







基础知识
卷积层
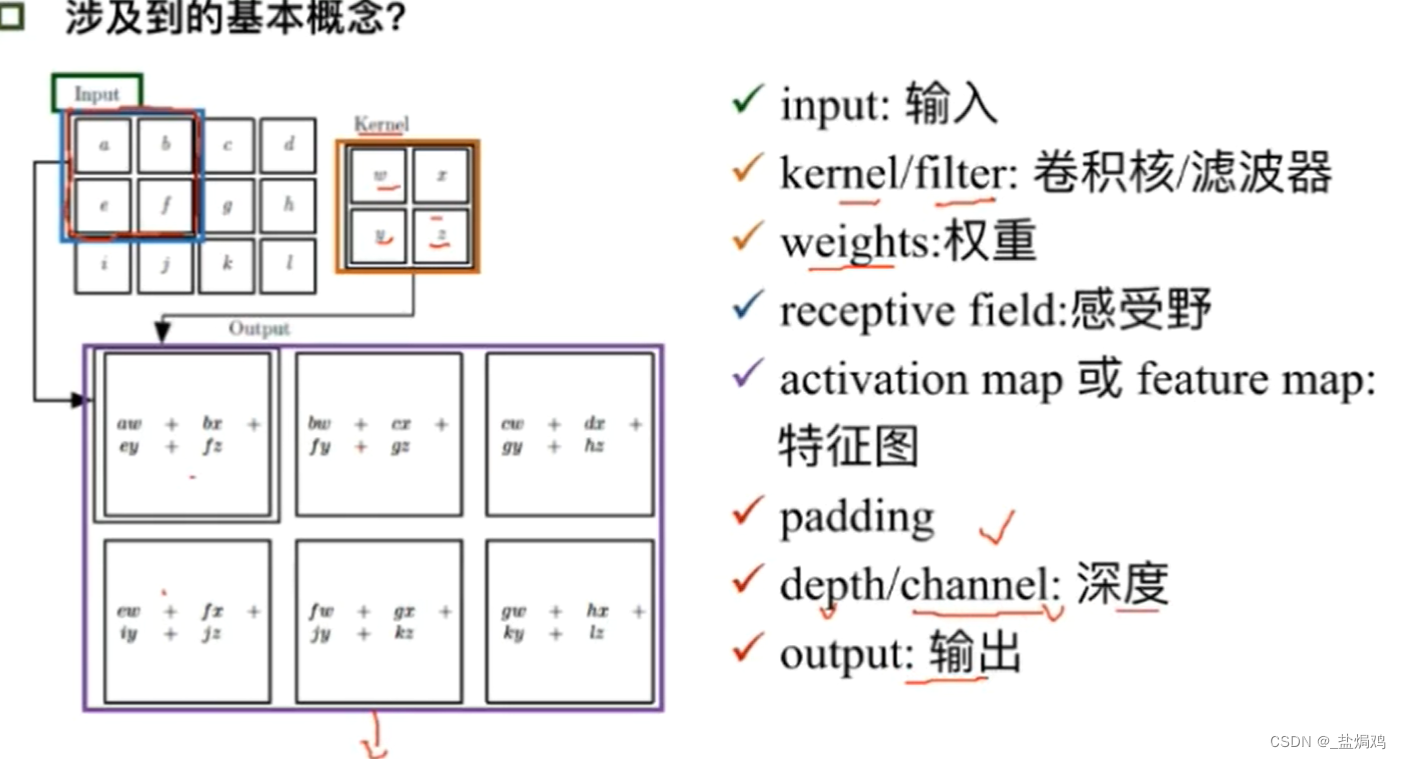
- 输出图片尺寸公式:(N+padding*2-F)/stride+1
- padding是个填充,他的存在是因为卷积核可能不会刚好够,需要填充其他数据保证一层的数据不会被丢失,一般取1或2(不能整除的情况下)。
池化
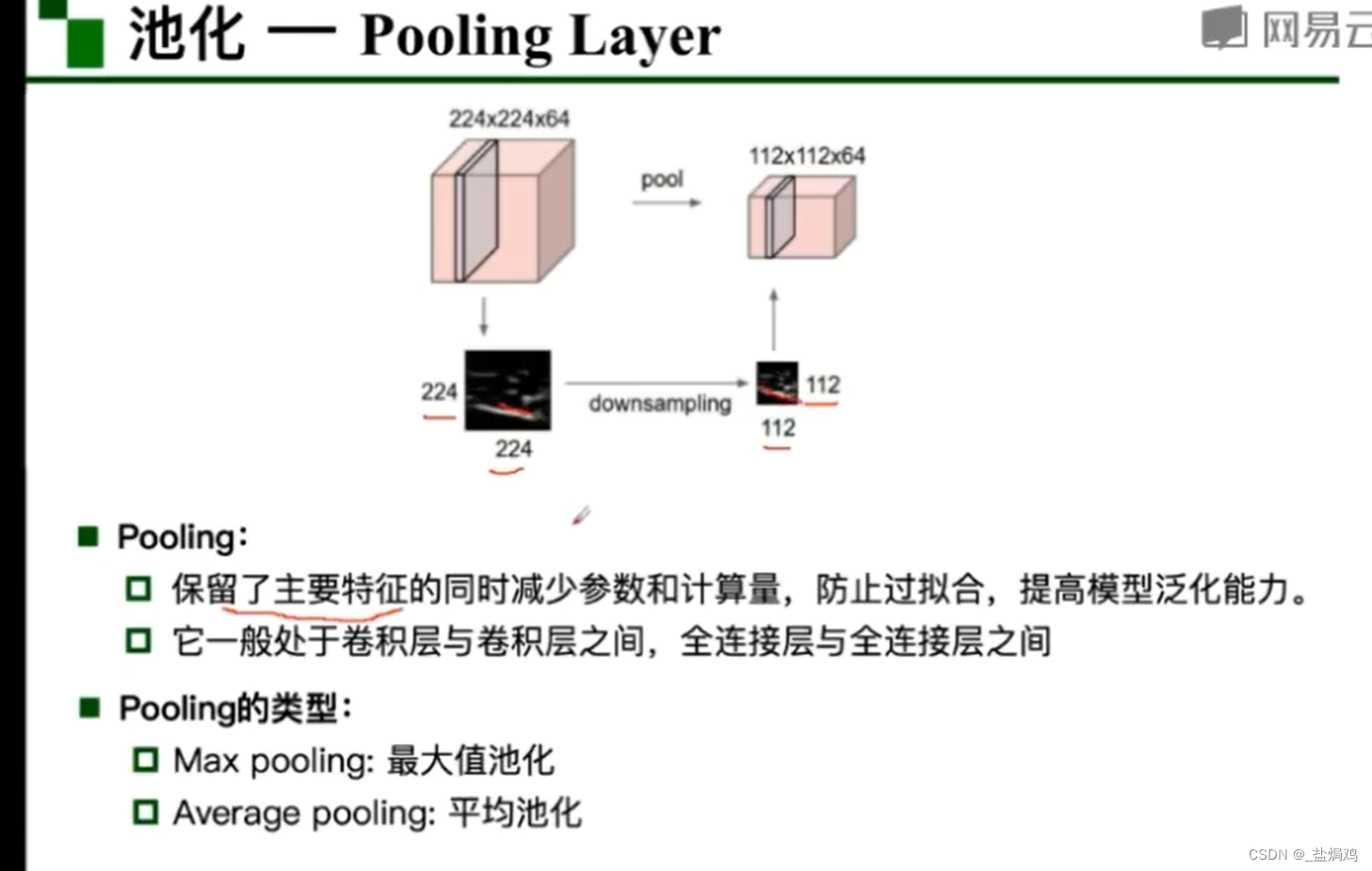
池化类似于采样,有多种方法,比如经典的最大值池化和随机池化等
全连接层fc
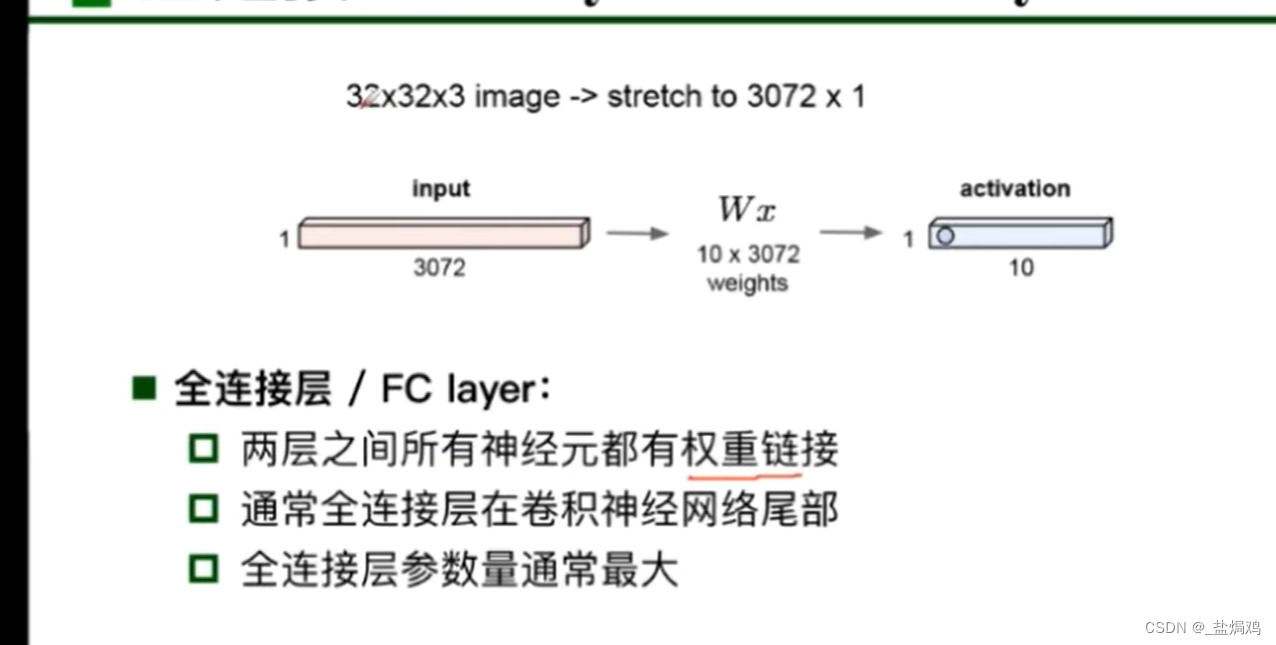
全连接层一般把输入的特征转化为一层的向量。
个人理解:神经网络就是把人能理解的信息(如图片)通过压缩转化为机器能理解的信息(如4096*1)的向量。
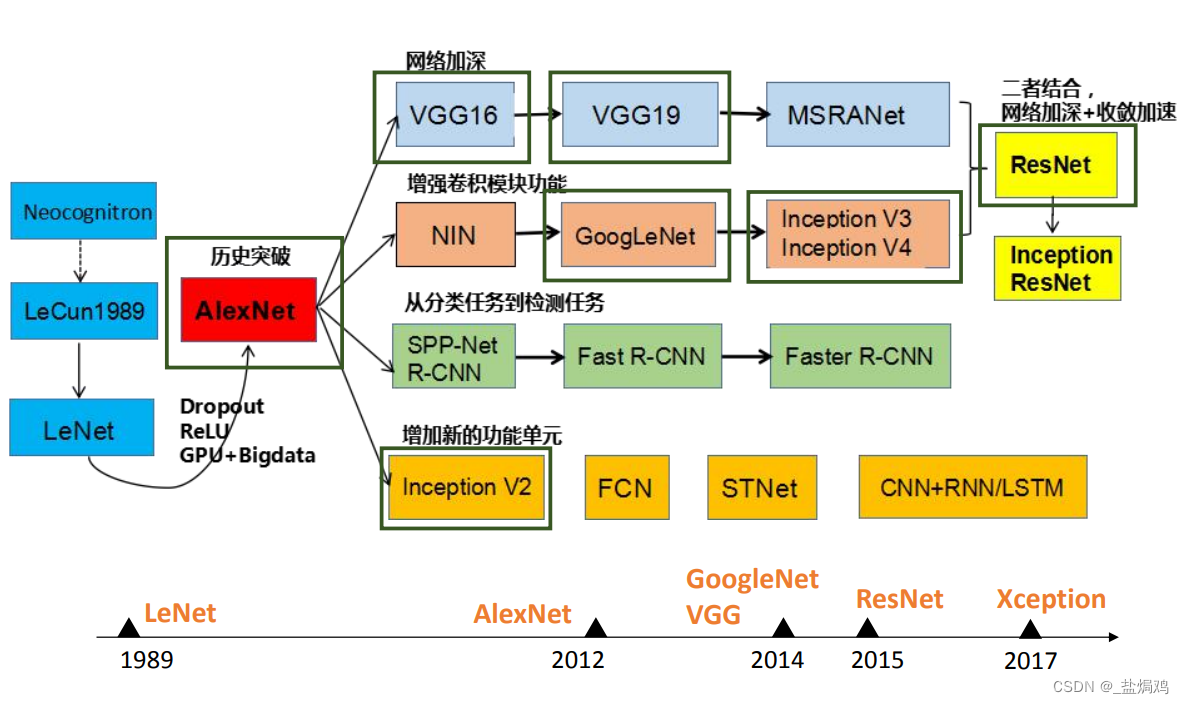
AlexNet
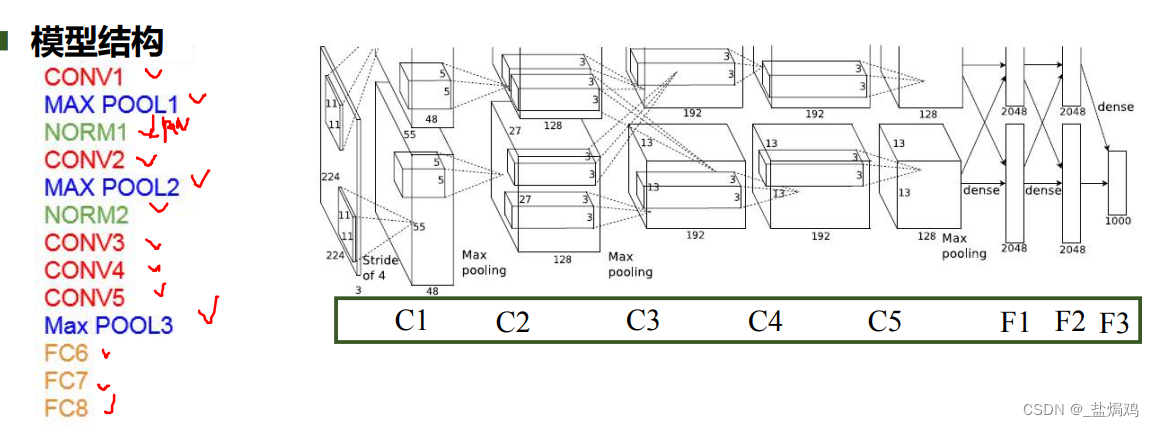
AlexNet是奠基之作,他提出了ReLU函数和防止过拟合的Dropout方法,双GPU实现。
- C1,C2都是卷积-ReLU-池化的过程
- C2和C3在两块GPU中间采用了通信,然后C3,C4都没用池化,直接卷积-ReLU
- C5又是卷积-ReLU-池化
- F1F2就是全连接-ReLU-DropOut
- F3全连接+softmax
这里面的DropOut就是对隐藏层的单元,有百分之五十的可能性置零。我看了李沐的精读,作者可能是为了多网络融合,但是好像并没有起到相应的效果,而是一个L2正则化的效果(这部分不太明白,以后加强)。
VGG

AlexNet不太规范,所以VGG想更规范,更大,更深。
- VGG块 :大量(n层)33的卷积+22池化
- 不同次数重复块就能得到不同架构(VGG-16,VGG-19)
GoogleNet
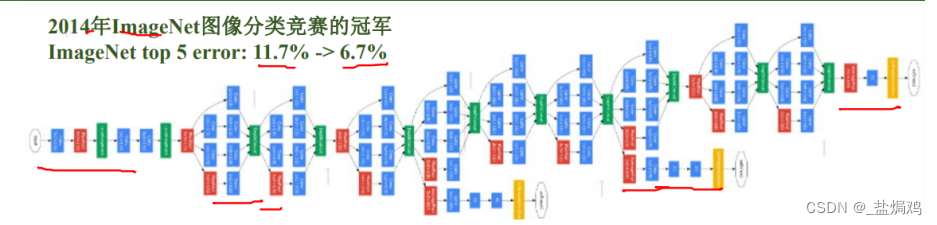
-
多卷积核增加特征多样性
-
层数较大,总共可能有100个
-
无FC层
-
Inception块:输入输出大小一直,层数通过串联保持一致
-
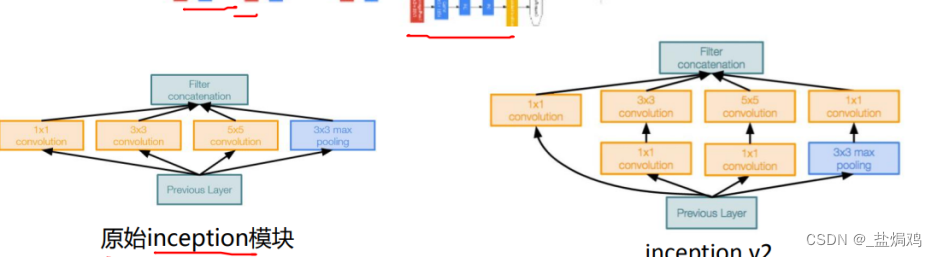
-
InceptionV2,V3采用小的卷积核代替大的,对参数量进一步降低,且卷积多了,训练更快表征能力更强
ResNet
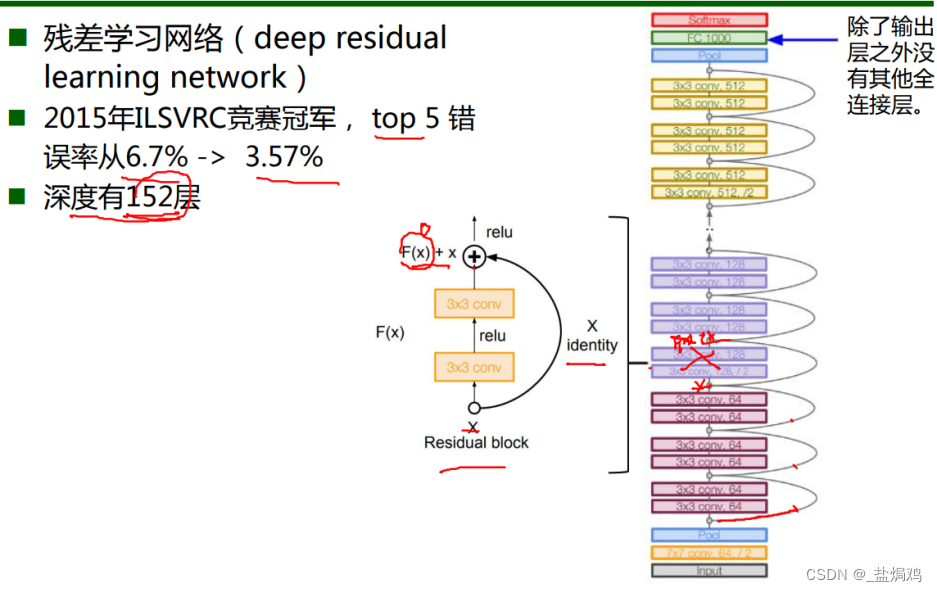
-
更深:深度152层,而没有梯度消失问题
-
与传统网络的差别:
-

-
输入为x,得到的f(x)=g(x)+x
$y=f(x),y^,=g(f(x)).

代码练习
CNN进行MINIST手写数据集分类
class CNN(nn.Module):
def __init__(self, input_size, n_feature, output_size):
# 执行父类的构造函数,所有的网络都要这么写
super(CNN, self).__init__()
# 下面是网络里典型结构的一些定义,一般就是卷积和全连接
# 池化、ReLU一类的不用在这里定义
self.n_feature = n_feature
self.conv1 = nn.Conv2d(in_channels=1, out_channels=n_feature, kernel_size=5)
self.conv2 = nn.Conv2d(n_feature, n_feature, kernel_size=5)
self.fc1 = nn.Linear(n_feature*4*4, 50)
self.fc2 = nn.Linear(50, 10)
# 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来
# 意思就是,conv1, conv2 等等的,可以多次重用
def forward(self, x, verbose=False):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = x.view(-1, self.n_feature*4*4)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
网络构造中大致描述了网络的构成,在forward中定义了网络的结构
对全连接网络,打乱图像像素对网络性能几乎没有变化
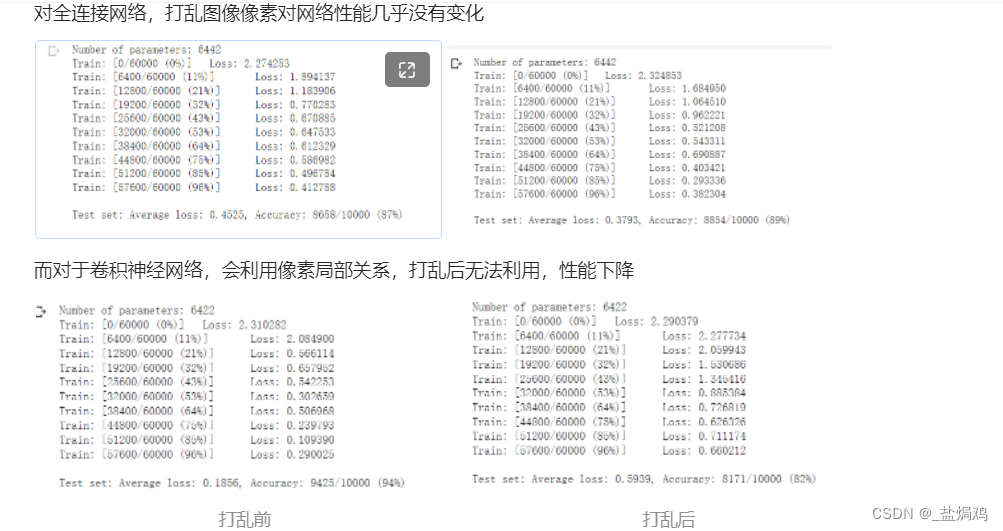
打乱方法
perm = torch.randperm(784)
def perm_pixel(data, perm):
# 转化为二维矩阵
data_new = data.view(-1, 28*28)
# 打乱像素顺序
data_new = data_new[:, perm]
# 恢复为原来4维的 tensor
data_new = data_new.view(-1, 1, 28, 28)
return data_new
这里面的打乱是生成一个784维的随机数tensor,然后替换掉原有的值
CNN 对 CIFAR10 数据集
网络结构
在这里插入代码片
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
准确率仅为63%,可能换个网络好一点
使用 VGG16 对 CIFAR10 分类
网络结构
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.cfg = [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M']
self.features = self._make_layers(self.cfg)
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
先试着运行一遍
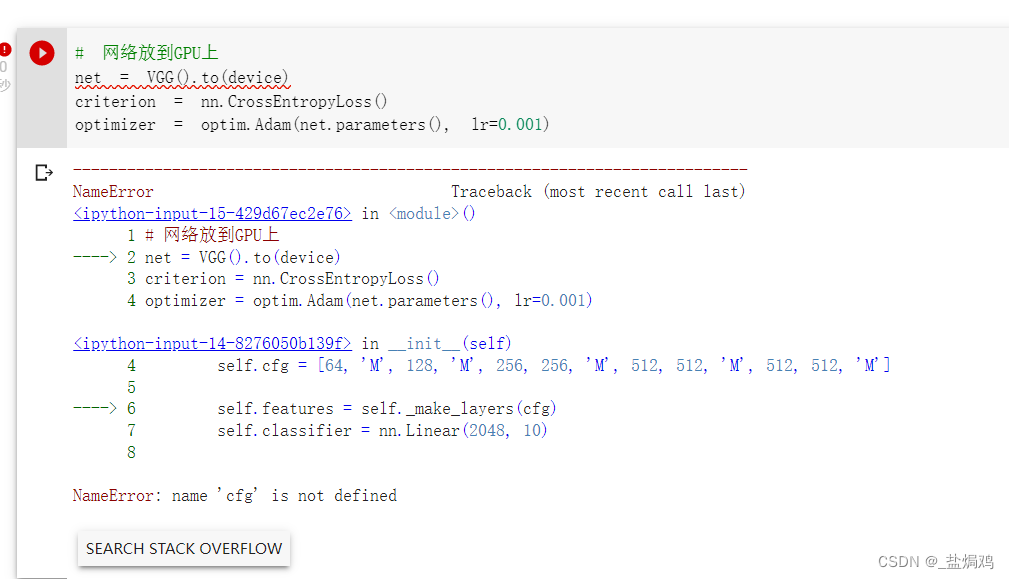 self改成self.cfg
self改成self.cfg
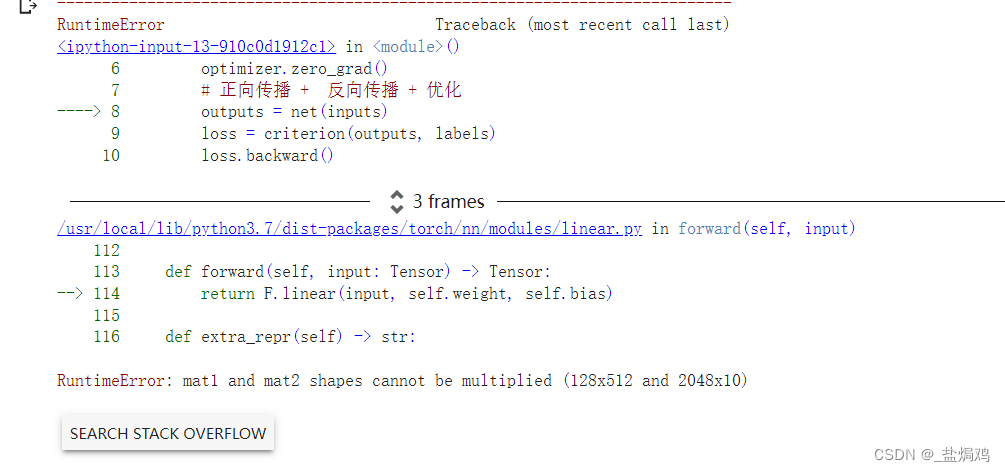
这波是最后一个卷积层的输出和分类器的输出不太一样,改成也一样就行了
self.classifier = nn.Linear(512, 10)
可以看到效果明显好了,应该是VGG-16更深,激活函数更多,所以非线性能力更强。

问题回答
- dataloader 里面 shuffle 取不同值有什么区别?
- shuffle是指每轮训练是否随机打断顺序,True代表打断,Flase代表不打断
- transform 里,取了不同值,这个有什么区别?
- transform是常用图像预处理方法
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
不同值主要是均值和标准差的设置,维度不同主要是对不同通道进行设置。
- 以这个代码为例,Compose函数的作用是把多个步骤整合在一起,这里把ToTensor和Normalize整合到一起了。
- transforms.Normalize(mean, std, inplace=False),对于每个通道,执行如下操作image=(image-mean)/std
- mean是均值,std是标准差,inplace代表是否原地操作
- transforms.ToTensor() 转化为Tensor类型
-
epoch 和 batch 的区别?
- batch指训练批/一批样本,即一次训练的样本数目
- epoch表示轮次,即把一个完整的数据即通过了神经网络并返回一次的过程
- 举例:比如一个数据集有2000个样本,batch_size =500,那么完成一次epoch=完成4次batch
-
1x1的卷积和 FC 有什么区别?主要起什么作用?
- 输入和输出尺寸的区别,全连接层只能固定输出,而11的卷积的输出随输入尺寸而变换.只有输入为11*n时,才能互换。
- 在分类问题上,conv或fc输入是1×1,没有区别,都是起到分类器的作用。
-
residual leanring 为什么能够提升准确率?
- W = f ( x ) + x , ∂ W ∂ x = ∂ y ∂ x + 1 W =f(x)+x,\frac{\partial W }{\partial x} =\frac{\partial y }{\partial x} +1 W=f(x)+x,∂x∂W=∂x∂y+1所以这个梯度最小也是1。如果为1,会导致"跳转”,中间的那些层并没起作用,就是仅仅做了个恒等映射。
- 这个原理解决了梯度消失。
-
代码练习二里,网络和1989年 Lecun 提出的 LeNet 有什么区别?
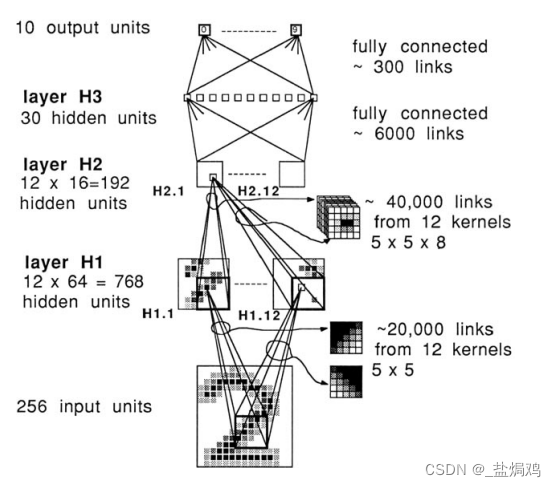
- 激活函数不同,LeNet用的激活函数为tanh的变种,实际的为x = 1.7159 * tanh(2/3*x)。而代码练习二里面的为ReLU
- output,这个虽然也是全连接层。但是现在好像都改用了softmax了
-
代码练习二里,卷积以后feature map 尺寸会变小,如何应用 Residual Learning?
- 在中间再加个卷积层,比如卷积后的尺寸为32321,需要的尺寸为3636n。可以加个卷积核“filter size = 1, padding = 2, stride = 1, D_in = 3232, D_out = 3636”
- 也可以插值,比如插平均值等
-
有什么方法可以进一步提升准确率?
- 改变网络结构,从CNN到VGG,准确率提高了20+%,变化为ResNet网络能达到90+的准确率
- 使用不同的梯度下降算法,比如SGD到Adam,准确率也会上升
- 特征工程和特征转换,还有特征选择,就是对图像进行预处理
- 对缺失值和异常值进行处理,比如有时候平均值法效果好,有时候最大值法效果好
- 虽然奥克姆剃刀法,但是我在第一周实验中感觉激活函数也对准确率的提升有效果
- 多跑几个epoch
总结
emmm还是得看论文,许多博客上讲的东西并不是很清晰。比如LeNet,我一开始以为是LeNet-5,后来发现1989还有一篇。
- 提升准确率的方法感觉并不止这些,希望能在以后的学习中了解
- 希望能进一步提高自己的代码能力,能自主的复现这些论文。















 4726
4726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









