







文章目录
1、简介
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
2、安装ElasticSearch
ubuntu使用命令行apt安装,mac下载解压使用,下面示例主要使用的是mac系统下面的es版本7.12.0
安装jdk
sudo apt update
sudo apt install apt-transport-https
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
sudo sh -c 'echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" > /etc/apt/sources.list.d/elastic-7.x.list'
sudo systemctl enable elasticsearch.service (设置开机自启动)
sudo systemctl start elasticsearch.service (启动)
sudo systemctl stop elasticsearch.service (停止)
sudo systemctl restart elasticsearch.service (重启)
sudo systemctl status elasticsearch.service (查看状态)
使用 curl -X GET “localhost:9200/” 测试是否启动成功
{
"name" : "Mac",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Gz-LMjbISM-8uWPiHC3fug",
"version" : {
"number" : "7.12.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "78722783c38caa25a70982b5b042074cde5d3b3a",
"build_date" : "2021-03-18T06:17:15.410153305Z",
"build_snapshot" : false,
"lucene_version" : "8.8.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
若在服务器中启动失败,可能为内存太小,修改配置文件**/etc/elasticsearch/jvm.options **
## -Xms4g
## -Xmx4g
-Xms258m
-Xmx258m
配置远程连接,则设置elasticsearch.yml 文件
#设置为0.0.0.0
network.host: 0.0.0.0
#取消注释
cluster.initial_master_nodes: ["node-1", "node-2"]
3、ES可视化elasticsearch-head
#进入到项目目录
npm install
npm run start
连接时遇到跨域问题

解决:修改elasticsearch.yml配置文件,增加下面跨域配置后重新启动
http.cors.enabled: true
http.cors.allow-origin: "*"
4、使用Kibana(版本需与ES一致)
解压后需要先启动es再启动kibana,默认端口为5601
设置中文,修改kibana.yml配置文件
i18n.locale: "zh-CN"
5、使用ik分词器(版本需与ES一致)
ik提供的两个算法:
- ik_smart:最少切分
- ik_max_word:最细粒度划分
下载解压后放入到es的plugins中,并重命名文件夹名称

测试查看已有的插件

重新启动es与kibana,从kibana中测试ik分词器,字典中查找
ik_smart:最少切分

ik_max_word:最细粒度划分

未自定义之前
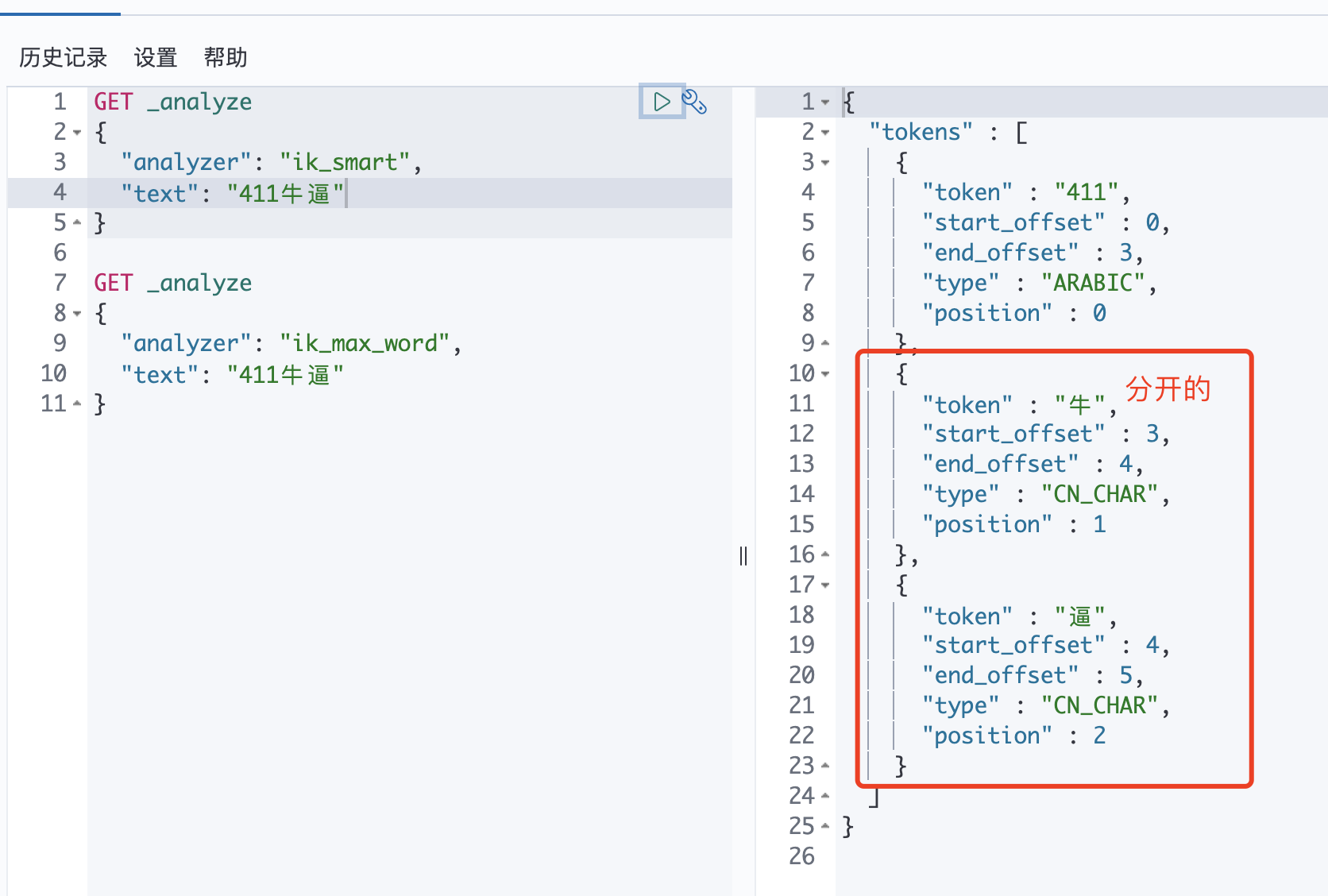
在ik配置文件中添加自己自定义的dic文件

如果需要自定义的分词,多个自定义的dic文件使用 “;” 间隔

修改完后重新启动

变成自定义的单词

6、索引文档操作
创建索引PUT
不推荐使用类型名,换成 “_doc” 使用
PUT /索引名/类型名(后期可不写)/id
{
请求体
}
PUT /test1/type1/1
{
"name": "袁凯强",
"age": 18
}

创建完成后

ES的类型可以有多个
- 字符串类型:text、keyword
- 数值类型:long、integer、short、byte、double、float、half float、scaled float
- 日期类型:date
- 布尔类型:boolean
- 二进制类型:binary
指定字段的类型

获取索引或文档GET
通过GET请求获取具体的信息,后面跟索引名或者是id名都可以
#简单查询
GET test1
GET /test1/_doc/1
#条件查询
GET /test1/_search?q=name:袁
GET /test1/_search?q=name:袁凯强1

通过GET _cat/xxx 命令可以获取系统中的其它信息

修改**(两种方式)**
-
直接通过 PUT 方式进行修改
PUT /test1/type1/1 { "name": "袁凯强1", "age": 21 }
-
通过 POST 方式进行修改(推荐使用)
POST /test1/type1/1/_update { "doc": { "name": "袁凯强12", "age":99 } }
删除DELETE
DELETE test2

复杂操作搜索select(排序、分页、高亮、模糊查询、精准查询)
GET /test1/_search
{
"query": {
"match": {
"name": "袁"
}
}
}

-
查询:query
GET /test1/_search { "query": { "match": { "name": "袁" } } }
-
结果过滤 :_source
"_source": ["name"]
-
排序:sort(根据数值类型进行排序)
"sort": [ { "age": { "order": "desc" } } ]
-
分页:from、size
"from": 0, "size": 1
-
布尔值查询:bool
"bool": { "must": [ { "match": { "name": "袁凯强" } }, { "match": { "age": 21 } } ] }must 相当于mysql中条件中的and
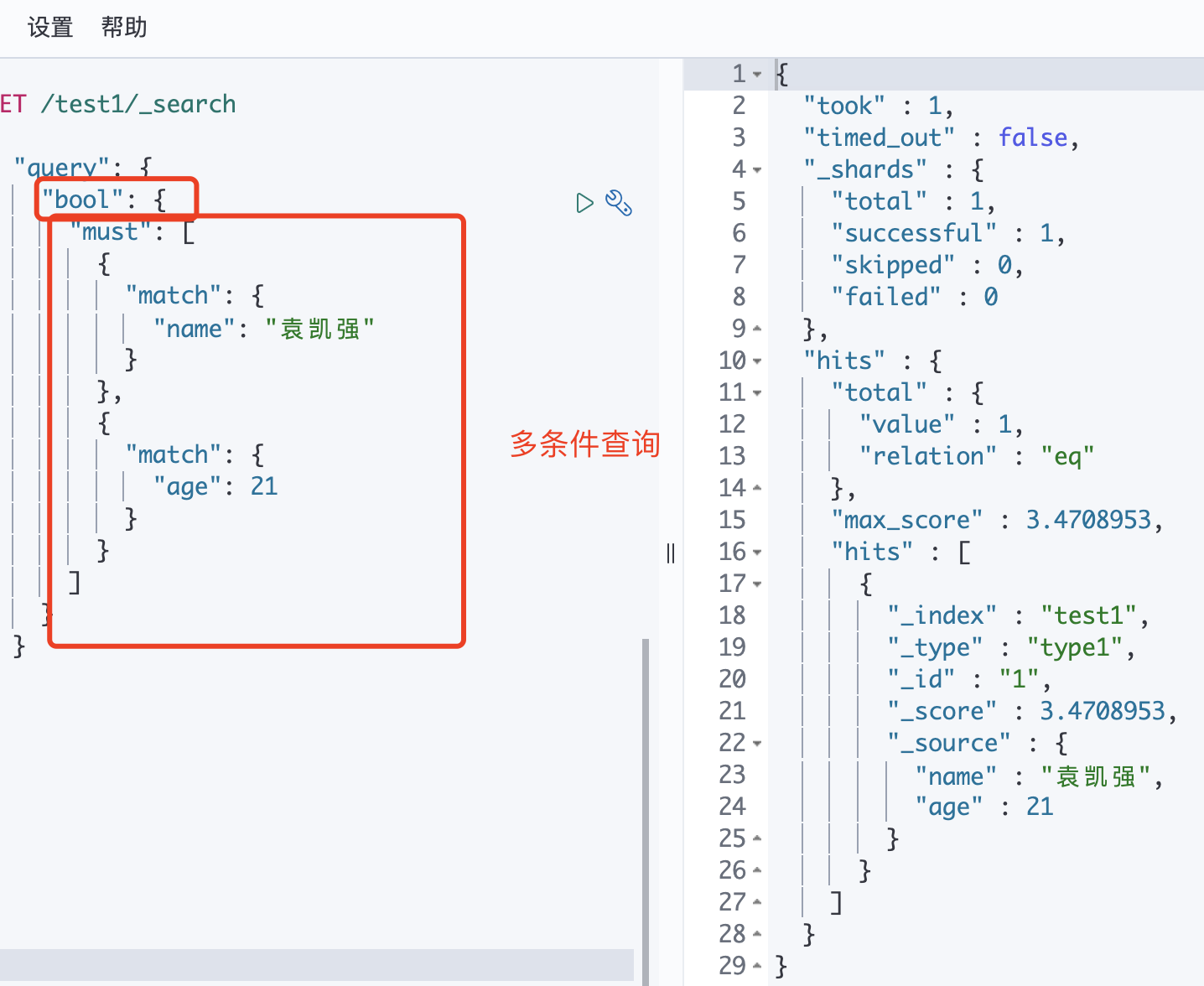
should 相当于mysql中条件中的or

must_not 相当于mysql中条件中的not
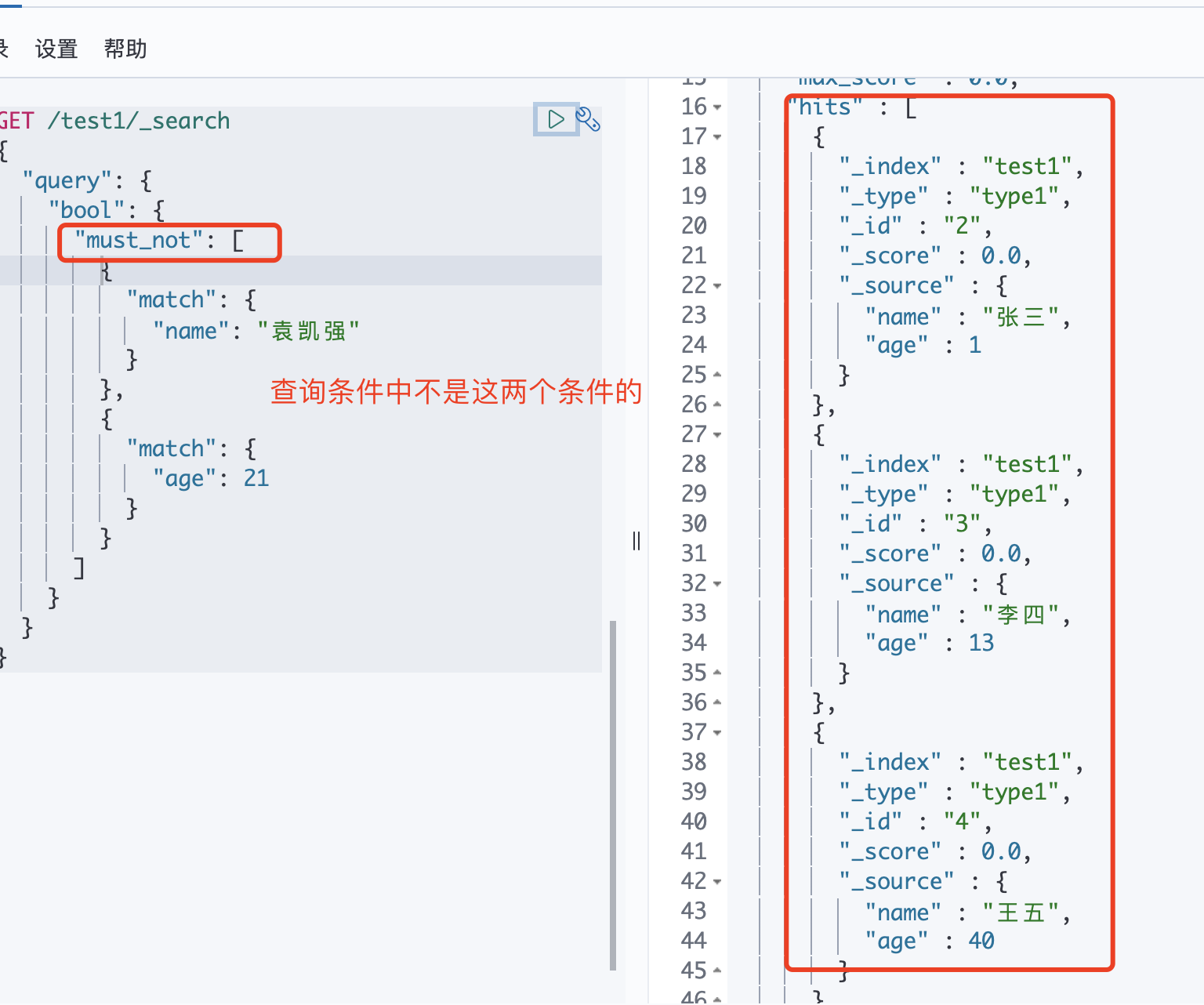
-
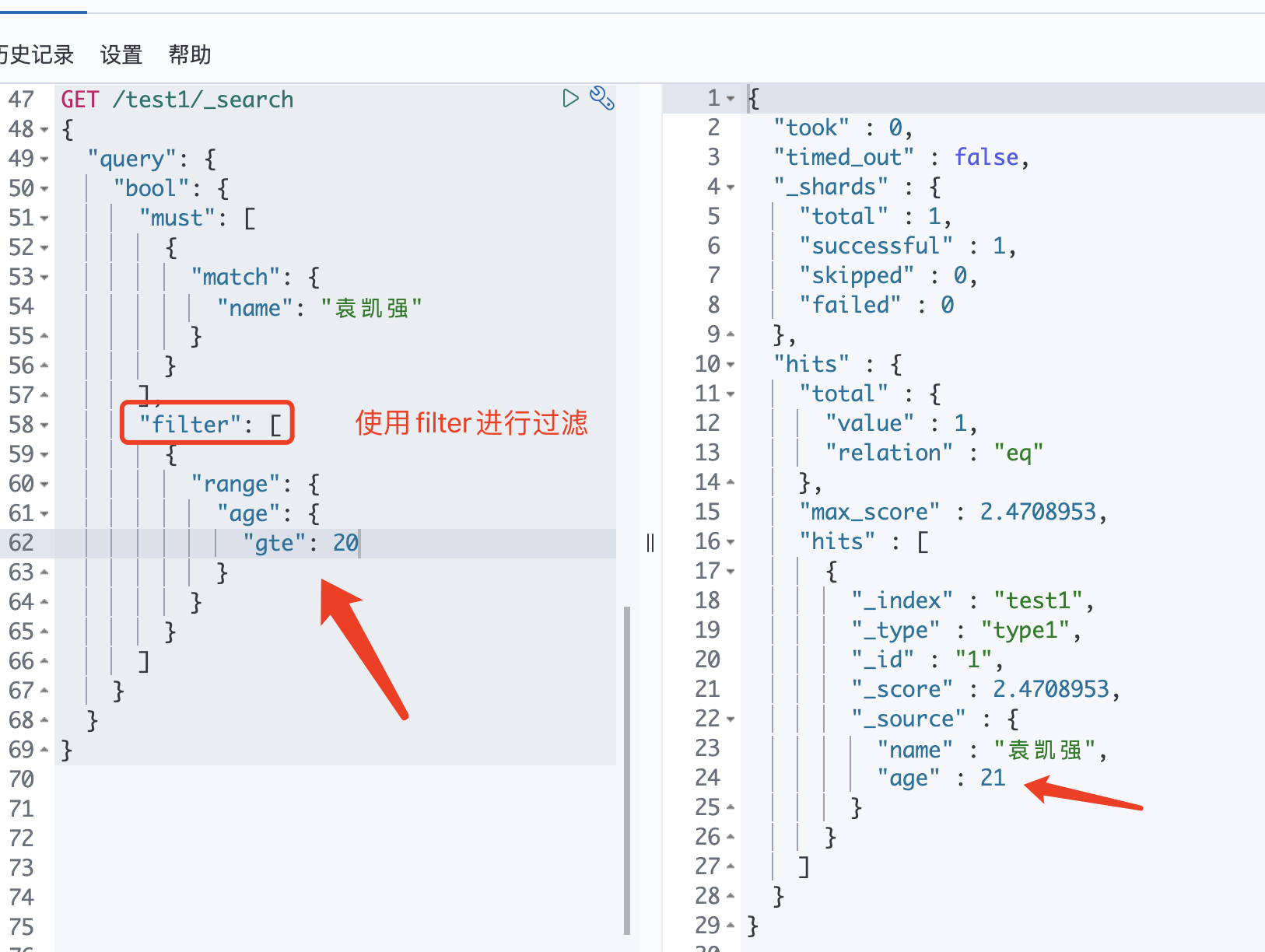
过滤:filter
"filter": [ { "range": { "age": { "gte": 20 } } } ]eq相等,ne、neq不相等,gt大于,lt小于,gte、ge大于等于,lte、le 小于等于,not非,mod求模,div by是否能被某数整除,even是否为偶数,odd是否为奇
-
匹配多个条件进行查询match
"query": { "match": { "name": "袁 张" } }
-
精确查询:term,term查询是直接通过倒排索引指定的词条进程精确查找的
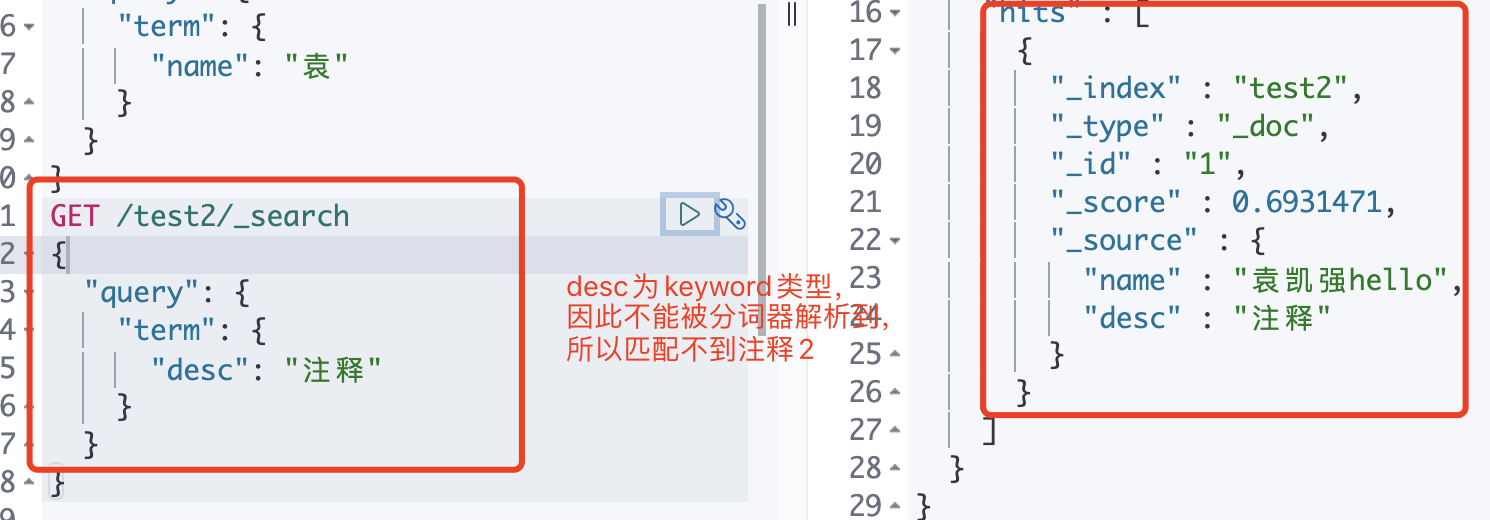
PUT test2 { "mappings": { "properties": { "name": { "type": "text" }, "desc": { "type": "keyword" } } } } PUT test2/_doc/1 { "name": "袁凯强hello", "desc": "注释" } PUT test2/_doc/2 { "name": "袁凯强hello", "desc": "注释2" } GET _analyze { "analyzer": "keyword", "text": "袁凯强Hello" } GET _analyze { "analyzer": "standard", "text": "袁凯强Hello" } GET /test2/_search { "query": { "term": { "name": "袁" } } } GET /test2/_search { "query": { "term": { "desc": "注释" } } }使用es默认的分词器keyword与standard
keyword不会被拆分

standard会被拆分

因为name与desc中的字段类型不一样,keyword不能被分词器解析

name:text类型(trem+text分词查询=》通过standard解析)

desc:keyword类型(trem+keyword精确查询=》通过keyword解析)
多个值匹配精确查询

-
高亮查询:highlight
"highlight":{
"fields":{
"name":{}
}
}

自定义高亮的标签,默认为em

7、集成SpringBoot


maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
使用的对象

导入依赖时,保证es版本与系统版本的一致

精确查找时,不想被分词器解析

-
定义的时候加上定义的类型
@Field(type=FieldType.Text, analyzer="ik_max_word") 表示该字段是一个文本,并作最大程度拆分,默认建立索引
@Field(type=FieldType.Text,index=false) 表示该字段是一个文本,不建立索引
@Field(type=FieldType.Date) 表示该字段是一个文本,日期类型,默认不建立索引
@Field(type=FieldType.Long) 表示该字段是一个长整型,默认建立索引
@Field(type=FieldType.Keyword) 表示该字段内容是一个文本并作为一个整体不可分,默认建立索引
@Field(type=FieldType.Float) 表示该字段内容是一个浮点类型并作为一个整体不可分,默认建立索引
date 、float、long都是不能够被拆分的

使用类似于JPA的形式使用elasticsearchanalyzer和search_analyzer的区别
Elasticsearch中analyzer和search_analyzer的区别 10
analyzer和search_analyzer的区别
在创建索引,指定analyzer,ES在创建时会先检查是否设置了analyzer字段,如果没定义就用ES预设的
在查询时,指定search_analyzer,ES查询时会先检查是否设置了search_analyzer字段,如果没有设置,还会去检查创建索引时是否指定了analyzer,还是没有还设置才会去使用ES预设的
使用类似于JPA的形式使用elasticsearch
测试代码:关注公众号原棵哈回复es获取

参考网址
https://www.myfreax.com/how-to-install-elasticsearch-on-ubuntu-18-04/ ↩︎
https://github.com/mobz/elasticsearch-head ↩︎
https://www.elastic.co/cn/downloads/kibana ↩︎
https://github.com/medcl/elasticsearch-analysis-ik/releases ↩︎
https://www.elastic.co/guide/en/elasticsearch/client/index.html ↩︎
https://artifacts.elastic.co/javadoc/org/elasticsearch/client/elasticsearch-rest-client/7.12.0/org/elasticsearch/client/package-summary.html ↩︎
https://blog.csdn.net/dg19971024/article/details/107103201/ ↩︎
https://blog.csdn.net/qq_15267341/article/details/108017505 ↩︎
https://my.oschina.net/u/4381576/blog/3416666 ↩︎
https://blog.csdn.net/user2025/article/details/108691367 ↩︎
https://blog.csdn.net/qq_43652509/article/details/83989257 ↩︎
https://blog.csdn.net/u013089490/article/details/84323903 ↩︎
















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











