







第4章 处理数值型数据
4.0 简介
讲解将多种原始数值型数据转换成机器学习算法所需特征的方法
百度网盘
链接:https://pan.baidu.com/s/161kOW1Jm5DhglMRYpzJ0NQ
提取码:v4nq
4.1特征的缩放
将数值型特征的值缩放(rescale)到两个特定的值之间
使用scikit-learn的MinMaxScaler进行缩放一个特征数组
MinMaxScaler(将特征值缩放到(0,1)之间)
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
将数值型特征的值缩放到两个特定的值之间
#加载库
import numpy as np
from sklearn import preprocessing
#创建特征
feature = np.array([[-500.5],[-100.1],[0],[100.1],[900.9]])
#创建缩放器
minmax_scale=preprocessing.MinMaxScaler(feature_range=(0,1))
#缩放特征的值
scaled_feature=minmax_scale.fit_transform(feature) #fit 和 transfrom可以分开使用
#查看特征
scaled_feature

scikit-learn的MinMaxScaler支持两种方式来缩放特征。
- 使用fit计算特征的最小值和最大值,然后使用transform来缩放
- 使用fit_transform一次性执行上面说的两个操作
从数学上说,上述两种方式没有区别。但是,有时候将两个操作分开会带来一些好处,因为这样的话我们就能对不同的数据集执行同样的转换。
4.2 特征的标准化
对一个特征进行转换,使其平均值为0,标准差为1(此特征符合标准正态分布)
scikit-learn的standardScaler能完成上述的操作
#加载库
import numpy as np
from sklearn import preprocessing
#创建特征
x=np.array([[-1000.1],[-200.2],[500.5],[600.6],[9000.9]])
#创建缩放器
scaler=preprocessing.StandardScaler()
#转换特征
standardized = scaler.fit_transform(x)
#查看特征
print(standardized)
#查看平均值
print(round(standardized.mean()))
#查看标准差
print(standardized.std())

标准化方法在机器学习数据预处理中常用缩放方法,比min-max缩放用的更多,但是需要使用的时候也需要分情况。例如:在主成分分析中标准化方法更有用,但是在神经网络中则更推荐使用min-max缩放。
如果数据存在很大的异常值,可能会影响特征的平均值和方差,也会对标准差的效果造成不良的影响。在这种情况下,使用中位数和四分位数间距进行缩放会更有效。
此时使用RobustScaler缩放更为有效
#创建缩放器
robust_scaler=preprocessing.RobustScaler()
#转换数据
robust_scaler.fit_transform(x)

4.3 归一化观察值
对观察值的每一个特征进行缩放,使其拥有一致的范数(总长度是1)
使用Normalizer并指定norm参数
#加载库
import numpy as np
from sklearn.preprocessing import Normalizer
#创建特征矩阵
features = np.array([[0.5,0.5],[1.1,3.4],[1.5,20.2],[1.63,34.4],[10.9,3.3]])
#创建归一化器
normalizer=Normalizer(norm="l2")
#转换特征矩阵
normalizer.transform(features)

Normalizer可以对单个观察值进行缩放,使其拥有一致的范数(总长度为1). 当一个观察值有多个相等的特征时(例如,做文本分类时,每一个词或每几个词就是一个特征),经常使用这种类型的缩放。
#Normalizer提供三个范数选项,默认值是欧式范数(L2范数)
#转换特征矩阵
featuers_l2_norm = Normalizer(norm="l2").transform(features)
#查看特征矩阵
featuers_l2_norm

#可以指定曼哈顿范数(L1范数)
features_l1_norm=Normalizer(norm="l1").transform(features)
#查看特征矩阵
print(features_l1_norm)
#使用norm="l1"对一个观察值进行缩放后,它的元素总和为1。
#查看总和
print("Sum:",features_l1_norm[0,0]+features_l1_norm[0,1])

直观的说,L2范数可以被视为纽约两个点之间的距离(也就是直线距离), 而L1范数可以被视为一个人沿着街道行走的距离(向北走一个 街区,向东走一个街区,然后向北走一个街区,再向东走一个街区,等等)
4.4 生成多项式和交互特征
可以选择手动创建多项式特征和交互特征,亦可以使用sklearn中的内置的方法
#加载库
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
#创建特征矩阵
features = np.array([[2,3],[2,3],[2,3]])
#创建PolynomialFeatures对象
polynomial_interaction=PolynomialFeatures(degree=2,include_bias=False)
#创建多项式特征
polynomial_interaction.fit_transform(features)

degree参数决定了多项式的最高阶数。默认情况下PolynomialFeatures包含交互特征:x1x2
通过设置interaction_only为True,可以强制创建出来的特征只包含交互特征
interaction=PolynomialFeatures(degree=2,interaction_only=True,include_bias=False)
interaction.fit_transform(features)

如一个特征需要依赖另一个特征才能对目标值造成影响的情况。例如:一杯咖啡甜不甜不仅受加糖的影响还受是否搅拌的影响。这两个特征是相互依赖的,交互特征可以很好的表示这一点。
4.5 转换特征
对一个或多个特征值进行自定义操作
#加载库
import pandas as pd
import numpy as np
from sklearn.preprocessing import FunctionTransformer
#创建特征矩阵
featurn = np.array([[2,3],[2,3],[2,3]])
#定义一个简单的函数
def add_ten(x):
return x+10
#创建转换器
ten_transformer = FunctionTransformer(add_ten)
#转换特征矩阵
ten_transformer.transform(featurn)

#在pandas中可以使用apply进行同样的转换
#加载库
import pandas as pd
#创建数据帧
df = pd.DataFrame(featurn,columns=("featurn_1","featurn_2"))
#应用函数
df.apply(add_ten)

转换特征时,如果利用一个特征表示另一个特征时,可以创建一个函数,并使用FunctionTransFormer或pandas中apply运用该函数
4.6 识别异常值
识别异常值常用的方法是标准正态分布。基于这个假设,在数据周围画圆,将所有处于椭圆内的值视为正常值
#加载库
import pandas as pd
from sklearn.covariance import EllipticEnvelope
from sklearn.datasets import make_blobs
#创建模拟数据
features,_=make_blobs(n_samples=10,n_features=2,centers=1,random_state=1)
#将第一个观察值的值替换为极端值
features[0,0]=10000
features[0,1]=10000
#创建识别器
outlier_detector=EllipticEnvelope(contamination=.1)
#拟合识别器
outlier_detector.fit(features)
#预测异常值
outlier_detector.predict(features)```
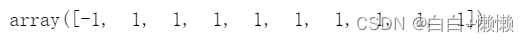
参数contamination是一个污染指数即一个清洁程度。如果想要数据包含较少的异常值可以将contamination设置小一些
```python
#除了查看所有的观察值,还可以只查看某些特征,使用四分误差来识别这些特征的极端值。
#创建一个特征
feature = features[:,0]
#创建一个函数来返回异常值的下标
def indicies_of_outliers(x):
q1,q3=np.percentile(x,[25,75])
iqr =q3-q1
lower_bound=q1-(iqr*1.5)
upper_bound=q3+(iqr*1.5)
return np.where((x>upper_bound)|(x<lower_bound))
#执行函数
indicies_of_outliers(feature)
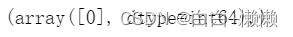
4.7 处理异常值
处理异常值一般有三种方法:直接丢弃,标记异常,转换异常值
#丢弃异常值
#加载库
import pandas as pd
#创建数据帧
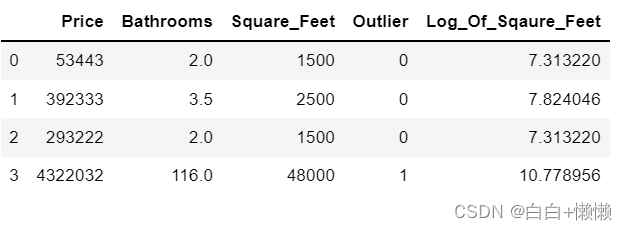
houses =pd.DataFrame()
houses['Price']=[53443,392333,293222,4322032]
houses['Bathrooms']=[2,3.5,2,116]
houses['Square_Feet']=[1500,2500,1500,48000]
#筛选观察值
houses[houses['Bathrooms']<20]
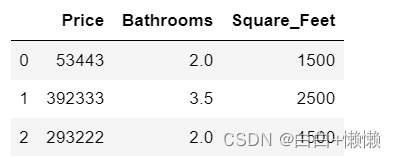
#标记异常值
#加载库
import pandas as pd
import numpy as np
#基于布尔条件语句来创建特征
houses["Outlier"]=np.where(houses["Bathrooms"]<20,0,1) #异常值标记为1
#查看数据
houses
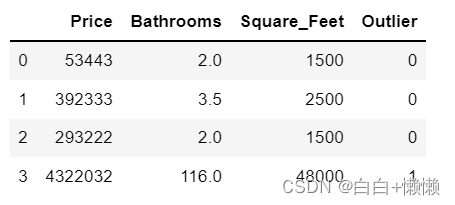
#对有异常值的特征取对数,降低异常值的影响
#对特征值取对数
houses["Log_Of_Sqaure_Feet"]=[np.log(x) for x in houses["Square_Feet"]]
#查看数据
houses
4.8 将特征离散化
如果有足够的理由认为某个数值型特征应该被视为一个分类特征,那么可以对特征进行离散化
有两种方法:一种根据与之将特征二值化;根据多个阈值将数值型特征离散化
#二值化
#加载库
import numpy as np
from sklearn.preprocessing import Binarizer
#创建特征
age=np.array([[6],[12],[20],[36],[65]])
#创建二值化器
binarizer = Binarizer(20)
#转换特征
binarizer.fit_transform(age)

#根据多个阈值将数值型特征进行分类
#将特征离散化
np.digitize(age,bins=[20,30,64]) #bins参数中的每个数字表示的是每个区间的左边界(左闭右开),可以通过设置right参数为True来改变
#只指定一个阈值,digitize可以像Binarizer一样进行二值化
#np.digitize(age,bins=[20])

4.9 使用聚类的方式将观察值分组
数据预处理中可以使用聚类
#加载库
import pandas as pd
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
#创建模拟的特征矩阵
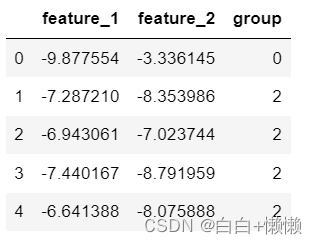
features,_ =make_blobs(n_samples=50,n_features=2,centers=3,random_state=1)
#创建数据帧
dataframe = pd.DataFrame(features,columns=["feature_1","feature_2"])
#创建K-Means聚类器
clusterer = KMeans(3,random_state=0)
#将聚类器应用在特征上
clusterer.fit(features)
#预测聚类的值
dataframe["group"]=clusterer.predict(features)
#查看前几个观察值
dataframe.head(5)
4.10 删除带有缺失值的观察值
删除带有缺失值的观察值(使用numpy代码可以进行删除)
#加载库
import numpy as np
#创建特征矩阵
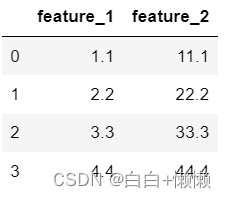
features = np.array([[1.1,11.1],[2.2,22.2],[3.3,33.3],[4.4,44.4],[np.nan,55]])
#只保留没有缺失值的观察值
features[~np.isnan(features).any(axis=1)]

#或者使用pandas丢弃有缺失值的观察值
#加载库
import pandas as pd
#加载数据
dataframe=pd.DataFrame(features,columns=["feature_1","feature_2"])
#删除带有缺失值的观察值
dataframe.dropna()
删除观察值是一种不得已的选择。删除观察值可能会引起误差,误差主要是由于缺失值的成因所决定。
缺失值一共有三种类型:
(1)完全随机缺失 数据缺失的可能性与其他任何东西都无关。
(2)随机缺失 数据缺失的可能性不是完全随机的,与已经存在的其他特征有关
(3)完全非随机缺失 数据缺失的可能性完全是非随机的。
4.11 填充缺失值
如果数据中存在缺失值,我们希望填充或者预测这些缺失值而不是直接进行删除
#如果数据量不大,可以使用KNN(K近邻)算法进行预测
#加载库
import numpy as np
from fancyimpute import KNN
from sklearn.preprocessing import StandaerScaler
from sklearn.datasets import make_blobs
#创建模拟特征矩阵
features,_=make_blobs(n_samples=1000,n_features=2,random_state=1)
#标准化特征
scaler =StandardScaler()
standardized_features=scaler.fit_transform(features)
#将第一个特征向量的第一个值替换为缺失值
true_value=standardized_features[0,0]
standardized_features[0,0]=np.nan
#预测特征矩阵中的缺失值
features_knn_imputed=KNN(k=5,verbose=0).complete(standardized_features)
#对比真实值与填充值
print("True:",true_value)
print("predict:",features_knn_imputed[0,0])
#还可以使用sklearn中的Imputer模块,利用特征的平均值、中位数、众数来填充缺失值
#加载库
from sklearn.preprocessing import Imputer
#创建填充器
mean_imputer =Imputer(strategy="mean",axis=0)
#填充缺失值
features_mean_imputer = mean_imputer.fit_transform(features)
#对比真实值和填充值
print("True:",true_value)
pritn("Imputer:",features_mean_imputer)
收工!!!














 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









