







视频学习+论文阅读
ResNet
ResNet即残差神经网络,他的主要贡献就是提供了一种残差块的思路,解决了神经网络的梯度下降问题和退化问题,使得能够训练很深的网络。
残差块一般分为两种,basic block和bottleneck,上图左边就是basic block,右边是bottle neck。
同时为了使输入输出一致,还有一种block
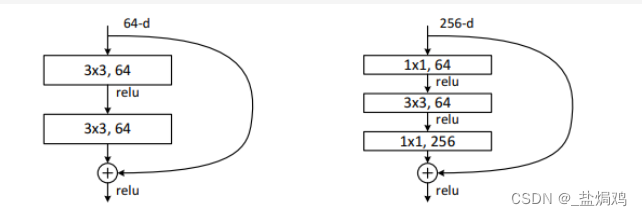
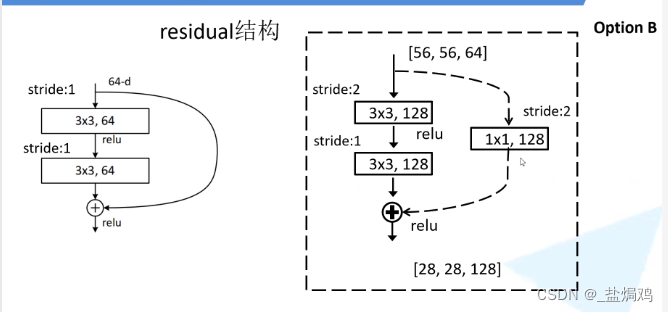
这个虚线即是常说的快速通道
ResNet训练效果好的原因有三个:
- 模型梯度一致很好,很契合SGD的训练
- 内在模型复杂度不高,过拟合没那么严重
- 使用了BN,使得效果更好
ResNext
ResNext我第一遍看下来就是把ResNext中间的那些Resdual block换成了组的形式,采用了group convolution的方法,吸收了VGG和ResNext的优点
!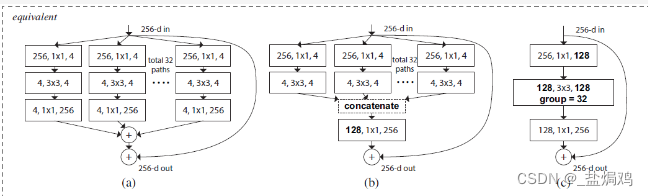
论文中提出了三种Resdual块的等价方式,所以ResNext的网络架构基本上等同于ResNet,只是换了Resdual块。
这种网络结构采用了分组卷积,减少了参数量,所以获得了更好的效果
代码作业
LeNet
引包和数据集的下载
import os
import time
import copy
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from PIL import Image
import json
import shutil
from torch.optim import lr_scheduler
import numpy as np
import matplotlib.pyplot as plt
import torchvision
from torchvision import datasets, models, transforms
下一步挂载谷歌云盘,同时查看一下云盘的文件
#从硬盘里面引包使用
from google.colab import drive
drive.mount('/content/drive/')
path = "/content/drive/"
os.listdir(path)
从网络是下载数据集,并解压,这里我加了个rar的解压包安装。
#网上下载包使用
! wget https://static.leiphone.com/cat_dog.rar
! apt-get install rar
! unrar x cat_dog.rar
测试GPU的可用性
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('gpu : % s' %torch.cuda.is_available())
打标签
由于我使用了ImageFolder去读取,所以文件夹即是标签,因此需要将数据集中的图片存放到各个文件夹中。
src_dir_path = '/content/sample_data/cat_dog/train' # 源文件夹
key= 'dog','cat'
for i in key:
if not os.path.exists(src_dir_path+"/"+i):
print("to_dir_path not exist,so create the dir")
os.mkdir(src_dir_path+"/"+i, 1)
if os.path.exists(src_dir_path):
print("src_dir_path exist"+i)
for file in os.listdir(src_dir_path):
# is file
if os.path.isfile(src_dir_path+'/'+file):
if i in file:
print('找到包含"'+i+'"字符的文件,绝对路径为----->'+src_dir_path+'/'+file)
shutil.move(src_dir_path+'/'+file, src_dir_path+"/"+i+'/'+file)
src_dir_path = '/content/sample_data/cat_dog/val' # 源文件夹
key= 'dog','cat'
for i in key:
if not os.path.exists(src_dir_path+"/"+i):
print("to_dir_path not exist,so create the dir")
os.mkdir(src_dir_path+"/"+i, 1)
if os.path.exists(src_dir_path):
print("src_dir_path exist"+i)
for file in os.listdir(src_dir_path):
# is file
if os.path.isfile(src_dir_path+'/'+file):
if i in file:
print('找到包含"'+i+'"字符的文件,绝对路径为----->'+src_dir_path+'/'+file)
shutil.move(src_dir_path+'/'+file, src_dir_path+"/"+i+'/'+file)
src_dir_path = '/content/sample_data/cat_dog/test' # 源文件夹
to_dir_path = '/content/sample_data/cat_dog/test/catordogs' # 存放复制文件的文件夹
key= 'j' # 源文件夹中的文件包含字符key则复制到to_dir_path文件夹中
if not os.path.exists(to_dir_path):
print("to_dir_path not exist,so create the dir")
os.mkdir(to_dir_path, 1)
if os.path.exists(src_dir_path):
print("src_dir_path exist")
for file in os.listdir(src_dir_path):
# is file
if os.path.isfile(src_dir_path+'/'+file):
if key in file:
print('找到包含"'+key+'"字符的文件,绝对路径为----->'+src_dir_path+'/'+file)
print('复制到----->'+to_dir_path+file)
shutil.move(src_dir_path+'/'+file, to_dir_path+'/'+file)# 移动用move函数
数据处理
这里我设置的图片规格为128,如果要更改可以更改type,设置完成后输出一下
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
type = 128
LeNet_format = transforms.Compose([transforms.Resize((type,type)),
transforms.ToTensor(),
normalize
])
data_dir = './'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), LeNet_format)for x in ['test', 'train', 'val']}
dset_sizes = {x: len(dsets[x]) for x in ['test', 'train', 'val']}
dset_classes = dsets['train'].classes
print(dsets['train'].classes)
print(dsets['train'].class_to_idx)
print(dsets['train'].imgs[:5])
print('dset_sizes: ', dset_sizes)
model
这个leNet我用的是relu,并不算严格的lenet,算是个cnn吧
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.conv3 = nn.Conv2d(16, 32, 4)
self.conv4 = nn.Conv2d(32, 32, 4)
self.conv5 = nn.Conv2d(32, 32, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32, 16)
self.fc2 = nn.Linear(16, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = F.relu(self.conv5(x))
x = x.view(-1, 32)
x = F.relu(self.fc1(x))
x = F.softmax(self.fc2(x), dim=1)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
训练
这个训练我是参照代码练习2的,没啥好说的emmmm
for epoch in range(30): # 重复多轮训练
for i, (inputs, labels) in enumerate(loader_train):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
输出结果
resfile = open('LeNet.csv', 'w')
for i in range(0,2000):
img_PIL = Image.open('./test/catordogs/'+str(i)+'.jpg')
img_tensor = transforms.Compose([transforms.Resize((128,128)),transforms.ToTensor()])(img_PIL)
img_tensor = img_tensor.reshape(-1, img_tensor.shape[0], img_tensor.shape[1], img_tensor.shape[2])
img_tensor = img_tensor.to(device)
out = net(img_tensor).cpu().detach().numpy()
if out[0, 0] < out[0, 1]:
resfile.write(str(i)+','+str(1)+'\n')
else:
resfile.write(str(i)+','+str(0)+'\n')
resfile.close()
结果

ResNet
ResNet的许多代码都是重用LeNet的,所以我这里只写一些区别的地方了。
数据处理
这一块和LeNet有两个区别,一个是裁剪的图片变成了224*224,这是为了符合网络的输入结构;还有一个是batch_size,这个太大会爆显存封号,我这几天掉了几个号了。。。。
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
resnet_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])
data_dir = '/content/sample_data/cat_dog'
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), resnet_format)
for x in ['test','train', 'val']}
dset_sizes = {x: len(dsets[x]) for x in ['test', 'train', 'val']}
dset_classes = dsets['train'].classes
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=32, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['val'], batch_size=5, shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(dsets['test'], batch_size=5, shuffle=False, num_workers=6)
ResNet50/152
这里直接用迁移学习,使用pytorch现成的模型去跑。采用net_0的方法是因为之前有错误,可能是没有实例化?
参数这里试了Adam和SGD,SGD效果比较好。
net = models.resnet152(pretrained=True)
net_0 = net
print(net_0)#看看网络架构
net_0.fc = nn.Linear(2048,2,bias =True)#更改最后一层全连接层,使其满足二分类问题
net_0 =net_0.to(device)
# construct an optimizer
#params = [p for p in net_0.parameters() if p.requires_grad]
#optimizer = optim.Adam(params, lr=0.0001)
train和val
这个主要是根据一个代码的改的,把val的结果用来训练下一个epoch,我又另外加了个学习率的优化。
lr=0.0001
optimizer = torch.optim.SGD(net_0.parameters(), lr=lr, momentum=0.9, weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
val_num = len(dsets['val'])
loss_function = nn.CrossEntropyLoss()
epochs = 3
best_acc = 0.0
train_steps = len(loader_train)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(loader_train, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(loader_valid, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1,
epochs)
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
scheduler.step()
print('Finished Training')
测试
resfile = open('resnet1523.csv', 'w')
for i in range(0,2000):
img_PIL = Image.open('/content/sample_data/cat_dog/test/catordogs/'+str(i)+'.jpg')
img_tensor = transforms.Compose([transforms.Resize(224),transforms.CenterCrop(224),transforms.ToTensor()])(img_PIL)
img_tensor = img_tensor.reshape(-1, img_tensor.shape[0], img_tensor.shape[1], img_tensor.shape[2])
img_tensor = img_tensor.to(device)
out = net(img_tensor).cpu().detach().numpy()
if out[0, 0] < out[0, 1]:
resfile.write(str(i)+','+str(1)+'\n')
else:
resfile.write(str(i)+','+str(0)+'\n')
resfile.close()
结果
原作者的:
我的:
可以看到还是有不小的提升的,通过学习率的更新还是有效果的。
ResNext
也同时试了下resnext
model
这个要先引入权重
from torchvision.models import ResNeXt101_32X8D_Weights
net = models.resnext101_32x8d(weights = ResNeXt101_32X8D_Weights.IMAGENET1K_V1)
net_0 = net
net_0.fc = nn.Linear(2048,2,bias =True)
net_0 = net_0.to(device)
#print(net_0)
结果
epoch=3,batch_size=32。

看到resnext并不如resnet,可能是用的epoch只有三个,batch_size只有16(多了爆显存),或许是输出csv时的代码出了问题。
思考题
- Residual learning
解决的问题:梯度消失和退化问题,即模型的梯度和准确率不会随网络加深而减弱。
主要构成:在浅层网络上加上一些新的网络,这些网络学习
残差只是加了一个x进来,没有改变模型的复杂度。它在梯度上保持的比较好,而且不管加了多少层,前面有用的网络总还是有用的,这样也很适合SGD。
- Batch Normailization 的原理
BN就是一种标准化操作,将batch内的每个特征变为均值为0,方差为1的分布,使其满足网络所需
- 为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
分组卷积能减小参数量,同时可以看成正常卷积的稀疏结构,获得正则的效果。
分组卷积的数据信息只存在本组里面,如果组数太多,各通道之间的信息交互太过困难,这样会影响效果。
- Res2Net是如何利用分组卷积降低计算量,同时提升网络性能的?
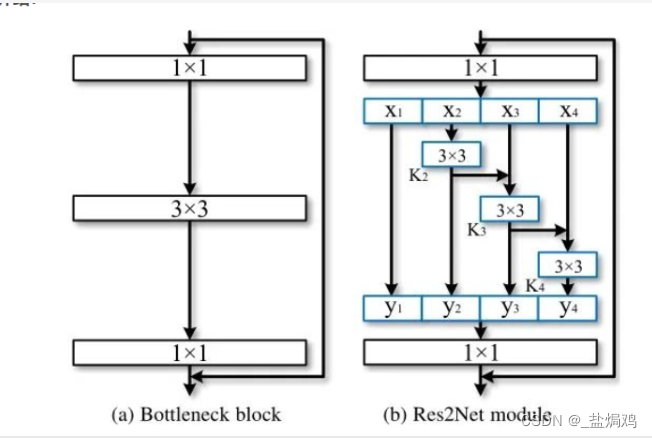
利用这种结构,使得网络的参数更小,感受野能捕捉更多的细节和全局特性
- Vision Transformer 里的 attention,比较 multi-head 和 分组卷积的区别与联系
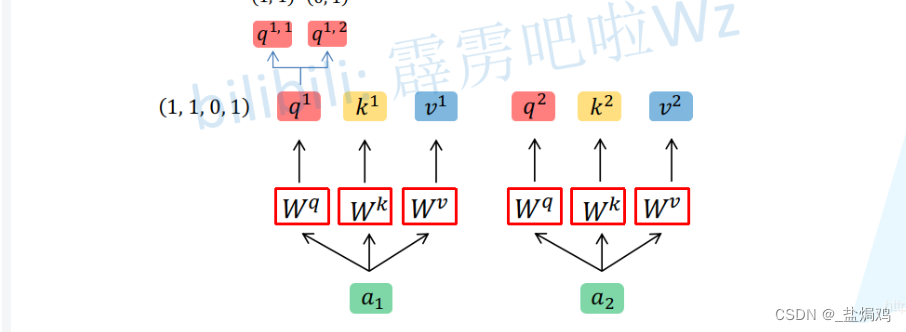
multi-head attention首先是把这个拆分,再采用Self-Attention中相同的方法进行运算,最后再通过融合获取最终结果。
组卷积也可以理解为相同的做法,拆分,对每个组使用resnet中的方法,再合并。
遇到的问题
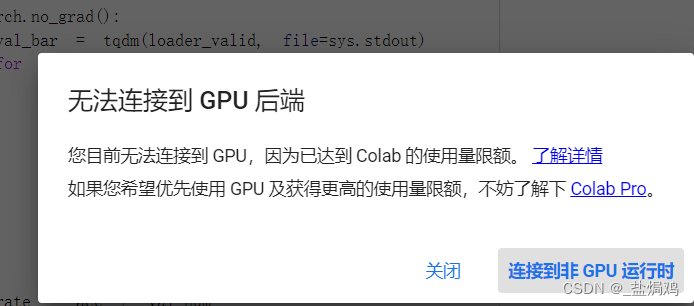
-
colab感觉有点不够用了,我这几天炸了两个号了,全到了gpu限额。而且训练resnext之类的gpu的batch还不能弄多了,多了就爆显存。
-
resnet跑的epoch有点少了,我的colab被炸号了,两个号的资源都用完了,不然多跑几个准确率应该还能提升。
-
resnet效果反而比resnext好?这是因为我用的batch_size太小了么?还是训练轮次不够?不太清楚
-
VIT没太看明白,时间不太够,只是大概看了下,以后再认真了解了















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









