据
MVC允许在不改变视图情况下改变视图对用户输入的响应方式,用户对View操作交给Controller处理在Controller中响应View的事件调用Model的接口对数据进行操作,一旦Model发生变化便通知相关视图View进行更新。
接受用户指令时,MVC 可以分成两种方式。一种是通过 View 接受输入,传递给 Controller。另一种是直接通过controller接受指令。此处只画了第一种情况。

但是 MVC 有一个巨大的缺陷就是控制器承担的责任太大了,随着项目愈加复杂,控制器中的代码会越来越臃肿,导致出现不利于维护的情况。
二、MVP
MVP 模式将 Controller 改名为 Presenter,同时改变了通信方向。
与MVC最大的区别就是View和Model层完全解耦,不在有依赖关系,而是通过Presenter做桥梁,用于
操作view层发出的事件传递到presenter层中,presenter层去操作model层,并且将数据返回给view
层,整个过程中view层和model层完全没有联系。

三、MVVM
MVVM 模式将 Presenter 改名为 ViewModel,基本上与 MVP 模式完全一致。唯一的区别是,它采用双
向绑定(data-binding),View的变动,自动反映在 ViewModel,反之亦然。

这里我们拿典型的MVVM模式的代表,Vue,来举例:
<div id="app-5">
<p>{{ message }}</p>
<button v-on:click="reverseMessage">逆转消息</button>
</div>
var app5 = new Vue({
el: '#app-5',
data: {
message: 'Hello Vue.js!'
},
methods: {
reverseMessage: function () {
this.message = this.message.split('').reverse().join('')
}
}
})
这里的html部分相当于View层,可以看到这里的View通过通过模板语法来声明式的将数据渲染进DOM
元素,当ViewModel对Model进行更新时,通过数据绑定更新到View。
2. Virtual DOM 虚拟DOM
涉及面试题:什么是 Virtual DOM?为什么 Virtual DOM 比原生 DOM 快?
想必大家都听过操作 DOM 性能很差,但是这其中的原因是什么呢?
因为 DOM 是属于渲染引擎中的东西,而 JS 又是 JS 引擎中的东西。当我们通过 JS 操作 DOM 的时候,其实这个操作涉及到了两个线程之间的通信,那么势必会带来一些性能上的损耗。操作 DOM 次数一多,也就等同于一直在进行线程之间的通信,并且操作 DOM 可能还会带来重绘、回流的情况,所以也就导致了性能上的问题。那么既然 DOM 可以通过 JS 对象来模拟,反之也可以通过 JS 对象来渲染出对应的 DOM。当然了,通过 JS 来模拟 DOM 并且渲染对应的 DOM 只是第一步,难点在于如何判断新旧两个 JS 对象的最小差异并且实现局部更新 DOM。首先 DOM 是一个多叉树的结构,如果需要完整的对比两颗树的差异,那么需要的时间复杂度会是 O(n^ 3),这个复杂度肯定是不能接受的。于是 React 团队优化了算法,实现了 O(n) 的复杂度来对比差异。实现 O(n) 复杂度的关键就是只对比同层的节点,而不是跨层对比,这也是考虑到在实际业务中很少会去跨层的移动 DOM 元素。 所以判断差异的算法就分为了两步首先从上至下,从左往右遍历对象,也就是树的深度遍历,这一步中会给每个节点添加索引,便于最后渲染差异一旦节点有子元素,就去判断子元素是否有不同当我们判断出以上的差异后,就可以把这些差异记录下来。当对比完两棵树以后,就可以通过差异
去局部更新 DOM,实现性能的最优化。
当然了 Virtual DOM 提高性能是其中一个优势,其实最大的优势还是在于:
- 将 Virtual DOM 作为一个兼容层,让我们还能对接非 Web 端的系统,实现跨端开发。
- 同样的,通过 Virtual DOM 我们可以渲染到其他的平台,比如实现 SSR、同构渲染等等。
- 实现组件的高度抽象化
3. 路由原理
涉及面试题:前端路由原理?两种实现方式有什么区别?
前端路由实现起来其实很简单,本质就是监听 URL 的变化,然后匹配路由规则,显示相应的页面,并且无须刷新页面。目前前端使用的路由就只有两种实现方式
- Hash 模式
点击跳转或者浏览器历史跳转当 # 后面的哈希值发生变化时,不会向服务器请求数据,可以通过
hashchange 事件来监听到 URL 的变化,从而进行跳转页面
手动刷新不会触发hashchange事件,可以采用load事件监听解析URL
匹配相应的路由规则,跳转到相应的页面,然后通过DOM替换更改页面内容 - History 模式
利用history API实现url地址改变, 网页内容改变
History.back()、History.forward()、History.go()移动到以前访问过的页面时,页面通常是从
浏览器缓存之中加载,而不是重新要求服务器发送新的网页
History.pushState()
用于在历史中添加一条记录。该方法接受三个参数,依次为一个与添加的记录相关联的状态对象:
state;新页面的标题title;必须与当前页面处在同一个域下的新的网址url
该方法不会触发页面刷新,只是导致 History 对象发生变化,地址栏会有反应,不会触发
hashchange事件
History.replaceState() 方法用来修改 History 对象的当前记录
路由原理:本质就是监听 URL 的变化,然后匹配路由规则,显示相应的页面,并且无须刷新
路由需要实现三个功能:
①浏览器地址变化,切换页面;
②点击浏览器【后退】、【前进】按钮,网页内容跟随变化;
③刷新浏览器,网页加载当前路由对应内容
两种模式对比
Hash 模式只可以更改 # 后面的内容,History 模式可以通过 API 设置任意的同源 URL
History 模式可以通过 API 添加任意类型的数据到历史记录中,Hash 模式只能更改哈希值,也就
是字符串
Hash 模式无需后端配置,并且兼容性好。History 模式在用户手动输入地址或者刷新页面的时候
会发起 URL 请求,后端需要配置 index.html 页面用于匹配不到静态资源的时候
4. Vue 和 React 之间的区别
Vue 的表单可以使用 v-model 支持双向绑定,相比于 React 来说开发上更加方便,当然了 v-model 其实就是个语法糖,本质上和 React 写表单的方式没什么区别。
改变数据方式不同,Vue 修改状态相比来说要简单许多,React 需要使用 setState 来改变状态,并且使用这个 API 也有一些坑点。并且 Vue 的底层使用了依赖追踪,页面更新渲染已经是最优的了,但是React 还是需要用户手动去优化这方面的问题。
React 需要使用 JSX,有一定的上手成本,并且需要一整套的工具链支持,但是完全可以通过 JS 来控制页面,更加的灵活。Vue 使用了模板语法,相比于 JSX 来说没有那么灵活,但是完全可以脱离工具链,通过直接编写 render 函数就能在浏览器中运行。
在生态上来说,两者其实没多大的差距,当然 React 的用户是远远高于 Vue 的。
在上手成本上来说,Vue 一开始的定位就是尽可能的降低前端开发的门槛,然而 React 更多的是去改变用户去接受它的概念和思想,相较于 Vue 来说上手成本略高。
5. 生命周期函数
Vue实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模板、挂载Dom、渲染→更新→渲染、销毁等一系列过程,我们称这是Vue的生命周期。通俗说就是Vue实例从创建到销毁的过程,就是生命周期。
每一个组件或者实例都会经历一个完整的生命周期,总共分为三个阶段:初始化、运行中、销毁。
- 实例、组件通过new Vue() 创建出来之后会初始化事件和生命周期,然后就会执行beforeCreate钩
子函数,这个时候,数据还没有挂载呢,只是一个空壳,无法访问到数据和真实的dom,一般不
做操作 - 挂载数据,绑定事件等等,然后执行created函数,这个时候已经可以使用到数据,也可以更改数
据,在这里更改数据不会触发updated函数,在这里可以在渲染前倒数第二次更改数据的机会,不
会触发其他的钩子函数,一般可以在这里做初始数据的获取 - 接下来开始找实例或者组件对应的模板,编译模板为虚拟dom放入到render函数中准备渲染,然
后执行beforeMount钩子函数,在这个函数中虚拟dom已经创建完成,马上就要渲染,在这里也可
以更改数据,不会触发updated,在这里可以在渲染前最后一次更改数据的机会,不会触发其他的
钩子函数,一般可以在这里做初始数据的获取 - 接下来开始render,渲染出真实dom,然后执行mounted钩子函数,此时,组件已经出现在页面
中,数据、真实dom都已经处理好了,事件都已经挂载好了,可以在这里操作真实dom等事情… - 当组件或实例的数据更改之后,会立即执行beforeUpdate,然后vue的虚拟dom机制会重新构建
虚拟dom与上一次的虚拟dom树利用diff算法进行对比之后重新渲染,一般不做什么事儿 - 当更新完成后,执行updated,数据已经更改完成,dom也重新render完成,可以操作更新后的
虚拟dom - 当经过某种途径调用$destroy方法后,立即执行beforeDestroy,一般在这里做一些善后工作,例
如清除计时器、清除非指令绑定的事件等等 - 组件的数据绑定、监听…去掉后只剩下dom空壳,这个时候,执行destroyed,在这里做善后工作
也可以
beforeCreate:此时获取不到prop和data中的数据; created:可以获取到prop和data中的数据;
beforeMount:获取到了VDOM; mounted:VDOM解析成了真实DOM; beforeUpdate:在更新之前调用;
updated:在更新之后调用; keep-alive:切换组件之后,组件放进activated,之前的组件放进deactivated;
beforeDestory:在组件销毁之前调用,可以解决内存泄露的问题,如setTimeout和setInterval造成的 问题。
destory:组件销毁之后调用。
6. 简要介绍Vuex原理
Vuex实现了一个单向数据流,在全局拥有一个State存放数据,当组件要更改State中的数据时,必须通过Mutation进行,Mutation同时提供了订阅者模式供外部插件调用获取State数据的更新。而当所有异步操作(常见于调用后端接口异步获取更新数据)或批量的同步操作需要走action,但action也是无法直接修改State的,还是需要通过Mutation来修改State的数据。最后,根据State的变化,渲染到视图上。
7. 组件之间数据共享
组件是 vue.js最强大的功能之一,而组件实例的作用域是相互独立的,这就意味着不同组件之间的数据无法相互引用。针对不同的使用场景,如何选择行之有效的通信方式?
1:props emit 缺点:如果组件嵌套层次多的话,数据传递比较繁琐
2:provide inject (依赖注入),缺点:不支持响应式
3:this.
r
o
o
t
t
h
i
s
.
root this.
rootthis.parent this.$refs
4: eventbus 缺点:数据不支持响应式
5: vuex 缺点:数据的读取和修改需要按照流程来操作,不适合小型项目
父子通信:
父组件向子组件传递数据可以通过 props ;
子组件向父组件是通过 $emit 、 $on 事件;
provide / inject ;
还可以通过 $root 、 $parent 、 $refs 属性相互访问组件实例;
兄弟通信: eventbus ; Vuex ;
跨级通信: eventbus ; Vuex ; provide / inject;
8. Vue中如何扩展一个组件
- 常见的组件扩展方法有:mixins,slots,extends等
- 混入mixins是分发 Vue 组件中可复用功能的非常灵活的方式。混入对象可以包含任意组件选项。当组件使用混入对象时,所有混入对象的选项将被混入该组件本身的选项。
// 复用代码:它是一个配置对象,选项和组件里面一样
const mymixin = {
methods: {
dosomething(){}
}
}
// 全局混入:将混入对象传入
Vue.mixin(mymixin)
// 局部混入:做数组项设置到mixins选项,仅作用于当前组件
const Comp = {
mixins: [mymixin]
}
- 插槽主要用于vue组件中的内容分发,也可以用于组件扩展。
子组件Child
<div>
<slot>这个内容会被父组件传递的内容替换</slot>
</div>
父组件Parent
<div>
<Child>来自老爹的内容</Child>
</div>
如果要精确分发到不同位置可以使用具名插槽,如果要使用子组件中的数据可以使用作用域插槽。
- 组件选项中还有一个不太常用的选项extends,也可以起到扩展组件的目的
// 扩展对象
const myextends = {
methods: {
dosomething(){}
}
}
// 组件扩展:做数组项设置到extends选项,仅作用于当前组件
// 跟混入的不同是它只能扩展单个对象
// 另外如果和混入发生冲突,该选项优先级较高,优先起作用
const Comp = {
extends: myextends
}
- 混入的数据和方法不能明确判断来源且可能和当前组件内变量产生命名冲突,vue3中引入的composition api,可以很好解决这些问题,利用独立出来的响应式模块可以很方便的编写独立逻辑并提供响应式的数据,然后在setup选项中组合使用,增强代码的可读性和维护性。例如:
// 复用逻辑1
function useXX() {}
// 复用逻辑2
function useYY() {}
// 逻辑组合
const Comp = {
setup() {
const {xx} = useXX()
const {yy} = useYY()
return {xx, yy}
}
}
mixins原理:
https://github1s.com/vuejs/core/blob/HEAD/packages/runtime-core/src/apiCreateApp.ts#L232-L233
https://github1s.com/vuejs/core/blob/HEAD/packages/runtime-core/src/componentOptions.ts#L545
slots原理:
https://github1s.com/vuejs/core/blob/HEAD/packages/runtime-core/src/componentSlots.ts#L129-L130
https://github1s.com/vuejs/core/blob/HEAD/packages/runtime-core/src/renderer.ts#L1373-L1374
https://github1s.com/vuejs/core/blob/HEAD/packages/runtime-core/src/helpers/renderSlot.ts#L23-L24
9.Vue要做权限管理该怎么做?控制到按钮级别的权限怎么做?
权限管理一般需求是两个:页面权限和按钮权限,从这两个方面论述即可。

思路
- 权限管理需求分析:页面和按钮权限
- 权限管理的实现方案:分后端方案和前端方案阐述
- 说说各自的优缺点
回答范例
权限管理一般需求是页面权限和按钮权限的管理
具体实现的时候分后端和前端两种方案:
前端方案会把所有路由信息在前端配置,通过路由守卫要求用户登录,用户登录后根据角色过滤出路由表。比如我会配置一个asyncRoutes数组,需要认证的页面在其路由的meta中添加一个roles字段,等获取用户角色之后取两者的交集,若结果不为空则说明可以访问。此过滤过程结束,剩下的路由就是该用户能访问的页面,最后通过router.addRoutes(accessRoutes)方式动态添加路由即可。
后端方案会把所有页面路由信息存在数据库中,用户登录的时候根据其角色查询得到其能访问的所有页面路由信息返回给前端,前端再通过addRoutes动态添加路由信息
按钮权限的控制通常会实现一个指令,例如v-permission,将按钮要求角色通过值传给v-permission指令,在指令的moutned钩子中可以判断当前用户角色和按钮是否存在交集,有则保留按钮,无则移除按钮。
纯前端方案的优点是实现简单,不需要额外权限管理页面,但是维护起来问题比较大,有新的页面和角色需求就要修改前端代码重新打包部署;服务端方案就不存在这个问题,通过专门的角色和权限管理页面,配置页面和按钮权限信息到数据库,应用每次登陆时获取的都是最新的路由信息,可谓一劳永逸!
举一反三:
- 类似Tabs这类组件能不能使用v-permission指令实现按钮权限控制?
<el-tabs>
<el-tab-pane label="⽤户管理" name="first">⽤户管理</el-tab-pane>
<el-tab-pane label="⻆⾊管理" name="third">⻆⾊管理</el-tab-pane>
</el-tabs>
- 服务端返回的路由信息如何添加到路由器中?
// 前端组件名和组件映射表
const map = {
//xx: require('@/views/xx.vue').default // 同步的⽅式
xx: () => import('@/views/xx.vue') // 异步的⽅式
}
// 服务端返回的asyncRoutes
const asyncRoutes = [
{ path: '/xx', component: 'xx',... }
]
// 遍历asyncRoutes,将component替换为map[component]
function mapComponent(asyncRoutes) {
asyncRoutes.forEach(route => {
route.component = map[route.component];
if(route.children) {
route.children.map(child => mapComponent(child))
}
})
}
mapComponent(asyncRoutes)
10.你知道哪些vue3新特性
官网列举的最值得注意的新特性:https://v3-migration.vuejs.org/
- Composition API
- SFC Composition API语法糖
- Teleport传送门
- Fragments片段
- Emits选项
- 自定义渲染器
- SFC CSS变量
- Suspense
以上这些是api相关,另外还有很多框架特性也不能落掉。
回答范例
- api层面Vue3新特性主要包括:Composition API、SFC Composition API语法糖、Teleport传送门、Fragments 片段、Emits选项、自定义渲染器、SFC CSS变量、Suspense
- 另外,Vue3.0在框架层面也有很多亮眼的改进:
更快
虚拟DOM重写
编译器优化:静态提升、patchFlags、block等
基于Proxy的响应式系统
更小:更好的摇树优化
更容易维护:TypeScript + 模块化
更容易扩展
独立的响应化模块
自定义渲染器
11. 说说nextTick的使用和原理?
1、nextTick是等待下一次 DOM 更新刷新的工具方法。
2、Vue有个异步更新策略,意思是如果数据变化,Vue不会立刻更新DOM,而是开启一个队列,把组件更新函数保存在队列中,在同一事件循环中发生的所有数据变更会异步的批量更新。这一策略导致我们对数据的修改不会立刻体现在DOM上,此时如果想要获取更新后的DOM状态,就需要使用nextTick。
3、开发时,有两个场景我们会用到nextTick:
created中想要获取DOM时;
响应式数据变化后获取DOM更新后的状态,比如希望获取列表更新后的高度。
4、nextTick签名如下:function nextTick(callback?: () => void): Promise
所以我们只需要在传入的回调函数中访问最新DOM状态即可,或者我们可以await nextTick()方法返回的Promise之后做这件事。
5、在Vue内部,nextTick之所以能够让我们看到DOM更新后的结果,是因为我们传入的callback会被添加到队列刷新函数(flushSchedulerQueue)的后面,这样等队列内部的更新函数都执行完毕,所有DOM操作也就结束了,callback自然能够获取到最新的DOM值。
12. watch和computed的区别以及选择?
思路分析
- 先看computed, watch两者定义,列举使用上的差异
- 列举使用场景上的差异,如何选择
- 使用细节、注意事项
- vue3变化
computed特点:具有响应式的返回值
const count = ref(1)
const plusOne = computed(() => count.value + 1)
watch特点:侦测变化,执行回调
const state = reactive({ count: 0 })
watch(
() => state.count,
(count, prevCount) => {
/* ... */
}
)
回答范例
-
计算属性可以从组件数据派生出新数据,最常见的使用方式是设置一个函数,返回计算之后的结果,computed和methods的差异是它具备缓存性,如果依赖项不变时不会重新计算。侦听器可以侦测某个响应式数据的变化并执行副作用,常见用法是传递一个函数,执行副作用,watch没有返回值,但可以执行异步操作等复杂逻辑。
-
计算属性常用场景是简化行内模板中的复杂表达式,模板中出现太多逻辑会是模板变得臃肿不易维护。侦听器常用场景是状态变化之后做一些额外的DOM操作或者异步操作。选择采用何用方案时首先看是否需要派生出新值,基本能用计算属性实现的方式首选计算属性。
-
使用过程中有一些细节,比如计算属性也是可以传递对象,成为既可读又可写的计算属性。watch可以传递对象,设置deep、immediate等选项。
-
vue3中watch选项发生了一些变化,例如不再能侦测一个点操作符之外的字符串形式的表达式; reactivity API中新出现了watch、watchEffect可以完全替代目前的watch选项,且功能更加强大。
12.说一下 Vue 子组件和父组件创建和挂载顺序
创建过程自上而下,挂载过程自下而上;即:
parent created
child created
child mounted
parent mounted
之所以会这样是因为Vue创建过程是一个递归过程,先创建父组件,有子组件就会创建子组件,因此创建时先有父组件再有子组件;子组件首次创建时会添加mounted钩子到队列,等到patch结束再执行它们,可见子组件的mounted钩子是先进入到队列中的,因此等到patch结束执行这些钩子时也先执行。
13. 说说从 template 到 render 处理过程
- Vue中有个独特的编译器模块,称为“compiler”,它的主要作用是将用户编写的template编译为js中可执行的render函数。
- 之所以需要这个编译过程是为了便于前端程序员能高效的编写视图模板。相比而言,我们还是更愿意用HTML来编写视图,直观且高效。手写render函数不仅效率底下,而且失去了编译期的优化能力。
- 在Vue中编译器会先对template进行解析,这一步称为parse,结束之后会得到一个JS对象,我们成为抽象语法树AST,然后是对AST进行深加工的转换过程,这一步成为transform,最后将前面得到的AST生成为JS代码,也就是render函数。
算法篇
1. (百度)实现 (5).add(3).minus(2) 功能
例: 5 + 3 - 2,结果为 6
答:
Number.prototype.add = function(n)
{ return this.valueOf() + n;
};Number.prototype.minus = function(n) {
return this.valueOf() - n;
};
2. 给定两个数组,写一个方法来计算它们的交集
例如:给定 nums1 = [1, 2, 2, 1],nums2 = [2, 2],返回 [2, 2]
var nums1 = [1, 2, 2, 1], nums2 = [2, 2, 3, 4];
// 1.
// 有个问题,
[NaN].indexOf(NaN) === -1var newArr1 = nums1.filter(function(item) {
return nums2.indexOf(item) > -1;
});
console.log(newArr1);
// 2.
var newArr2 = nums1.filter((item) => {
return nums2.includes(item);
});
console.log(newArr2);
3. 随机生成一个长度为 10 的整数类型的数组,例如 [2, 10, 3, 4, 5, 11, 10, 11, 20],将其排列成一个新数组,要求新数组形式如下,例如 [[2, 3, 4, 5], [10, 11], [20]]。
function formArray(arr: any[]) {
const sortedArr = Array.from(new Set(arr)).sort((a, b) => a - b);
const map = new Map();
sortedArr.forEach((v) => {
const key = Math.floor(v / 10);
const group = map.get(key) || [];
group.push(v);
map.set(key, group);
}); return [...map.values()];}// 求连续的版本 function
formArray1(arr: any[]) {
const sortedArr = Array.from(new Set(arr)).sort((a, b) => a - b);
return sortedArr.reduce((acc, cur) => {
const lastArr = acc.slice().pop() || [];
const lastVal = lastArr.slice().pop();
if (lastVal!=null && cur-lastVal === 1)
{
lastArr.push(cur);
} else {
acc.push([cur]);
}
return acc;
}, []);}function genNumArray(num: number, base = 100) {
return Array.from({length: num}, () =>
Math.floor(Math.random()*base));
}const arr = genNumArray(10, 20);
//[2, 10, 3, 4, 5, 11, 10, 11, 20];
const res = formArray(arr);console.log(`res
${JSON.stringify(res)}`);
4. 如何把一个字符串的大小写取反(大写变小写小写变大写),例如 ’AbC’ 变成 ‘aBc’ 。
function processString (s) {
var arr = s.split('');
var new_arr = arr.map((item) => {
return item === item.toUpperCase() ? item.toLowerCase() :
item.toUpperCase();
});
Return
new_arr.join('');}console.log(processString('AbC'));function
swapString(str) {
var result = ''
for (var i = 0; i < str.length; i++) {
var c = str[i]
if (c === c.toUpperCase()) {
result += c.toLowerCase()
} else {
result += c.toUpperCase()
}
}
return result}swapString('ADasfads123!@$!@#') // =>'adASFADS123!@$!@#
5. 实现一个字符串匹配算法,从长度为 n 的字符串 S中,查找是否存在字符串 T,T 的长度是 m,若存在返回所在位置。
const find = (S, T) => {
if (S.length < T.length) return -1
for (let i = 0; i < S.length; i++) {
if (S.slice(i, i + T.length) === T) return i
}
return -1
6. 「旋转数组」
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: [1, 2, 3, 4, 5, 6, 7] 和 k = 3 输出: [5, 6, 7, 1, 2, 3, 4] 解释: 向右旋转 1 步:
[7, 1, 2, 3, 4, 5, 6] 向右旋转 2 步: [6, 7, 1, 2, 3, 4, 5] 向右旋转 3 步: [5, 6, 7, 1, 2, 3, 4]
示例 2:
输入: [-1, -100, 3, 99] 和 k = 2 输出: [3, 99, -1, -100] 解释: 向右旋转 1 步: [99, -1, -100, 3] 向右旋转 2 步: [3, 99, -1, -100]
function rotate(arr, k) {
const len = arr.length const step = k % len return
arr.slice(-step).concat(arr.slice(0, len - step))}// rotate([1, 2, 3, 4,
5, 6], 7) => [6, 1, 2, 3, 4, 5]
7. 打印出 1 - 10000 之间的所有对称数
[...Array(10000).keys()].filter((x) => {
return x.toString().length > 1 && x ===
Number(x.toString().split('').reverse().join(''))
})
8. 「两数之和」
给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。
示例:
给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9 所以返
回 [0, 1]
function anwser (arr, target) {
let map = {} for (let i = 0; i < arr.length; i++) {
map[arr[i]] = i }
for (let i = 0; i < arr.length; i++) {
var d = target - arr[i]
if (map[d]) {
return [i, map[d]]
}
}
return new Error('404 not found')}
9 给定两个大小为 m 和 n 的有序数组 nums1 和nums2。请找出这两个有序数组的中位数。要求算法的时间复杂度为 O(log(m+n))。
示例 1:
nums1 = [1, 3] nums2 = [2]
中位数是 2.0
示例 2:
nums1 = [1, 2] nums2 = [3, 4]
中位数是(2 + 3) / 2 = 2.5
const findMedianSortedArrays = function(
nums1: number[],
nums2: number[]
) {
const lenN1 = nums1.length;
const lenN2 = nums2.length;
const median = Math.ceil((lenN1 + lenN2 + 1) / 2);
const isOddLen = (lenN1 + lenN2) % 2 === 0;
const result = new Array<number>(median);
let i = 0; // pointer for nums1
let j = 0; // pointer for nums2
for (let k = 0; k < median; k++) {
if (i < lenN1 && j < lenN2) {
// tslint:disable-next-line:prefer-conditional-expression
if (nums1[i] < nums2[j]) {
result[i + j] = nums1[i++];
} else {
result[i + j] = nums2[j++];
}
} else if (i < lenN1) {
result[i + j] = nums1[i++];
} else if (j < lenN2) {
result[i + j] = nums2[j++];
}
}
if (isOddLen) {
return (result[median - 1] + result[median - 2]) / 2;
} else {
return result[median - 1];
}
};
进阶篇
1. 强缓存、协商缓存与cdn缓存的区别
强缓存(HTTP Cache-Control)
- 强缓存是浏览器缓存中的一种策略,它依赖于HTTP响应头中的Cache-Control字段,如max-age。
- 当设置了强缓存后,浏览器在缓存有效期内不会向服务器发送请求,直接使用本地缓存的数据。
- 强缓存适用于不经常变动的资源,比如CSS、JavaScript文件和图片等。
- 强缓存可以减少HTTP请求的数量,从而降低服务器的负载和网络延迟。
协商缓存(HTTP ETag/Last-Modified)
- 协商缓存依赖于HTTP的ETag或Last-Modified响应头。
- 当资源被缓存后,浏览器在下次请求相同资源时会发送If-None-Match或If-Modified-Since请求头,携带上次响应的ETag或Last-Modified值。
- 服务器根据这些值判断资源是否有更新,如果没有更新,服务器返回304状态码,告诉浏览器使用本地缓存的资源。
- 协商缓存适用于可能会更新的资源,它允许服务器控制资源的更新,确保用户总是获取到最新的内容。
CDN缓存
- CDN(内容分发网络)缓存是一种分布式缓存机制,它将内容缓存在离用户地理位置更近的服务器上。
- CDN缓存可以减少数据传输的延迟,提高访问速度,尤其适用于静态资源。
- CDN通常会根据TTL(Time to Live)策略来决定资源在CDN节点上的缓存时间。
- 当资源在CDN上缓存后,用户的请求首先到达CDN节点,如果资源在CDN上可用,就直接从CDN节点提供服务,否则CDN会从源服务器获取资源并缓存。
关注获取完整资料,也可以进群获取最新资讯



















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









