






欢迎关注微信公众号:互联网全栈架构
MySQL执行计划(EXPLAIN)可以提供SQL运行的一些信息,相当于模拟SQL的执行,从而让我们可以对SQL语句做更深入的分析和了解。在实际开发过程中,我们经常会使用执行计划来分析和提升SQL的执行效率。
EXPLAIN的使用也非常简单,在现有的SQL语句前面加上关键字EXPLAIN,然后直接执行即可。
创作不易,如果文章对你有帮助,请在文末点个在看,非常感谢!
一、准备工作
关于MySQL执行计划的介绍,很多文章都是干巴巴地把知识点罗列出来,然后做一下解释,这种形式很难让人印象深刻,所以我们还是结合具体的例子进行讲解,这样就直观得多。
还是先创建两张表,一张是订单表,一张是客户表,订单表中的字段customer_id与客户表的主键关联。数据表创建完成后,再往表里插入简单的测试数据:
先是订单表:
CREATE TABLE `t_order` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`order_no` int(11) DEFAULT NULL COMMENT '订单号',
`customer_id` int(11) DEFAULT NULL COMMENT '客户id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入数据
INSERT INTO `t_order` VALUES ('1', '1001', '1');
INSERT INTO `t_order` VALUES ('2', '1002', '26');然后是客户表:
CREATE TABLE `t_customer` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`customer_name` varchar(255) DEFAULT NULL COMMENT '客户姓名 ',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入数据
INSERT INTO `t_customer` VALUES ('1', 'John');
INSERT INTO `t_customer` VALUES ('2', 'Tom');二、执行计划初窥
执行下面的SQL,看看是什么结果:
EXPLAIN SELECT * FROM t_order
可以看出,这个EXPLAIN返回了很多列,每个列的含义如下:
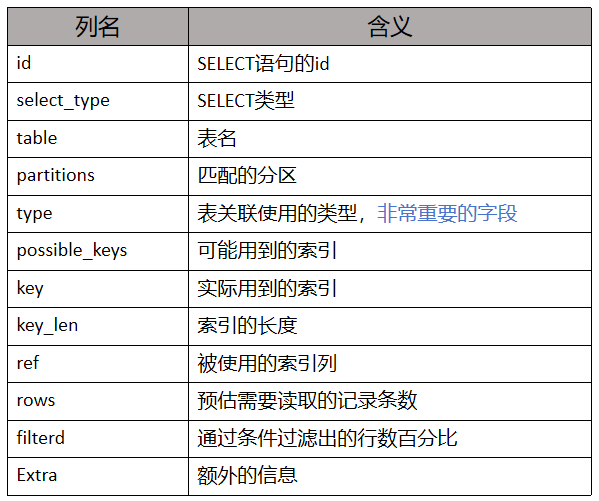
三、执行计划详解
对于执行计划中的每个列,我们分别进行讲解:
1. id:
表示SELECT语句执行的顺序,id相同时,从上到下的顺序执行,id值越大,优先级越高,就越先执行,如果是子查询,id的值会递增。比如我们执行下面的SQL后,子查询的id为2,它会先执行:
EXPLAIN SELECT (SELECT customer_id FROM t_order WHERE id = 1) FROM t_order der;
2. select_type:
表示查询的类型,比如普通查询、联合查询、子查询等,常用的值有如下这些:
SIMPLE:没有子查询或者UNION
PRIMARY:包含复杂子查询的最外层SELECT
UNION:对于包含UNION或者UNION ALL的复杂查询来说,最左边的为PRIMARY,其余查询的select_type为UNION
UNION RESULT:UNION会进行去重(UNION ALL则不会),这样就会有临时表,而针对该临时表的查询select_type就是UNION RESULT
比如下面的SQL,可以说明UNION的情况:
EXPLAIN SELECT * FROM t_order WHERE id = 1
UNION SELECT * FROM t_order WHERE id = 2;
其它常见的select_type还有SUBQUERY和DERIVED。
3. table:
查询的表名,可能是真实的表名或者别名,也可能是以几种情况:
<unionM,N>:union查询产生的结果,M、N分别掼执行计划id值。比如上一节的例子里面就是这种情况
<derivedN>:N为派生表的id值。派生表可能来源于FROM语句中的子查询
<subqueryN>:N为物化子查询结果的id值
4. partitions:
如果是分区表的话,表示查询匹配行所在的分区,否则为NULL值
5. type:
表示数据表关联的类型,常见的一些类型如下,按性能从高到低排列:
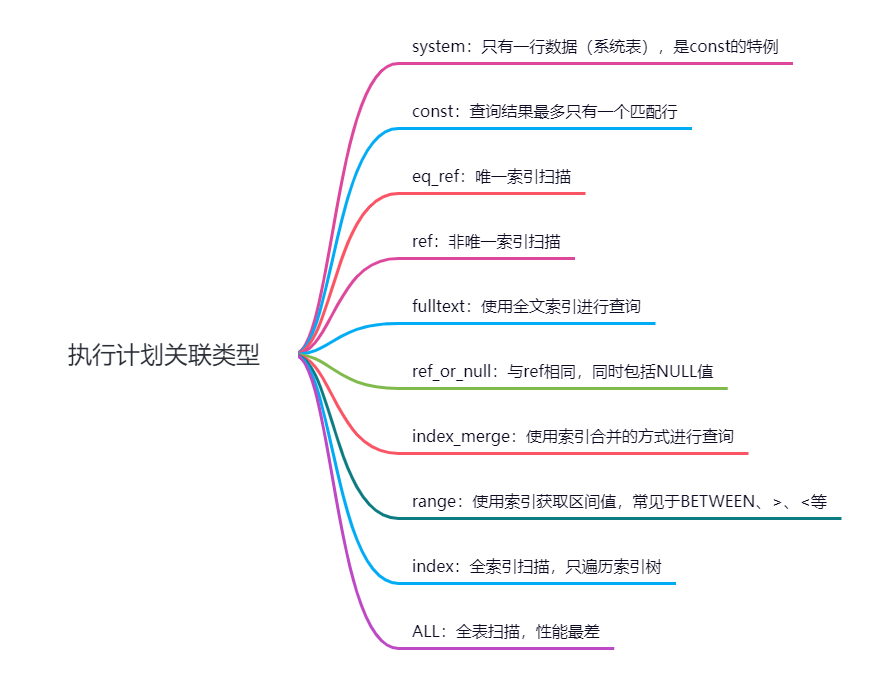
6. possible_keys和key:
possible_keys表示可能会用到的索引,当然,在实际查询的时候也可能不会走索引,它主要用于优化查询的性能:如果它的值为NULL,那么就说明没有走索引。而key表示实际用到的索引,它也不一定都来自于possible_keys中的值,MySQL的优化器会找到它认为最优的选择。
比如我们给表t_order的字段customer_id加一个索引:
ALTER TABLE `t_order`
ADD INDEX `idx_customer` (`customer_id`) USING BTREE ;然后我们按照客户id查询:

可以看到SQL可能用到,以及实际用到的索引。
7. key_len:
索引使用的字节数,越短越好。
8. ref:
表示索引的哪一列被使用了,有可能是常数。
9. rows:
为了执行查询,MySQL需要搜索的行数,它是一个预估值。
10. filtered:
表示满足条件的行数占预估行数rows的百分比,最大值是100。
11. extra:
查询的额外信息,比较常见的有:
Using index:使用了覆盖索引
Using Temporary:使用了临时表保存中间结果
Using filesort:使用外部排序而不是索引排序
其它的额外信息,请参见MySQL官网。
鸣谢:
https://dev.mysql.com/doc/refman/5.7/en/
https://www.sitepoint.com/using-explain-to-write-better-mysql-queries/
推荐阅读:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









