






 文章讲述了从图片PDF中无法直接选中文字的问题,介绍了OCR技术的作用以及推荐的PDF-xchange和万兴PDF软件进行文字识别和转换的方法,强调了转换后文档质量的重要性。
文章讲述了从图片PDF中无法直接选中文字的问题,介绍了OCR技术的作用以及推荐的PDF-xchange和万兴PDF软件进行文字识别和转换的方法,强调了转换后文档质量的重要性。
问题分析:
假设我打开的一篇pdf文献是由图片转换而来的,请问最终的pdf是否能够选中其中的文字???
答案是否定的。
结论:从图片制作而成的pdf无法选中其中的文字。
解决方法:
OCR(Optical Character Recognition)- 光学字符识别
OCR其实应该是每个人都知道的技术术语,但现实中却有很多人没有接触也并不了解。以下是百度百科的相关解释,我们很容易通俗的理解,比如一本书通过扫描仪扫描成了pdf格式的书籍,但是上面的一页一页都是图片,无法选中文字,那么通过OCR技术就可以把一页一页转变成可以选中的文字状态。
OCR是一种技术的名称,我们要实际使用的时候,需要使用OCR软件对这类PDF进行识别转换,OCR软件不是某个软件的名称,而是某类软件的名称。就类似于说“办公软件”不是某个软件叫“办公软件”,而是某类软件比如office、wps等归类为办公软件。
推荐使用的OCR软件
在我了解的软件中,比较推荐PDF-xchange和万兴PDF。
PDF-xchange是一款加拿大的软件,有中文界面。对英文文档识别速度和准确率很高。对中文文档识别率稍微欠缺。
万兴PDF专业版是国产软件。但是其OCR准确率非常了得。中文和英文都非常不错。
如果你最经常查看阅读的是英文文献,那么我非常建议你安装PDF-xchange 9.2版。因为它OCR转换的速度真的非常非常快。而且转换质量也很棒。不建议9.3版本,因为9.3版本完全以提高转换速度为目的,有些文档转换质量不如9.2版本。
OCR转换方法非常easy
ocr识别的方法只需要看下面这张图即可。使用PDF x-change打开要转换的PDF,然后凡是框选的按照我的设置,凡是没有框选的保持默认。尤其要注意去掉“忽略页面中存在的文本”的勾选。另外,看下图,我非常建议勾选最下面的“创建新文档”,也就是转换后生成新的PDF,以免保存的时候破坏替换旧的文档。
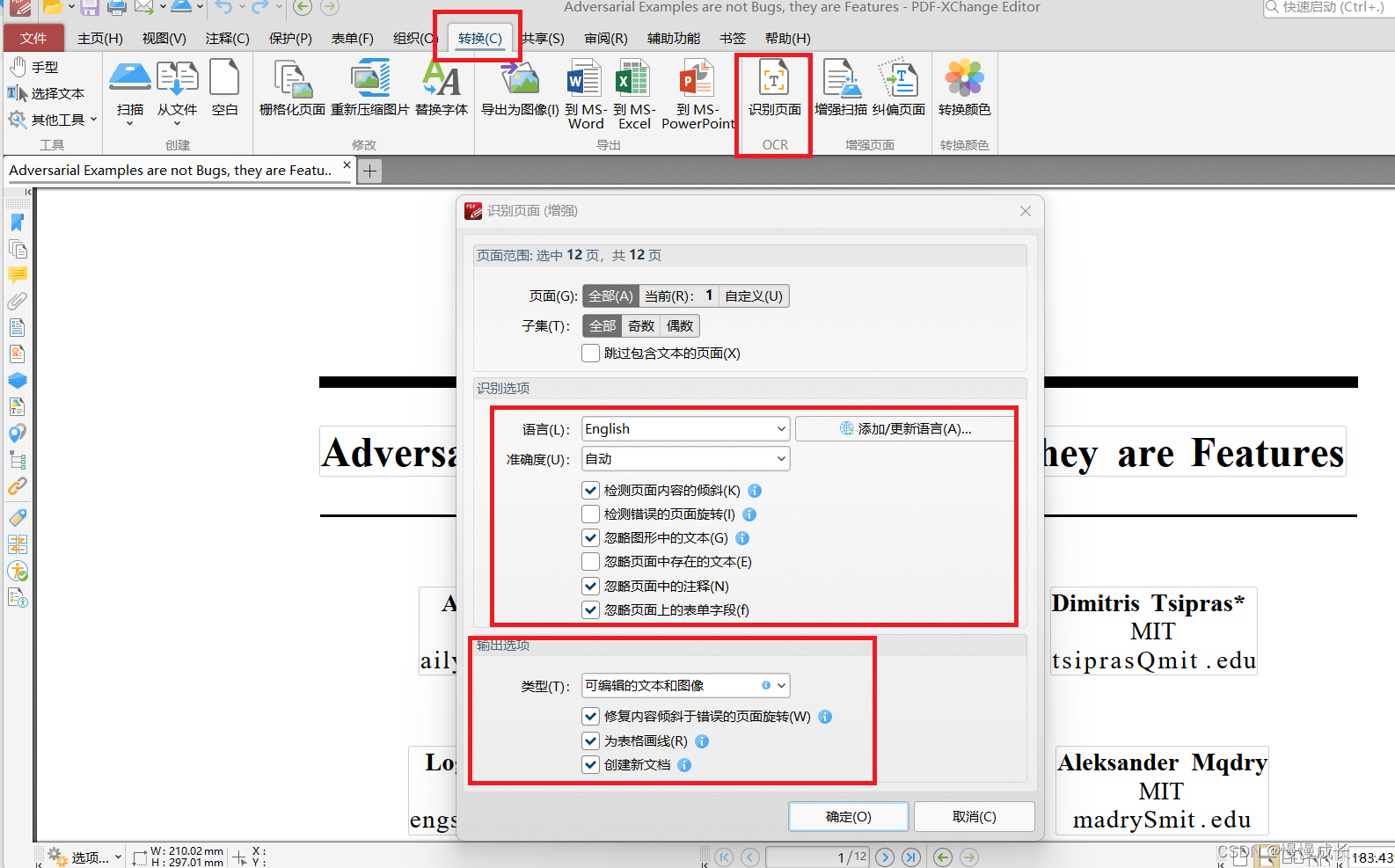
这款软件的转换速度真的非常快,而且准确度在现有的OCR软件里面是相对较好的。
转换好之后将转换好的PDF保存一下。
然后再用知云打开转换好的PDF文件就可以正常选中文字。
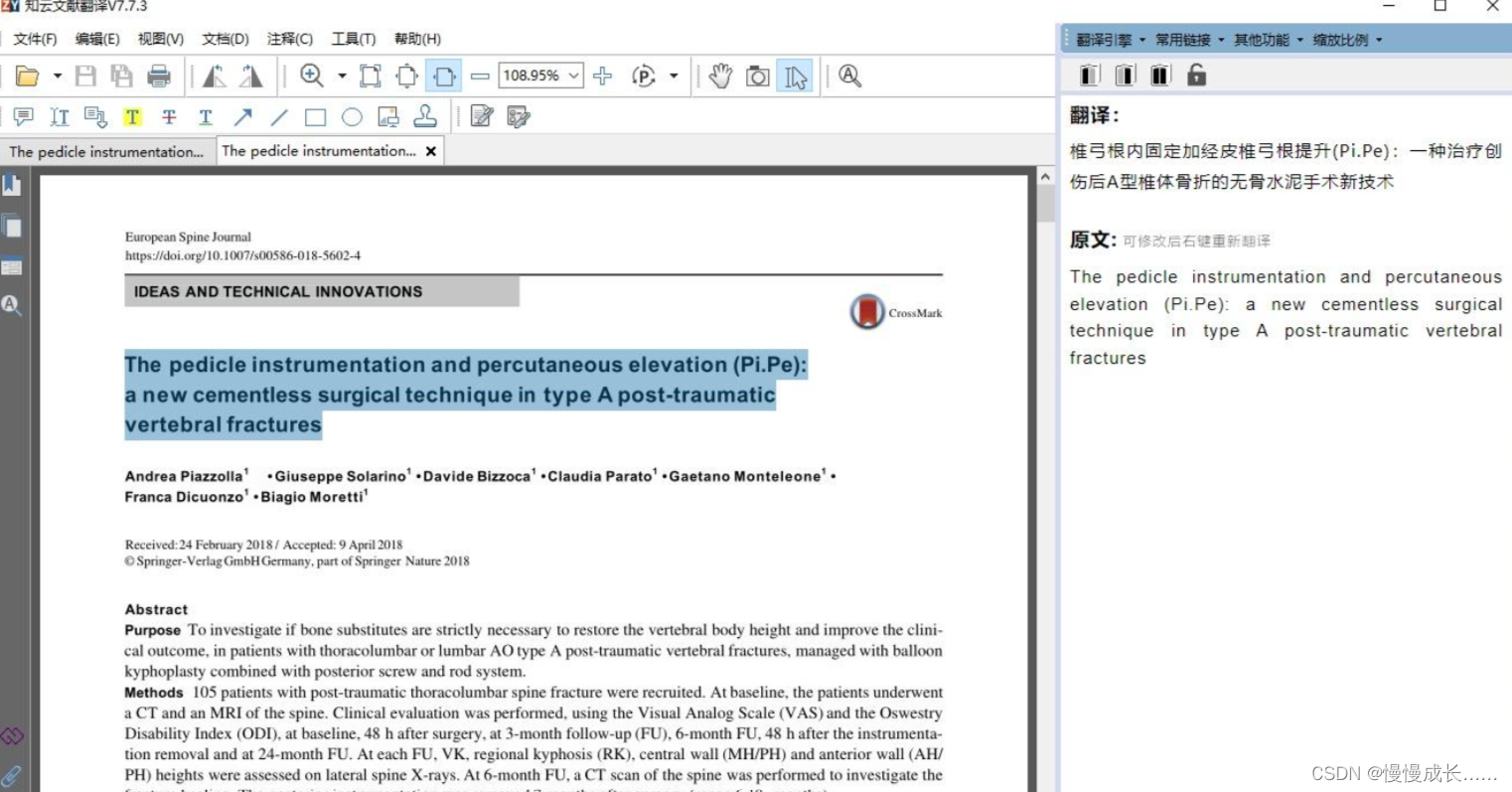
ocr方法不只是解决无法选中文字的问题,还可以解决很多其他问题,比如选中的文字原文乱码、奇特的中文字符、无法正确选择文字区域等问题,都可以通过OCR转换来解决的。

















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









