







文章目录
MySQL
默认跳过了安装步骤
一、配置文件以及服务启动关闭
1. 配置文件
my.ini:一般位于 C:\ProgramData\MySQL\MySQL Server 8.0 路径之下
该目录与安装 MySQL 目录有很大关系
2. Mysql 服务的启动
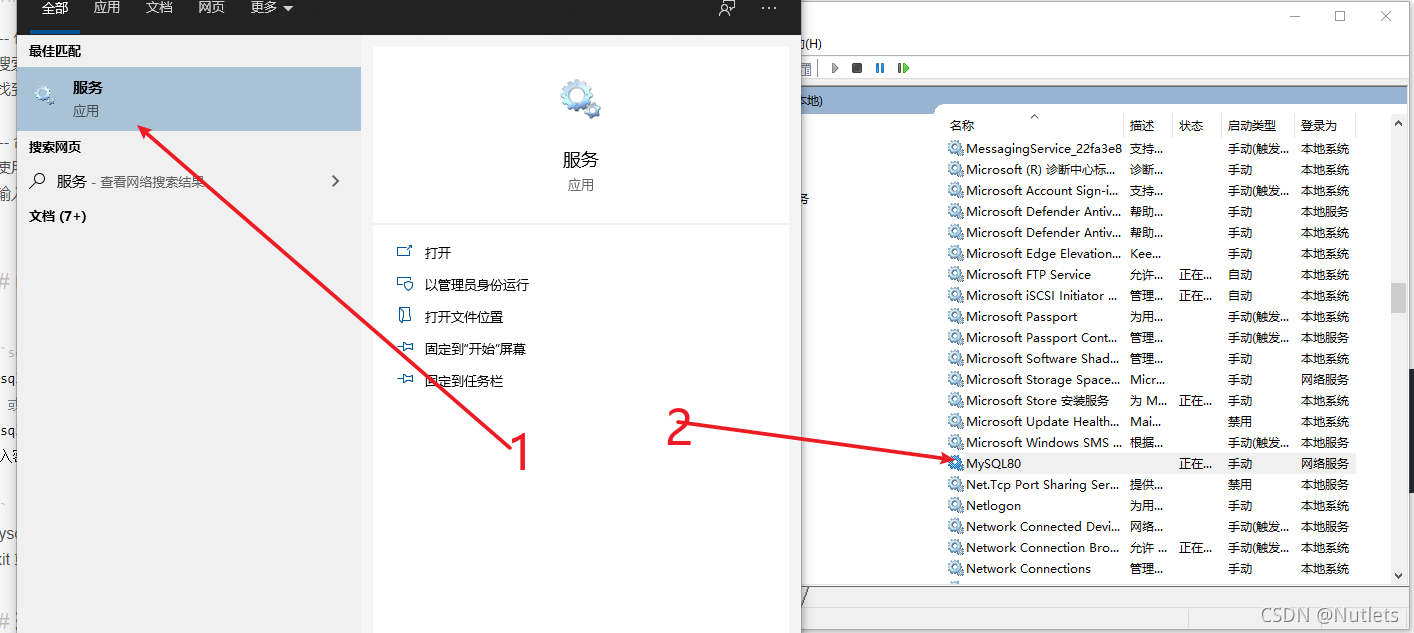
1 – 使用 Windows 服务进行打开
- 搜索 “服务”
- 找到 MySQL 服务名,启动即可(一般在安装时已经设置了开机自启动)
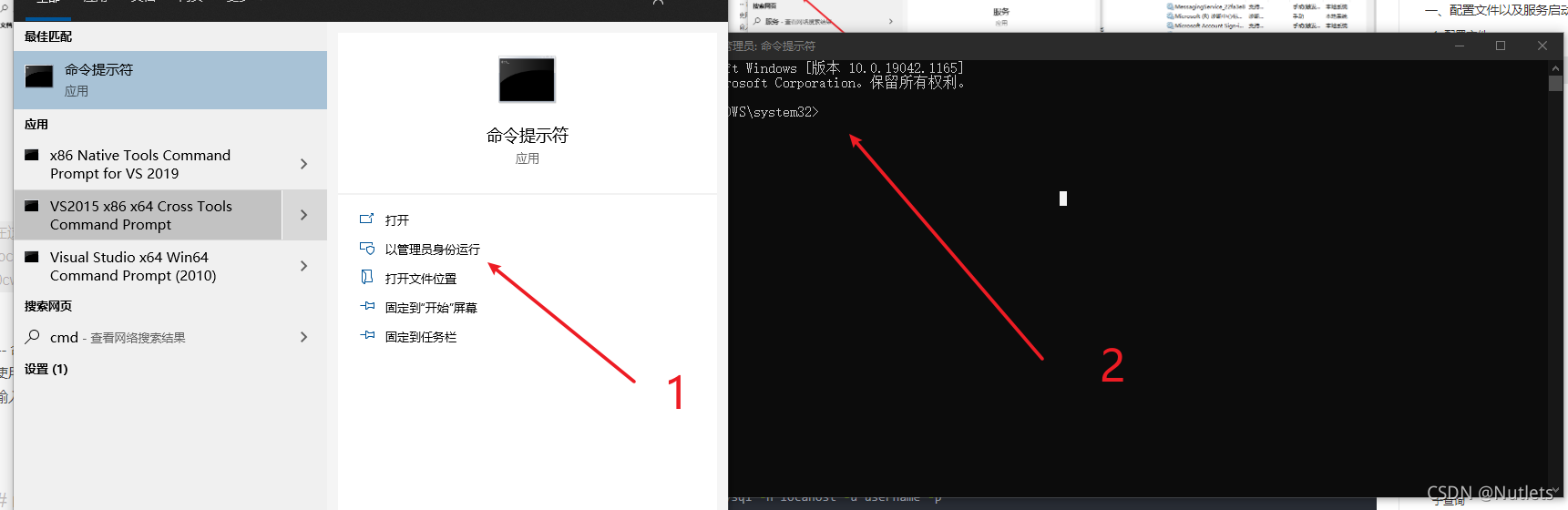
2 – 命令行方式打开
- 使用 管理员 权限打开 cmd
- 输入 net stop/start MySQL80(这里的服务名可大小写,但应与 MySQL 服务名一致)
3. MySQL 环境变量配置
计算机 => 属性 => 高级系统设置 => 环境变量 => Path =>新增 MySQL 安装目录
即可;
4. mysql 服务的登录退出
1 – 命令行(cmd)使用以下方法进行登入:
mysql[-h localhost -P portnum] -u username -p+密码
-- 或者如下
mysql -h locahost -u username -p
输入密码
2 – 使用 mysql command line 登录

输入密码即可,默认是本地连接,输入exit 退出,或者 Ctrl + C 两次进行退出;
二、 SQL 初见
1. 常用的 SQL 语句
-- 查看安装的 MYSQL 版本
SELECT VERSION(); # CMD 下使用 `MYSQL -V` 查看
-- 查看用户权限下的所能查看的数据库
SHOW DATABASES;
-- 打开数据库,使用数据库
USE DATABASENAME;
-- 查看库表
SHOW TABLES [FROM DATABASESNAME];
-- 查看当前使用库
SELECT DATABASE();
-- 建立表
CREATE TABLE TABLENAME (
ID INT,
NAME VARCHAR(20)
);
-- 查看表信息
DESC TABLENAME;
-- 简单的单表查询
SELECT * FROM [DATABASENAME.]TABLENAME;
-- 插入数据
INSERT INTO TABLENAME(ATTRIBUTE1,[ATTRIBUTE2,..]) VALUE(VALUE1,[VALUE2,...]),(VALUE1,[VALUE2,...])...;
-- 更新数据
UPDATE 表名 SET 列名1=值1,... WHERE 筛选条件;
2. SQL 语句简单规范
- 不区分大小,建议关键字大写,表名、列名小写(命令规范与 Java 中的变量命名类似)
- 每条命令最好使用
;结尾,表示一条语句,或者一个执行过程,函数等 - SQL 语句为提高可读性,应该根据关键字进行换行
- SQL 中的注释
- # 注释内容
- / * 注释内容 * /
- – 注释内容
3. SQL 开发软件
- Workben:MySQL 自带的,MySQL 完全安装时带有该开发软件 ,免费
- Navicat:第三方开发的数据库开发软件,非常方便,提供试用,后期收费
- SQLyog:似乎收费
- DataGrip:JetBrains 旗下的数据库开发软件,社区版免费,超级版收费
- 其他
三、SQL 知识 语言分类
01. DQL:Data Query Language 查询语句
SELECT 查询列表 [as] [别名]
FROM 表1 [as] [别名]
[[INNER|LEFT|RIGHT] JOIN 表2 [as] 别名
ON 连接条件]
[WHERE 筛选条件]
[GROUP BY 分组条件]
[HAVING 查询后筛选条件]
[ORDER BY [查询后的排序字段] [ASC|DESC]]
[LIMIT 开始索索引, 截取长度]
[UNION [ALL] 其他类似查询];
02. DML:Data Manipulattion Language 数据操作语句
-- 数据更新语句
UPDATE 表名1 [as] 别名1 [表名2 [as] 别名2]
SET 别名1.列明 = 新值1,[...,别名2.列名=新值2,...]
WHERE [连接条件 AND] 筛选条件;
-- 数据插入
INSERT INTO 表名[(列名1,列名2,...)] VALUES(值1,值2,...)[,(值1,值2,...)];
INSERT INTO 表名[(列名1,列名2,...)]
SELECT(字段名1,字段名2,...)
[
UNION [ALL]
SELECT(字段名1,字段名2,...)
UNION [ALL]
....
]
;
INSERT INTO 表名1 SET 列名1=值1, 列名2=值2,...;
-- 数据删除
DELETE FROM 表名1[,表名2]
[[INNER|LEFT|RIGHT] JOIN 表名2 ON 连接条件]
WHERE 筛选条件; -- 支持回滚,删除满足条件的行
TRUNCATE [TABLE] 表名; --删除表中所有的数据(可以删除前提),不可以回滚
03. DDL: Data Define Language 数据定义语言
-- 数据库操作
CREATE DATABASE|SCHEMA [IF NOT EXISTS]数据库名; -- 创建数据库
DROP DATABASE|SCHEMA [IF EXISTS] 数据库名; -- 删除数据库
ALTER DATABASE|SCHEMA 数据库名 CHARACTER SET 字符集; --修改字符集(默认是UTF-8,也可以创建数据库)
-- 表的操作
-- 表的创建
CREATE TABLE [IF NOT EXISTS] 表名 (
列名 类型[(长度)] [列级约束:NOT NULL| DEFAULT |PRIMARY KEY| FOREIGN KEY REFERENCES 主表(KEY)| CHECK | UNIQUE],
...
[CONSTRAINT 约束名] 约束类型,
...
);
-- 表的修改 CHANGE MODIFY ADD DROP RENAME
ALTER TABLE TABLENAME CHANGE [COLUMN] 旧列名 新列名 类型 [约束]; -- 修改列的类型和约束
ALTER TABLE TABLENAME MODIFY [COLUMN] 新类型 [约束]; -- 修改列的类型和约束
ALTER TABLE TABLENAME ADD COLUMN 列名 类型 [约束] [FIRST|AFTER]; -- 添加删除列
ALTER TABLE 表名 DROP COLUMN 列名; -- 删除列
ALTER TABLE 表名 RENAME TO 新表名; --修改表名
-- 表的删除
DROP TABLE [IF EXISTS 表名];
-- 表的复制
CREATE TABLE 复制表名 LIKE 表名; --仅仅复制结构,没有数据
CREATE TABLE 复制表名 [AS] SELECT 列名1,列名2... FROM 表名 WHERE 筛选条件; -- 根据查询结果创建表
04. TCL:Transaction Control Language 事务控制语言
1. SQL 语句
-- 事务
-- 步骤1:开启事务
SET AUTOCOMMIT = 0; -- 默认是开启自动提交
START TRANSACTION; -- 可选
-- 步骤2:编写事务中 SQL 语句(SELECT INSERT UPDATE DELETE)
BEGIN
语句1,
SAVEPOINT 回滚点名称 -- 记录回滚点
语句2,
ROLLBACK TO 回滚点名称 -- 回滚到指定回滚点
...
END
-- 步骤3:提交事务
COMMIT; -- 提交事务
ROLLBACK; -- 回滚事务
2. 知识
事务:一个或一组 sql 语句组成的一个执行单元,这个执行单元要么全部执行要么全部不执行
案例:转账
存储引擎:数据用各种不同的技术存储在文件中(或内存)中(MySQL 默认引擎是 InnoDb 支持事务)
事务的 ACID 属性
- A(Atomicity):原子性,一个事物是一个不可分割的工作单位,事务中的操作要么发生,要么都不发生
- C(Consistency):一致性,事务必须使数据库从一个以执行状态变换到另一个以执行状态
- I(Isolation):事务的隔离性是指一个事物的执行不能别去其他十五干扰,即一个事物内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能相互干扰
- D(Durability):持久性,是指一个事务一旦被提交,他对数据库中的数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响
事务的创建:
-
隐式的事务:事务没有明显的开启和结束的标记
INSERT UPDATE DELETE语句(隐式的自动提交) -
显式事务:事务具有明显的开启和结束的标记
前提:必须先设置自动提交功能为禁用
存在两个事务 T1 T2,并发的情况下,事务提交会出现的以下情况:
- 脏读:事务 T1 读取了 T2 更新但还没有被提交的字段,之后,T2 回滚,T1 读取的内容就是临时且无效的
- 不可重复读:对于两个事务T1 T2 T1 读取了一个字段,然后 T2 更新了该字段之后,T1 再次读取同一个字段,值就不相同了
- 幻读:对于俩各个事务 T1 T2, T1 从一个表中读取了一些记录,然后 T2 在该表中插入了一些新的记录,之后,如果 T1 再次读取同一个表,就会多出几条记录
数据库中提供了四种事务隔离级别:
- read uncommitted(读未提交数据):允许事务读取违背其他事务提交的变更,脏读、不可重复读、幻读的问题都会出现
- read committed(读已提交数据): 只允许事务读取已经被其他事务提交的变更,可以避免脏读,但不可重复读、幻读问题仍然可能出现
- repeatable read(可重复读):确保事务可以多次从一个字段中读取相同的值,在这个事务持续期间,禁止其他事务对这个字段进行更新,可以避免脏读和不可重复读,但幻读的问题依然存在
- serializable (串行化):确保事务可以从一个表中读取相同的行,在这个事务持续期间,禁止其他事务对该表执行插入、更新和删除操作,所有并发问题都可以避免,但性能十分低下;
oracle:支持两种事务隔离级别:read committed serializable; 默认read committed
mysql 支持四种:默认repeated read
-- 查看隔离级别
SELECT @@TRANSACTION_ISOLATION; --8.0版本为此变量
-- 设置隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED ;
四、其他
01. 视图
02. 库函数
功能:将一组逻辑语句封装在方法体中,对外暴露方法名
优点:
1. 隐藏了实现细节
2. 提高代码的重用性
调用: select methodName([实参列表]) [from tablename];
特点:
① 叫什么(函数名)
② 干什么(函数功能)
分类:
1.单行函数
concat length ifull 等
2.分组函数
功能:做统计使用,多个形参,单个返回值,又称统计函数、聚合函数、组函数
- 常见函数(方法)
- 字符函数
LENGTH(字符串) -- 获取参数值的字节长度(英文字符一个字节,一个汉字在 utf8 中占用三个字节) CONCAT(字符串1,字符串2) -- 拼接字符串, UPPER(str) -- 改为大写 LOWER(str) -- 改为小写 -- SQL 中的索引从 1 开始 SUBSTR(str,begin) --从 begin 开始截取到字符串末尾的子串 SUBSTR(str,begin,length) -- 从 begin 开始截取 length 长度的子串 INSTR(str, substr) -- 返回子串在str中第一次出现的索引 TRIM([substr from] str) -- 去掉子串前后指定串,默认是空格 LPAD(substr,length,str) -- 左填充,保留length个长度 RPAD(substr,length,str) -- 右填充 REPALCE(str,oldstr,newstr):替换所有的子串为新子串 - .数学函数
ROUND(num) -- 四舍五入,绝对值四舍五入加符号 ROUND(num,D) -- D 保留多少位 CEIL(num) -- 向上取整,大于等于 num 的最小整数 FLOOR(num) -- 向下取整, <= TRUNCATE(num,D) -- 截断, 小数后保留 D 位 MOD(num1,num2) -- num1 % num2 RAND() -- 0-1 左闭右开的小数 - 日期函数
NOW() -- 返回系统日期+ 时间 CURDATE() -- 返回当前系统日期,不包含时间 CURTIME() -- 返回当前系统时间 YEAR() -- 年 MONTH() -- 月 MONTHNAME() -- 英文月名 STR_TO_DATE(str,model) -- 字符串转日期 DATE_FORMAT(str,model) -- 日期转字符串 /* Y 四位年份 y 两位年份 m 两位月份 c 不带0的月份 d 日 H 24小时制 h 12小时 i 分钟 s 秒 */
- 其他函数
VERSION(); -- 版本号 DATABASE() -- 数据库 USER() -- 用户 PASSWORD(STR) -- 加密字符串 MD5(STR) -- 同上 - 流程控制函数
IF 函数,IF(EXP1,EXP2,EXP3) EXP1条件成立,返回EXP2,不成立返回 EXP3 -- CASE CASE(EXP1) WHEN EXP2 THEN EXP3 [WHEN EXP2 THEN EXP3] ... ELSE 要显示的值或者语句 END -- IF ELSE IF EXP1 THEN EXP2 ELSEIF EXP3 THEN EXP4 ... END IF; - 分组函数
SUM() -- 求和 SVG() -- 平均值 MAX() -- 最大值 MIN() -- 最小值 COUNT() -- 计算个数 /* 1. NULL 是否参与运算,以上分组函数都忽略 NULL 值 否:SUM COUNT AVG MAX MIN COUNT 2. 可以和 DISTINCT 搭配 SUM(DISTINCT KEYWORD) 3. COUNT 函数详细介绍 COUNT(*) 可以计算 NULL 值,一般用来计算行数 COUNT(1) 可以计算行数(类似多加1列进行计算) MYISAM 存储引擎下,COUNT(*)效率高 INNODB 存储引擎下,COUNT(*) 和 COUNT(1) 效率差不多,COUNT(\*) 效率要低一些 COUNT(1)>COUNT('字段') */
五、 查询
连接查询分类
-
sql92 标准:仅仅支持内连接
也支持一部分外接(oracle sqlserver支持,mysql 不支持) -
sql99 标准: 支持内连接 + 外链接(左外 右外) + 交叉连接
功能分类
- 内连接
- 等值连接
- 非等值连接
- 自连接
- 外连接
- 左外连接
- 右外连接
- 全外连接
- 交叉连接
连接带来的问题:列名重复,需要对查询列名进行限定
多表查询的适用条件单表查询相同,支持条件限定,内容筛选
子查询
出现在其他语句中的 select 语句,称为子查询或内查询
外部的查询语句称为主查询或外查询
分类:按子查询出现的位置
select 后面
标量子查询
from 后面
支持表子查询
where 或 having 后面
标量子查询
列子查询
行子查询
exists 后面(相关子查询)
表子查询
按结果集的行列数不同:
标量子查询、单行子查询,结果集只有一行一列
列子查询,查询结果只有一列多行
行子查询:结果集一行多列
表子查询:结果集一般为多行多列
语法规则:
特点:
1. 子查询放在小括号内
2. 子查询一般放在条件的右侧
3. 一般搭配着单行操作符使用
> < >= <= = <>
- 列子查询,一般搭配着多行操作符号使用
in any/some all
in/not in 等于列表中的某个值
any/some 和子查询返回值中某一个值进行比较
all 和子查询返回的所有值进行比较
行子查询:(查询结果集合是一行多列)
eg:查询员工编号最小并且工资最高的员工信息
select * from employees
where (employee_id, salary)=(
select min(employe),max(salary)
from employee
);
select 后面的子查询
查询之后再查询
from 后面的子查询,将查询的结果视为一个表进行查询
对于查询的结果,进行操作时需要取别名
exsits 后方的子查询(相关子查询)
语法:exsits(完整的查询语句)
结果:1 或 0
先执行外查询,然后再查 exsits 后方的子查询
in 语句之后都行
内连接: inner join(自然连接)
表的顺序部分主次
内连接的结果 = 多表的交集
n 表连接需要 n - 1 个连接条件
等值 非等值 自连接
外连接:左外右外全外
left|right|full
查询结果 = 主表中的所有行,其中表和它匹配的将显示匹配行,从表没有匹配的则显示null
left join 左边是主表,right join 右边是主表
full join 两边都是主表
一般用于查询除了交集部分不匹配的内容
交叉连接:(笛卡尔乘积)
select 查询列表
from 表一 别名
cross join 表二 别名
联合查询
将多条查询语句的结果合并成一个结果(查询的结果结构类似,列数应该相同)
语法:
查询语句1
union all
查询语句2
……
应用场景:要查询的结果来自于多个表,且多个表的不具有连接关系,查需结果类似,信息一致
显示的结果以查询语句1的结构进行显示,
- 要求多条查询语句的查询列数是一致的
- 要求多条查询语句的查询的每一列的类型和顺序最好一直
- union 关键字默认去重,如果使用 union all 可以包含两个查询结果集合的重复项
六、 标准
SQL 92 标准
-
等值连接
- 连接条件位多表交集部分
- n 表连接,条件为 n - 1 个连接条件
- 连接没有顺序
- 一般需要起别名或者限定查询的列名
- 可搭配单表查询的限定条件
-
非等值连接
-
自连接:同名的表的连接,连接条件的关键字是在表中存在,表许需要进行命名别名
SQL 99 标准
SELECT COLNAME
FROM TABLENAME NEWTABLE1NAME [连接类型]
JOIN TABLE2NAME ON 连接条件
[WHERE 筛选条件]
[GROUP BY 分组条件]
[HAVING 筛选条件]
[ORDER BY 排序列表]
/*
on 关键字提高分离性,便于阅读
功能分类
- 内连接 : inner
inner 可以省略,默认连接是等值连接
- 等值连接
- 非等值连接
- 自连接
- 外连接
1. 外链接查询的结果为主表中的左右记录
如果表中有匹配的,则显示匹配值
没有匹配值,为 null
外连接查询结果= 内连接查询结果 + 主表中有而从表中没有的记录
- 左外连接 :left [outer]
左侧连接是主表
- 右外连接 :right [outer]
右侧连接是主表
左右外链接交换表的顺序可以达到同样的效果
- 全外连接 :full [outer]
MySql支持,主表和从表的交集
全外连接 = 内连接的结果 + 表一中有但表二中没有的
- 交叉连接 [cross]:笛卡尔乘积
*/
SQL 92 SQL 99
功能:SQL 99支持较多
可读性:SQL 99 将连接条件适用 on 关键字进行标识
七、MySQL 中的数据类型
数据类型选择:
- 所选择的类型越简单越好
- 能保存数据的数值类型越小越好
| 类型 | 名称 | 长度(字节) | 备注 |
|---|---|---|---|
| 整型 | TinyInt | 1 | 有符号:-128~127 无符号 0 ~ 255 |
| SmallInt | 2 | sign: -32768~32767 unsigned:0~65535 | |
| MediumInt | 3 | sign: -8388606~883688607 unsign:0~1672215 | |
| Int/Integer | 4 | sign: - 2147483648~2147483647 unsign:0~4294967295 | |
| BigInt | 8 | sign:-9223372036854775808~-9223372036854775807 unsign:0 ~ -9223372036854775807 * 2 + 1 | |
| (可以设置长度,不设置长度,默认长度int 11,无符号是 10,表示的是显示长度。如不足补零,搭配 erofill 使用,默认变成无符号) | |||
| 浮点数 | float(M,D) | 4 | M: 整数 + 小数 总个数 |
| double(M,D) | 8 | ||
| 定点数 | dec(M,D) | M + 2 | {M: 整数和小数的个数之和 <= M 定点默认值是10,float double 应情况而变,无默认值 D: 小数点后的个数 <= D 定点默认值是 0} |
| decomal(M,D) | M + 2 | 最大值取值范围同double | |
| 字符型 | char | 最多的字符数 M(默认为1) | 固定长度的字符(占用内存的字符)效率高 |
| varchar | 最多的字符数 M(不可省略) | 可变长度的字符(占用内存 <= M) 效率低 | |
| text | 保存较长文本 | ||
| blob | 较大二进制,图片 | ||
| 位类型 | bit(M) | M:1 ~ 8 | |
| 二进制 | binary | 仅仅包含 二进制字符串,类似 char | |
| varbinary | 仅仅包含二进制字符串,类似 varchar | ||
| 枚举类型 | enum | 枚举类型 | |
| 集合类型 | set | 集合类型 | |
| 日期型 | date | 4 | 只有日期没有时间 |
| time | 4 | 只有时间 | |
| datetime | 8 | 日期加时间,不受时区影响 | |
| 时间戳 | timestamp | 4 | 10位,最多到 2038年的某个时刻,受时区影响show variables like 'time_zone'; 查看时区set time_zone = ‘+8:00’; 设置时区 |
| year | 1 | 年 |
八、约束
01. 常见约束
含义:一种限制,用于限制表中的数据,为了保证表中数据的准确和可靠性
分类:
| 关键字 | 类型 | 备注 |
|---|---|---|
| not null | 非空约束 | 用于保证该字段不能为空,姓名、学号等 |
| primary key | 主键 | 用于保证该字段的值具有唯一性,非空,学号,工号等 |
| default | 默认 | 用于保证该字段有默认值,性别等 |
| unique | 唯一性约束 | 保证该字段的值具有唯一性,可以为空 |
| check | 检查约束 | MySQL 不支持,为了兼容性而存在,年龄,性别 |
| foreign key | 外键 | 其他表的键,用于限制两个表的关系,用于保证该字段的值必须来自主表的关联列的值,在从表田间外键约束,用于引用主表中某列的值; 专业编号,员工表的部门编号,员工表的工种编号 |
-
添加约束的时间:
创建表时
修改表时
-
约束添加的分类:
列级约束:
六大约束语法均支持,但外键约束没有效果,直接在属性后添加约束,可以添加多个表级约束:
除了非空、默认,其他的都支持,在建立表格后面后直接添加 [constraint 约束名] 约束类型,可以针对列名称,添加约束,约束名称应该有意义,但是主键的约束名不起作用。
约束名不可以重复
eg:
DROP TABLE IF EXISTS STUINFO;
CREATE TABLE STUINFO(
ID INT [AUTO_INCREMENT], #主键
STUNAME VARCHAR(20) NOT NULL,
GENDER CHAR(1),
SEAT INT,
AGE INT DEFAULT 20,
MAJORID INT,
CONSTRAINT PK PRIMARY KEY(ID),
CONSTRAINT UQ UNIQUE (SEAT),
CONSTRAINT CK CHECK ( GENDER = '男' OR GENDER = '女' ),
CONSTRAINT FK FOREIGN KEY(MAJORID) REFERENCES MAJOR(ID) [ON DELETE CASCADE|ON DELETE SET NULL] -- 级联删除 // 级联制空:
);
show index from tableName; 查看表的索引(键)
| 键 | 唯一性 | 非空 | 一个表中可以有多少个 | 是否允许组合 |
|---|---|---|---|---|
| 主键 | √ | × | 至多有一个(可以组合成联合索引) | 可以组合,但不推荐 |
| 唯一 | √ | √ | 可以有多个(属性被修饰) | 可以组合,但不推荐 |
外键
- 主表从表的类型相同,列名可以不同
- 主表进行删除时,需要先删除引用主键的从表
- 建立从表时,需要先建立主表
- 主表的关联列必须是一个key(一般是主键、唯一)
- 插入数据时,应该插入主表存在的id,或先插入主表,再插入从表
修改表时添加约束
-
alter table 表名 modify column 字段名 字段类型 新约束 -
列级约束
alter table 表名 add [contraint 约束名] 约束类型(字段名) 外键的引用 [on delete cascade];
删除约束
-
删除非空约束
alter table 表名 modify column 列名 类型 NULL; -
删除默认约束
alter table 表名 modify column age 类型; -
删除主键
alter table 表名 drop primary key; -
删除唯一
alter table 表名 drop index 索引名; -
删除外键
alter table 表名 foreign key 外键索引名;
02. 标识列
又称为自增长列,可以不用手动插入值,系统提供默认的序列值
- 创建表时设置标识列列
DROP TABLE IF EXISTS TAB_IDENTITY;
CREATE TABLE TAB_IDENTITY (
ID INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
-- 插入方式
INSERT INTO TAB_IDENTITY(ID,NAME) VALUES(NULL,'JOHN');
INSERT INTO TAB_IDENTITY(NAME) VALUES('JOHN');
-- 查看步长变量
SHOW VARIABLES LIKE '@AUTO_INCREMENT%';
-- 步长可以设置
SET AUTO_INCREMENT_INCREMENT=3;
-- 偏移量无作用:AUTO_INCREMENT_OFFSET = 1; 起始值是1
-- 标识列的前提必须是 KEY 约束(UNIQUE、PRIMARY KEY、FOREIGN KEY?)
-- 一个表至多有一个标识列
-- 仅仅数值型的能够能够自增长
-- 修改表时设置标识列
ALTER TABLE TAB_IDENTITY MODIFY COLUMN ID INT PRIMARY KEY AUTO_INCREMENT;
-- 修改表时删除标识列
ALTER TABLE TAB_IDENTITY MODIFY COLUM ID INT PRIMARY KEY;
九、视图
含义:虚拟表,和普通表一样使用
mysql 5.1 版本出现的新特性,是通过表动态生成的数据,具有临时性
一种虚拟存在的表,行和列的数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的,只保存了 sql 逻辑,不保存查询结果;
-- 1. 创建视图
CREATE VIEW 视图名
AS 查询逻辑语句
-- 2. 使用视图
SELECT 属性 FROM 视图名 [LEFT|RIGHT|INNER JOIN]WHERE 筛选条件;
-- 视图的作用:提高复用性,重用 SQL 语句
-- 简化复杂的 SQL 操作,不必知道他的查询细节
-- 保护数据提高安全性
-- 3. 视图的修改
CREATE OR REPLACE VIEW 视图名
AS 查询语句;
-- 4. 删除视图
DROP VIEW 视图名1,视图名2....
-- 5. 查看视图
DESC 视图名;
SHOW CREATE VIEW 视图名; -- 显示视图创建的逻辑
-- 6. 查看数据库下所有的视图
SELECT * FROM INFORMATION_SCHEMA.VIEWS;
-- 7. 视图的更新
/*
插入视图的数据最终会插入到原始 SQL 逻辑中的原始表,需要原始表支持插入
更新同理,有效
删除同理,有效
往往 VIEW 的权限是仅仅是只读,不允许更新
包含以下关键字不能更新:
分组函数 DISTINCT GROUP BY、HAVING、UNION、UNION ALL
常量视图
SELECT 中包含子查询
JOIN (INSERT INTO 不能插入)
FROM 一个不能更新的视图
WHERE 子句的子查询引用了 FROM 子句中的表
*/
十、变量
系统变量
- 全局变量
- 会话变量
自定义变量
- 用户变量
- 局部变量
01. 系统变量
说明:变量由系统提供,不是用户定义的,属于服务器层面
注意:如果是全局级别,则需要加 global, 如果使绘画界别,则需要加 session, 如果不写,则默认 session
全局变量
作用域:服务器每次启动将为所有的全局变量赋初始值,针对所有的会话(连接)有效,但不能跨重启(重启变为初始化,如需要则需更改配置文件)
会话变量:
作用域:仅仅针对于当前会话(连接)有效
-- 1. 查看所有的系统变量
SHOW GLOBAL|[SESSION] VARIABLES;
-- 2. 查看满足条件的部分系统变量
SHOW GLOBAL|[SESSION] VARIABLES LIKE '%CHAR';
-- 3. 查看指定的某个系统变量的值
SELECT @@GLOBAL|[SESSION].系统变量名;
-- 4. 为某个系统变量赋值
-- 方式1:
SET GLOBAL|[SESSION] 系统变量名 = 值;
-- 方式2
SET @@GLOBAL|[SESSION].系统变量名 = 值;
02 自定义变量
说明:变量是用户自定义的,不是系统定义的
使用步骤:
- 声明
- 赋值、更新
- 使用(查看,比较,计算等)
-- 作用域:针对于当前会话(连接)有效,同于会话变量的作用域,应用于任何地方,也就是 BEGIN END 里面,或者外面
-- ① 声明并初始化
SET @用户变量名 = 值;
SET @用户变量名:= 值;
SELECT @用户变量名 := 值;
-- ② 赋值(更新用户变量的值)
-- 方式1: 通过 SET SELECT
SET @用户变量名 = 值;
SET @用户变量名:= 值;
SELECT @用户变量名 := 值;
-- 方式2:
SELECT 字段 INTO 变量名 FROM 表;
-- 方式3:
SELECT 值 INTO 变量名;
局部变量:仅仅在 BEGIN END 中有效,只能在第一行中进行声明
-- 1 声明
DECLARE 变量名 类型;
DECLARE 变量名 类型 DEFAULT 值;
-- 2 赋值
-- 方式1:通过 SET 或者 SELECT
SET 局部变量名 = 值;
SET 局部变量名 := 值;
SELECT @局部变量名 := 值;
-- 方式2
SELECT 值、字段 INTO 局部变量名
FROM 表;
-- 3. 使用
SELECT 局部变量名;
对比用户变量和局部变量:
| 作用域 | 定义和使用的位置 | 语法 | |
|---|---|---|---|
| 用户变量 | 当前会话 | 会话中的任何位置 | 必须添加@符号,不用限定类型 |
| 局部变量 | BEGIN END | 只能在 BEGIN END 中,且为第一句话 | 一般不用加@符号,限定类型 |
十一、存储过程和函数
01. 存储过程
存储过程和函数,类似 Java 中的方法
优点:
- 提高代码的重用性
- 简化操作
- 减少了编译次数,减少了和数据库服务器的连接次数,提高了效率
一组预先编译好的 SQL 语句的集合,理解成批处理语句
-- 1. 创建
CREATE PROCEDURE 存储过程名(参数列表)
BEGIN
存储过程体(一组合法有效的 SQL 语句)
END
-- 参数列表包含三部分
-- 参数模式 参数名 参数类型
-- 举例:
IN STUNAME VARCHAR(20)
-- 参数模式:
IN:该参数可以作为输入,该参数需要调用方法传入值:(默认)
OUT:该参数可以作为输出,该参数可以作为返回值(调用时不用在外部声明变量)
INOUT:该参数既可以作为输入也可以作为输出,既可以传入值,又可以返回值(调用时需要在外部声明变量)
-- 如果存储过程体只有一句话,BEGIN END 可以省略,存储过程体中的 SQL 语句的结尾要求必须加分号。
-- 存储过程的结尾可以使用 DELIMITER 重新设置
DELIMITER 结束标记
DELIMITER $
-- 2. 使用
CALL 存储过程名(实参列表);
-- 3. 删除存储过程
DROP PROCEDURE [IF EXISTS] 存储过程名;
-- 4. 查看存储过程的信息,存储过程不支持修改
SHOW CREATE PROCEDURE 存储过程名;
02. 函数
含义:一组预先编译好的 sql 语句的集合,理解成批处理语句
- 提高代码的重用性
- 简化操作
- 减少了编译次数并且和数据库服务器的连接次数,提高了效率
区别:可以有 0 个返回,也可以有多个返回,适合做批量插入、批量更新
函数:有且仅有一个返回,适合做处理数据后返回一个结果
-- 1 创建语法
CREATE FUNCTION 函数名(参数列表) RETURNS 返回类型
BEGIN
函数体
END
/*
参数列表:
参数名 参数类型
函数体:
肯定会有 RETURN 语句,如果没有会报错
RETURN 语句位置应该要正确(一般位于整个函数体最后位置)
RETURN 值;
省略:函数体仅有一条语句
使用 DELIMITER 语句设置结束语句
DELIMITER $
*/
-- 2 调用语法
SELECT 函数名(参数列表);
-- 3 查看函数
SHOW CREATE FUNCTION 函数名; -- 查看函数的定义
-- 4 删除函数
DROP FUNCTION 函数名;
03. 流程控制结构
- 顺序结构:程序从上往下依次执行
- 分支结构: 程序可从两条或多条路径中选择一条去执行
- 循环结构:程序在满足一定条件的基础上,重复执行一段代码
-- 一 分支结构
-- 1. IF函数:实现简单的双分支
-- 执行顺序:如果表达式1成立,则 IF 函数返回 表达式2 的值,否则返回表达式 3 的值
SELECT IF(表达式1,表达式2,表达式3)
-- 2. CASE 结构
-- 情况1:类似 JAVA 中的 SWITCH 语句,一般用于实现的等值判断
CASE 变量|表达式|字段
WHEN 要判断的值 THEN 返回值1
WHEN 要判断的值 THEN 返回值2
...
ELSE 要返回值的值 N
END CASE;
-- 情况2:类似 JAVA 中的 多重 IF 语句,永伴用于实现区间判断
CASE
WHEN 要判断的值 THEN 返回值1 或 语句1
WHEN 要判断的值 THEN 返回值2 或 语句2
...
ELSE 要返回值的值 N 或 语句N
END CASE;
-- 特点:可以作为表达式,嵌套在其他语句中使用,可以放在任何地方, BEGIN END 中或 BEGIN END 外面,可以作为独立的语句去使用,这能放在 BEGIN END 中
-- 如果 WHEN 中的值满足或条件成立,则执行 THEN 后面的语句,并结束 CASE,如果都不满足,则执行 ELSE 中的语句或值
--如果无 ELSE, 则都不执行,返回 NULL
--3. IF 结构 应用在 BEGIN END 中
-- 功能:实现多重分支
IF 条件1 THEN 语句1;
ELSEIF 条件2 THEN 语句2;
...
[ELSE 语句N;]
END IF;
-- 二 循环结构 : WHILE、LOOP、REPEAT
-- 循环控制:
ITERATE(迭代):继续,结束本次循环,继续下一次
LEAVE 类似于 BREAK,跳出,结束当前所在的循环
-- 1.WHILE
[标签:] WHILE 循环条件 DO
循环体;
END WHILE [标签];
-- 2. LOOP:可以用来模拟见到那的死循环
[标签:] LOOP
循环体;
END LOOP [标签];
-- 3. REPEAT
[标签:] REPEAT
循环体;
UNTIL 结束条件
END REPEAT [标签];
-- 示例 LEAVE ITERATE
DELIMITER $
CREATE PROCEDURE PRO_WHILE(IN COUNT INT)
BEGIN
DECLARE I INT DEFAULT 1;
A:WHILE I <= COUNT DO
INSERT INTO ADMIN(USERNAME, PASSWORD) VALUES(CONCAT('ROSE',I), '666');
SET I:=I+1;
IF I > 20 THEN LEAVE A;
END IF;
END WHILE A;
END $
CREATE PROCEDURE PRO_WHILE(IN COUNT INT)
BEGIN
DECLARE I INT DEFAULT 0;
A:WHILE I <= COUNT DO
SET I:=I+1;
IF I % 2 = 0 THEN ITERATE A;
END IF;
INSERT INTO ADMIN(USERNAME, PASSWORD) VALUES(CONCAT('ROSE',I), '666');
END WHILE A;
END $
创建函数时需要指定 DETERMINISTIC、NO SQL、 READS SQL DATA














 1158
1158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









